Article Content
Abstract
Reformulating initial bug reports to obtain better queries for buggy code retrieval is an important research direction in the bug localization area. Existing query reformulation strategies of bug reports are generally unsupervised and may lack localization guidance, which prevents the generation of better queries for bug localization. Towards this, we propose to develop KBL, a golden keywords-based query reformulation approach for bug localization. Specifically, we first leverage the genetic algorithm and keywords refinement heuristic rules to build a golden keywords benchmark targeted at bug localization. Taking this benchmark as bug localization guidance, we create a keywords classifier for bug reports based on three categories of semantic features. The extracted keywords by the classifier for a bug report are taken as the reformulated start point upon which noise removal and shared keyword expansion with historical bug reports are further performed. The final achieved query, as a replacement for the original bug report, is expected to enhance buggy code retrieval performance. Our experiments show that the contributed keywords benchmark is of high quality in locating bugs, establishing a good basis for further query reformulation to improve localization techniques. Through an analysis of different classifier choices, data balancing strategies, and feature importance, we validate the suitability of the configuration settings for our keyword classifier. A testing dataset of 4,484 bug reports from six projects is used to evaluate our KBL. The results show that KBL is found to substantially outperform both the typical (with a relatively 8%-85% higher Acc@10, 9%-93% higher MAP, and 10%-94% higher MRR), and state-of-the-art (with a relatively 21%-45% higher Acc@10, 31%-47% higher MAP and 32%-50% higher MRR) reformulation strategies. Moreover, based on the reformulated queries of our KBL, the performance of seven representative information retrieval-based bug localization techniques also showed recognizable improvements, including relative increases of 8%-36% in Acc@1, 6%-32% in Acc@5, 4%-24% in Acc@10, 4%-21% in Acc@20, 10%-33% in MAP, and 8%-25% in MRR.
Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.
- Algorithms
- Categorization
- Data Structures
- Replisome
- Reverse engineering
- Targeted resequencing
Data Availibility
The datasets and code scripts for replication are available in the KBL repository(https://github.com/Caiby0927/KBL).
Notes
-
https://bugzilla.mozilla.org/home
-
https://bugs.eclipse.org/bugs/show_bug.cgi?id=397842
-
http://www.nltk.org/howto/wordnet.html
-
https://spacy.io/
-
https://github.com/microsoft/LightGBM
-
https://lucene.apache.org/
-
http://www.nltk.org/api/nltk.stem.html
-
http://jmetal.sourceforge.net
-
https://github.com/TruX-DTF/d-and-c
-
https://github.com/Caiby0927/KBL
-
https://github.com/Caiby0927/KBL
References
-
Bettenburg N, Just S, Schröter A, Weiss C, Premraj R, Zimmermann T (2008) What makes a good bug report? In: Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of software engineering, pp 308–318
-
Blei DM, Ng AY, Jordan MI (2003) Latent dirichlet allocation. J Mach Learn Res 3(Jan):993–1022
-
Carpineto C, Romano G (2012) A survey of automatic query expansion in information retrieval. Acm Comput Surv (CSUR) 44(1):1–50
-
Chaparro O, Marcus A (2016) On the reduction of verbose queries in text retrieval based software maintenance. In: Proceedings of the 38th International Conference on Software Engineering Companion, Association for Computing Machinery, New York, NY, USA, ICSE ’16, p 716–718, https://doi.org/10.1145/2889160.2892647
-
Chaparro O, Florez JM, Marcus A (2017) Using observed behavior to reformulate queries during text retrieval-based bug localization. In: 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), pp 376–387, https://doi.org/10.1109/ICSME.2017.100
-
Chaparro O, Florez JM, Marcus A (2019) Using bug descriptions to reformulate queries during text-retrieval-based bug localization. Empir Softw Eng 24:2947–3007
-
Chen B, Zou W, Cai B, Meng Q, Liu W, Li P, Chen L (2024) An empirical study on the potential of word embedding techniques in bug report management tasks. Empir Softw Eng 29(5):122
-
Church KW (2017) Word2vec. Natural Language Eng 23(1):155–162
-
Dallmeier V, Zimmermann T (2007) Extraction of bug localization benchmarks from history. In: Proceedings of the 22nd IEEE/ACM international conference on automated software engineering, pp 433–436
-
Deerwester S, Dumais ST, Furnas GW, Landauer TK, Harshman R (1990) Indexing by latent semantic analysis. J American Soc Inf Sci 41(6):391–407
-
Florez JM, Chaparro O, Treude C, Marcus A (2021) Combining query reduction and expansion for text-retrieval-based bug localization. In: 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), pp 166–176, https://doi.org/10.1109/SANER50967.2021.00024
-
Gay G, Haiduc S, Marcus A, Menzies T (2009) On the use of relevance feedback in ir-based concept location. In: 2009 IEEE International Conference on Software Maintenance, pp 351–360, https://doi.org/10.1109/ICSM.2009.5306315
-
Haiduc S, Bavota G, Marcus A, Oliveto R, De Lucia A, Menzies T (2013) Automatic query reformulations for text retrieval in software engineering. In: 2013 35th International Conference on Software Engineering (ICSE), pp 842–851. https://doi.org/10.1109/ICSE.2013.6606630
-
Huo X, Thung F, Li M, Lo D, Shi ST (2019) Deep transfer bug localization. IEEE Trans Softw Eng 47(7):1368–1380
-
Jones JA, Harrold MJ (2005) Empirical evaluation of the tarantula automatic fault-localization technique. In: Proceedings of the 20th IEEE/ACM International Conference on Automated Software Engineering, Association for Computing Machinery, New York, NY, USA, ASE ’05, p 273–282. https://doi.org/10.1145/1101908.1101949
-
Kevic K, Fritz T (2014) Automatic search term identification for change tasks. In: Companion Proceedings of the 36th International Conference on Software Engineering, Association for Computing Machinery, New York, NY, USA, ICSE Companion 2014, p 468–471. https://doi.org/10.1145/2591062.2591117
-
Kim D, Tao Y, Kim S, Zeller A (2013) Where should we fix this bug? a two-phase recommendation model. IEEE Trans Softw Eng 39(11):1597–1610
-
Kim IY, De Weck O (2005) Variable chromosome length genetic algorithm for progressive refinement in topology optimization. Struct Multidiscip Optimiz 29:445–456
-
Kim M, Lee E (2019a) A novel approach to automatic query reformulation for ir-based bug localization. In: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Association for Computing Machinery, New York, NY, USA, SAC ’19, p 1752–1759. https://doi.org/10.1145/3297280.3297451
-
Kim M, Lee E (2019b) A novel approach to automatic query reformulation for ir-based bug localization. In: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Association for Computing Machinery, New York, NY, USA, SAC ’19, p 1752–1759, https://doi.org/10.1145/3297280.3297451
-
Kim M, Kim Y, Lee E (2021) A novel automatic query expansion with word embedding for ir-based bug localization. In: 2021 IEEE 32nd International Symposium on Software Reliability Engineering (ISSRE), IEEE, pp 276–287
-
Kochhar PS, Tian Y, Lo D (2014) Potential biases in bug localization: Do they matter? In: Proceedings of the 29th ACM/IEEE international conference on Automated software engineering, pp 803–814
-
Kong A, Zhao S, Chen H, Li Q, Qin Y, Sun R, Bai X (2023) Promptrank: Unsupervised keyphrase extraction using prompt. arXiv:2305.04490
-
Koyuncu A, Bissyandé TF, Kim D, Liu K, Klein J, Monperrus M, Traon YL (2019) D &c: A divide-and-conquer approach to ir-based bug localization. CoRR arXiv:1902.02703
-
Krejcie R (1970) Determining sample size for research activities. Education Psychol Meas
-
Lam AN, Nguyen AT, Nguyen HA, Nguyen TN (2017) Bug localization with combination of deep learning and information retrieval. In: 2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC), IEEE, pp 218–229
-
Laurikkala J (2001) Improving identification of difficult small classes by balancing class distribution. In: Artificial Intelligence in Medicine: 8th Conference on Artificial Intelligence in Medicine in Europe, AIME 2001 Cascais, Portugal, July 1–4, 2001, Proceedings 8, Springer, pp 63–66
-
Le TDB, Oentaryo RJ, Lo D (2015) Information retrieval and spectrum based bug localization: Better together. In: Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, pp 579–590
-
Lee J, Kim D, Bissyandé TF, Jung W, Le Traon Y (2018) Bench4bl: Reproducibility study on the performance of ir-based bug localization. In: Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Association for Computing Machinery, New York, NY, USA, ISSTA 2018, p 61–72. https://doi.org/10.1145/3213846.3213856
-
Li Z, Jiang Z, Chen X, Cao K, Gu Q (2021) Laprob: a label propagation-based software bug localization method. Inf Softw Technol 130:106410
-
Lukins SK, Kraft NA, Etzkorn LH (2008) Source code retrieval for bug localization using latent dirichlet allocation. In: 2008 15th Working Conference on Reverse Engineering, pp 155–164. https://doi.org/10.1109/WCRE.2008.33
-
Luo Z, Wang W, Caichun C (2023) Improving bug localization with effective contrastive learning representation. IEEE Access 11:32523–32533. https://doi.org/10.1109/ACCESS.2022.3228802
-
Macbeth G, Razumiejczyk E, Ledesma RD (2011) Cliff’s delta calculator: A non-parametric effect size program for two groups of observations. Universitas Psych 10(2):545–555
-
Mann HB, Whitney DR (1947) On a test of whether one of two random variables is stochastically larger than the other. The Annal Math Stat pp 50–60
-
Mihalcea R, Tarau P (2004) Textrank: Bringing order into text. In: Proceedings of the 2004 conference on empirical methods in natural language processing, pp 404–411
-
Mills C, Parra E, Pantiuchina J, Bavota G, Haiduc S (2020) On the relationship between bug reports and queries for text retrieval-based bug localization. Empir Softw Eng 25:3086–3127
-
Moreno L, Treadway JJ, Marcus A, Shen W (2014) On the use of stack traces to improve text retrieval-based bug localization. In: 2014 IEEE International Conference on Software Maintenance and Evolution, pp 151–160. https://doi.org/10.1109/ICSME.2014.37
-
Moreno L, Bavota G, Haiduc S, Di Penta M, Oliveto R, Russo B, Marcus A (2015) Query-based configuration of text retrieval solutions for software engineering tasks. In: Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Association for Computing Machinery, New York, NY, USA, ESEC/FSE 2015, p 567–578. https://doi.org/10.1145/2786805.2786859
-
Rahman MM, Roy CK (2017) Strict: Information retrieval based search term identification for concept location. In: 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), pp 79–90. https://doi.org/10.1109/SANER.2017.7884611
-
Rahman MM, Roy CK (2018a) Improving bug localization with report quality dynamics and query reformulation. In: Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, Association for Computing Machinery, New York, NY, USA, ICSE ’18, p 348–349. https://doi.org/10.1145/3183440.3195003
-
Rahman MM, Roy CK (2018) Improving ir-based bug localization with context-aware query reformulation. Ass Comput Mach, New York, NY, USA, ESEC/FSE 2018:621–632. https://doi.org/10.1145/3236024.3236065
-
Rahman MM, Khomh F, Yeasmin S, Roy CK (2021) The forgotten role of search queries in ir-based bug localization: an empirical study. Empir Softw Eng 26(6):116
-
Rao S, Kak A (2011) Retrieval from software libraries for bug localization: A comparative study of generic and composite text models. In: Proceedings of the 8th Working Conference on Mining Software Repositories, Association for Computing Machinery, New York, NY, USA, MSR ’11, p 43–52. https://doi.org/10.1145/1985441.1985451
-
Roldan-Vega M, Mallet G, Hill E, Fails JA (2013) Conquer: A tool for nl-based query refinement and contextualizing code search results. In: 2013 IEEE International Conference on Software Maintenance, IEEE, pp 512–515
-
Saha RK, Lease M, Khurshid S, Perry DE (2013) Improving bug localization using structured information retrieval. In: 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp 345–355. https://doi.org/10.1109/ASE.2013.6693093
-
Sampson JR (1976) Adaptation in natural and artificial systems (john h. holland)
-
Seiffert C, Khoshgoftaar TM, Van Hulse J, Napolitano A (2009) Rusboost: A hybrid approach to alleviating class imbalance. IEEE Trans Syst, Man, Cybern-Part A: Syst Humans 40(1):185–197
-
Shao S, Yu T (2023) Information retrieval-based fault localization for concurrent programs. In: 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp 1467–1479. https://doi.org/10.1109/ASE56229.2023.00122
-
Shi X, Xu G, Shen F, Zhao J (2015) Solving the data imbalance problem of p300 detection via random under-sampling bagging svms. In: 2015 International Joint Conference on Neural Networks (IJCNN), pp 1–5. https://doi.org/10.1109/IJCNN.2015.7280834
-
Sisman B, Kak AC (2012) Incorporating version histories in information retrieval based bug localization. In: 2012 9th IEEE working conference on mining software repositories (MSR), IEEE, pp 50–59
-
Sisman B, Kak AC (2013) Assisting code search with automatic query reformulation for bug localization. In: 2013 10th Working Conference on Mining Software Repositories (MSR), pp 309–318. https://doi.org/10.1109/MSR.2013.6624044
-
Tomek I (1976) Two modifications of cnn. In: IEEE Transactions on Systems Man & Cybernetics, https://doi.org/10.1109/TSMC.1976.4309452
-
Wang S, Lo D (2014) Version history, similar report, and structure: Putting them together for improved bug localization. In: Proceedings of the 22nd International Conference on Program Comprehension, Association for Computing Machinery, New York, NY, USA, ICPC 2014, p 53–63. https://doi.org/10.1145/2597008.2597148
-
Wang S, Lo D (2016) Amalgam+: Composing rich information sources for accurate bug localization. J Softw: Evol Process 28(10):921–942
-
Wen M, Wu R, Cheung SC (2016) Locus: Locating bugs from software changes. In: Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, pp 262–273
-
Wong CP, Xiong Y, Zhang H, Hao D, Zhang L, Mei H (2014) Boosting bug-report-oriented fault localization with segmentation and stack-trace analysis. In: 2014 IEEE international conference on software maintenance and evolution, IEEE, pp 181–190
-
Xiao X, Xiao R, Li Q, Lv J, Cui S, Liu Q (2023) Bugradar: Bug localization by knowledge graph link prediction. Inf Softw Technol p 107274
-
Xiao Y, Keung J, Mi Q, Bennin KE (2017) Improving bug localization with an enhanced convolutional neural network. In: 2017 24th Asia-Pacific Software Engineering Conference (APSEC), IEEE, pp 338–347
-
Yan M, Xia X, Fan Y, Hassan AE, Lo D, Li S (2020) Just-in-time defect identification and localization: A two-phase framework. IEEE Trans Softw Eng 48(1):82–101
-
Ye X, Bunescu R, Liu C (2014) Learning to rank relevant files for bug reports using domain knowledge. In: Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Association for Computing Machinery, New York, NY, USA, FSE 2014, p 689–699. https://doi.org/10.1145/2635868.2635874
-
Ye X, Shen H, Ma X, Bunescu R, Liu C (2016) From word embeddings to document similarities for improved information retrieval in software engineering. In: Proceedings of the 38th international conference on software engineering, pp 404–415
-
Yoo S, Xie X, Kuo FC, Chen TY, Harman M (2017) Human competitiveness of genetic programming in spectrum-based fault localisation: Theoretical and empirical analysis. ACM Trans Softw Eng Method 26(1). https://doi.org/10.1145/3078840
-
Youm KC, Ahn J, Kim J, Lee E (2015) Bug localization based on code change histories and bug reports. In: 2015 Asia-Pacific Software Engineering Conference (APSEC), IEEE, pp 190–197
-
Zhou J, Zhang H, Lo D (2012) Where should the bugs be fixed? more accurate information retrieval-based bug localization based on bug reports. In: 2012 34th International conference on software engineering (ICSE), IEEE, pp 14–24
Funding
This work is supported by the National Natural Science Foundation of China (No.62002161, 62272225), partly supported by Key Laboratory of Safety-Critical Software (Nanjing University of Aeronautics and Astronautics), Ministry of Industry and Information Technology (Grant No. 56XCA2002605), the Open Project Foundation of State Key Lab. for Novel Software Technology, Nanjing University (Grant No. KFKT2024B35), and Collaborative Innovation Center of Novel Software Technology and Industrialization.
Ethics declarations
Conflicts of interest
The authors declare no conflict of interest.
Ethical Approval
Ethical approval not applicable.
Informed Consent
Informed consent not applicable.
Clinical Trial Number
Clinical Trial Number not applicable.
Additional information
Communicated by: Bram Adams.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Appendix
A Appendix
1.1 A.1 Confusion Matrices of Keywords Classifier Over Six Projects
Tables 29, 30, 31, 32, 33, and 34, present the detailed confusion matrices of keywords classifier for the six experimental projects.
1.2 A.2 Time Cost of Extracting Features for Bug Reports
To better understand the practical use of our KBL, we also investigate the time required to extract term features from bug reports (required by keywords classifier). The experiment is conducted on a Windows-based machine equipped with an Intel i5-12600KF CPU and 64GB of RAM. Following the sampling strategy in Krejcie (1970), which ensures representativeness and reliability with a 95% confidence level and a 5% margin of error, we randomly sampled 384 bug reports from six projects (with an average length of 124.3 terms). We record the total feature extraction time for each report as well as the number of terms in each report. Our results show that the average time per term is approximately 0.4964 seconds. For a bug report containing around 100 terms, feature extraction would thus take roughly 49.64 seconds. In our experimental setup, the 61 features are calculated sequentially for each report, with each feature computation starting only after the previous one is completed. However, using distributed or parallel computing could significantly reduce the time cost, greatly enhancing the practical usability of our KBL. To better illustrate time distribution, we’ve included box plots depicting the time cost for these 384 bug reports in Fig. 5.
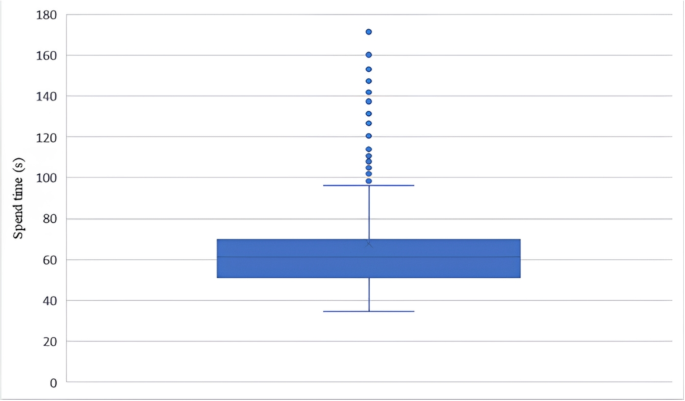
The time cost distribution of feature extraction for sampled 384 bug reports
1.3 A.3 Performance Comparison Between Doing RUS Ten Times and Once
During keyword classifier building, we set a fixed sampling seed of 1,391 for RUS and applied RUS only once. To mitigate any potential biases introduced by RUS, we also repeat the RUS process 10 times without setting a sampling seed and average the experimental results. Table 35 shows their performance differences in terms of F1 score of keywords classifier and the final obtained Acc@K, MAP and MRR bug locating performance. From the table, we only find a slight performance difference. This indicates that the findings of our study are not significantly impacted by whether RUS is performed once or multiple times.
1.4 A.4 Query Reformulation With or Without Keyword Expansion or Low-Quality Term Removal
The query reformulation module of KBL default applies keyword expansion and low-quality term removal to an initial query output by the keywords classifier. To understand the impact of these two reformulation strategies, we built two variants of the query reformulation module. They are as follows: (1) without expansion: in this variant, shared keywords are not used for expanding and augmenting a query. (2) without noise removal: in this variant, the low-quality term is not removed, and only performs the shared keywords expansion. After we obtain the corresponding queries for the above reformulation variants, we use them to retrieve buggy code files and do further results comparison. Table 36 shows the results. It reveals that the model KBL with both steps (i.e., applying shared keywords expansion and noise removal) demonstrates superior performance in bug localization compared to the two variants (i.e., without expansion, and without noise removal). We can observe that the performance of both variants decreases to some extent compared to KBL. Among them, the without expansion variant experiences a smaller decrease compared to KBL, with a relative decrease of 1% in acc@1 metric. On the other hand, the without noise removal variant shows a relatively larger decrease, with a 6% relative decrease in acc@1 metric.
1.5 A.5 The Settings of Similarity Threshold and Repetition Time
Similarity threshold is a key parameter used to filter similar historical bug reports for constructing shared keywords. We test four candidate values for the parameter similarity threshold: (0.6, 0.7, 0.8, 0.9). Repetition time is another key parameter used to limit the maximum number of occurrences of the same term in a query (belonging to the noise removal part). We test five value settings, i.e., (1, 2, 3, 4, 5) for this parameter. To better understand the individual impact of each parameter on localization performance, we assess how performance changes when adjusting each parameter independently. Specifically, when testing Similarity threshold, we vary its value from 0.6 to 0.9 in increments of 0.1, while keeping repetition time fixed at 4 (the optimal value in determined in our analysis). Similarly, when testing repetition time, we vary its value from 1 to 5 in increments of 1, with the Similarity threshold fixed at 0.6 (also identified as the optimal value). Table 37 and 38 present the localization performance of KBL under different settings for similarity threshold and repetition time, respectively.
From Table 37, we see that when the similarity threshold parameter increases from 0.6 to 0.9, the acc@1, acc@5, acc@10 and acc@20 metrics of the queries show a generally decreasing trend. For example, as the similarity threshold value increases from 0.6 to 0.9, the accuracy@10 metric for KBL decreases from 54.10% to 53.67%, and the number of successfully localized bugs decreases from 2426 to 2407. Meanwhile, we can also observe that the performance decrease is quite small when the similarity threshold is increased. This means KBL demonstrates a certain level of robustness to variations in the similarity threshold parameter (when set >=0.6).
From Table 38, we can observe that as the repetition time increases, the query performance initially improves and then declines. When the repetition time reaches 4, the query performance is optimal, while it is worst when the repetition time is 1. Compared to the optimal repetition time, queries with a repetition time of 1 experience a relatively 7% decrease in the acc@1 metric. This indicates that the query performance is sensitive to the repetition time of keywords, which however is not taken into consideration by TextRank and BLIZZARD.
1.6 A.6 The Performance of Applying Golden Keywords Beyond Bug Localization Tasks
In this study, with the aim of providing good localization guidance for bug localization tasks, we constructed a golden keywords dataset based on historical bug-locating data and used it to build a keyword classifier to retrieve bug-revealing keywords. The experimental results have demonstrated the effectiveness of our extracted keywords in facilitating bug localization performance. To understand whether the benefits of golden keywords extend beyond bug localization, we extended our evaluation to another four bug report management tasks, including bug severity prediction, bug priority prediction, bug reopen prediction, and bug field reassignment prediction. The four tasks are generally resolved as a classification problem that mainly involves the content analysis of bug reports.
We followed the strategy of Chen et al. (2024) to label each bug report. Then, we randomly selected 80% of the bug reports as the training dataset, while the remaining 20% were reserved as the test dataset. Table 39 shows the number of instances belonging to different classes in the four tasks. From the table, we could observe a notable class imbalance problem across the training datasets (i.e., some classes have many more instances than others). Such imbalance may make the built model biased towards the majority classes during prediction. Toward this, we designed a data augmentation strategy centered on synonym replacement to fix the class imbalance problem, which proved to help achieve better classification performance than purely using traditional balancing strategies, e.g., random under or over-sampling, in our preliminary experiments.
Specifically, we generated additional instances by randomly selecting existing instances from the minority class and replacing 50% of their tokens with synonyms. This synonym replacement was facilitated using the BERT model fine-tuned on the original bug reports, with stopwords and standard keywords excluded from the replacement process. The augmentation process continues until the number of minority class instances triples its original size. If the expanded minority class still has fewer instances than the majority class, random undersampling (RUS) is applied to the majority class to achieve balance. Conversely, if the minority class surpasses the majority class in size after augmentation, additional instances for the majority class instances will be generated through synonym replacements until both classes are equal in size. Table 40 shows the instance distribution after balancing. Note that we only performed class balancing on the training dataset while keeping the testing dataset imbalanced to mimic real-world scenarios.
After the class labeling and balancing process, we applied the vector space model with tf-idf term weighting to represent the original content of bug reports and their corresponding golden keywords. Then, we trained random forest models based on the constructed datasets to perform predictions separately. Table 41 shows the classification performance for four studied tasks related to using the original bug reports and golden keywords. From the table, we can find that, when compared to models trained on the original contents of bug reports, using golden keywords did not lead to better classification performance but a slight performance decline across the four studied tasks beyond bug localization. This also provides some support for our claim that providing supervised locating guidance is necessary for facilitating bug localization; our construction and further leveraging of golden keywords is such an attempt in this direction.
1.7 A.7 Replacing Word2Vec with BERT During Keyword Classifier Building
In the keyword-classifier building step, we have several instance features involving semantic similarity calculation based on semantic vectors generated by the typical Word2Vec that was trained on bug reports. To explore whether the use of more advanced embedding techniques would lead to better keyword classification performance, we tried to replace Word2Vec with BERT during instance feature extraction. Like Word2Vec, we also fine-tuned BERT with bug reports (using its built-in masked language modeling task). Table 42 presents the corresponding keyword classification performance for using Word2Vec and BERT, respectively. From the table, we can find that the F1 scores are almost the same. In other words, replacing Word2Vec with BERT does not lead to a substantial improvement in the classification performance of our keyword classifier. This may be because the number of features computed using the word embedding technique during feature extraction is relatively small; these features themselves did not play a dominant role in keyword classification (which could also, to some extent, be revealed by our feature importance analysis in Section 5.2).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Cite this article
Cai, B., Zou, W., Meng, Q. et al. KBL: a golden keywords-based query reformulation approach for bug localization. Empir Software Eng 30, 135 (2025). https://doi.org/10.1007/s10664-025-10694-2
- Accepted
- Published
- DOI https://doi.org/10.1007/s10664-025-10694-2
Keywords
- Bug report
- Query reformulation
- Golden keywords
- Bug localization