Article Content
Abstract
Corrective questions exploit focalization to correct and replace a preceding question much like corrective statements exploit focalization to correct and replace a preceding statement. This paper examines Italian corrective questions in depth, presenting new experimental data supporting their grammatical status. It also shows that Italian corrective questions constitute root interrogative clauses, lack a terminal rise, and qualify as canonical questions when assessed with respect to Farkas’ criteria (Farkas 2022). Corrective questions are theoretically significant because they simultaneously contain a wh-phrase and a corrective focus in a root clause. Their grammaticality challenges the widely held hypothesis that wh-phrases and corrective foci must both be interpreted in a left-peripheral FocP projection that can only hosts one or the other. This hypothesis incorrectly predicts corrective questions to be impossible. I will argue, instead, that corrective foci can be interpreted in-situ, and that focalization à la Rooth (1992) and contrast à la Neeleman and Vermeulen (2012) naturally extend to corrective questions and straightforwardly account for their interpretation and corrective import. The paper also examines focus fronting, discussing the object / non-object divide that emerges from the experimental data and showing that non-object corrective foci may front even when a wh-phrase is present.
Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.
- Discourse
- Interpreting
- Italian
- Linguistics
- Syntax
- Theoretical Linguistics / Grammar
1 Introduction
This paper examines corrective questions in Italian, i.e. questions that correct and replace a preceding question and that realize this conversational move by correctively focalizing one of their constituents. Under current assumptions, corrective questions should not exist, because they simultaneously host within the same root interrogative clause a wh-phrase and a corrective focus that are maintained to compete for the same left-peripheral specFocP position. This paper presents an experimental study involving 30 participants and 900 data points that refutes this prediction. It then uses these experimental data and additional evidence to argue that in-situ corrective foci are interpreted in-situ.
An example of a corrective question in English is provided below. Imagine that two parents worry about their teenage son not sleeping enough and suspect that last night he slept very little. When they finally meet him in the morning, the father tries to gather information by asking him when he came home. The mother, who knows that their son does not necessarily go to sleep even once at home, corrects the father by asking a more precise question that replaces the VP come home in the father’s question with the VP go to sleep. By correctively focalizing go to sleep through emphatic stress, the mother signals that her question corrects and replaces the father’s one and it is now the question the son is expected to answer, and, indeed, the son’s answer is interpreted as an answer to the mother’s question, not the father’s. As is typical of corrective questions, the mother’s question lacks a terminal rise, a prosody here temporarily conveyed through an exclamation mark (a more appropriate typographical representation is provided in §2).
- (1)Father: When did you come home?Mother: When did you go to SLEEP!
Son: At three a.m.
To the best of my knowledge, corrective questions have not yet been as systematically investigated as they are here.Footnote1 Syntactically, Italian corrective questions will be shown to constitute root interrogative clauses. Semantically, they will be shown to express canonical questions in Farkas’ (2022) sense (i.e., they constitute non-rhetorical, bias-free questions whose answer is unknown by the speaker and known by the addressee, with the latter assumed to be able and willing to quickly deliver it). Prosodically, they will be shown to lack a terminal rise, thus displaying a prosodic contour that is also available for non-corrective canonical questions across several regional varieties of Italian (Gili Fivela et al. 2015).
The paper also addresses two theoretical issues raised by the acceptability of corrective questions. The first concerns their interpretation, which must remain consistent with the standard interpretation of questions while also capturing the corrective import and focus value of the corrective foci they contain. As §2 will show, this interpretation emerges straightforwardly from a minimal and natural extension of standard focalization à la Rooth (1992) to the standard denotation of questions, and from its interaction with the notion of contrast as defined in Neeleman and Vermeulen (2012). This is a simple but important result. It tells us that as far as interpretation is concerned, corrective questions are unproblematic. Semantically, there are no obstacles to the presence of corrective foci in wh-questions.
The second issue concerns where corrective foci are interpreted. There are two competing hypotheses in this respect. The first, which is also the null hypothesis, maintains that corrective foci can be interpreted in-situ as per Rooth’s semantics of focalization (1992). Under this hypothesis, wh-phrases and in-situ corrective foci are necessarily interpreted in separate positions, and, therefore, their co-occurrence in corrective questions is unproblematic (for an illustration of how focalization in-situ eventually determines the focus value of an entire sentence, see Rooth 2016: 29). Focalization in-situ in Italian, Spanish, Japanese, and Georgian within broader analyses of these languages is also considered in Brunetti 2004; Costa 2013; Samek-Lodovici 2015, 2024a; Abe 2016; Borise and Polinsky 2018.
The second hypothesis, widely held across cartographic studies and henceforth called the FocP hypothesis, maintains that corrective foci and wh-phrases must be interpreted in the specifier of a unique left-peripheral FocP projection that cannot simultaneously host both (Rizzi 1997; Rizzi and Cinque 2016; Rizzi and Bocci 2017; Bocci et al. 2018). Crucially, the FocP hypothesis also applies to in-situ foci.Footnote2 They, too, are assumed to move to specFocP covertly or to establish an exclusive relation with specFocP to the same effect.Footnote3 The FocP hypothesis thus predicts corrective questions to be impossible, since either their wh-phrase or their corrective focus, even when in-situ, would be left uninterpreted.
A short history of the FocP hypothesis provides a better understanding of which types of interrogative clauses and foci need to be considered in this paper. The FocP hypothesis was first proposed in Rizzi (1997), the seminal paper that also established the existence of a syntactically rich left periphery the study of which has provided important insights to this day. Amongst other claims, Rizzi argued that positing a left-peripheral FocP projection targeted by corrective foci would potentially explain why these foci may front in declarative clauses (as in the English example your BOOK, I read, not his). The competition between wh-phrases and corrective foci for specFocP, in turn, might potentially account for the ungrammatical status of the sentences in (2) hosting a wh-phrase and a fronted focus (Rizzi 1997: 291; the subscript F marks focalization). These sentences will be examined again in §6.2, where their ungrammaticality will be shown to follow from a different cause and where (2)(a) will be shown to be acceptable once an appropriate context and prosody are provided.
- (2)
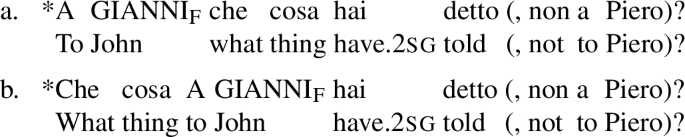
Rizzi (1997) proposed that clauses have the left-periphery layout in (3) with the FocP projection sandwiched between topic-expressing projections situated between the complementizers for finite and non-finite clauses. Since Rizzi’s paper, a vast literature further explored which types of topics, foci, and other constituents populate the left periphery (see citations in Rizzi and Bocci 2017 and Rizzi and Cinque 2016). For example, Rizzi and Bocci (2017) proposed the updated layout in (4) where the new projection IntP hosts the wh-operator perchè (why) and the new projection ModP hosts a class of fronted adverbs. The distinction between hanging and left-dislocated topics in Benincà (2001) and Benincà and Poletto (2004) should also be added. None of these updates, however, affected the FocP hypothesis but for the exclusion of perchè (why) from the wh-operators competing for specFocP.
- (3)[ForceP che [TopicP* [FocP [TopicP* [FinP a/di [TP …
- (4)[ForceP che [TopicP* [IntP [TopicP* [FocP [TopicP* [Mod [TopicP* [FinP a/di [TP …
Significantly for this paper, the competition between wh-phrases and foci only concerns root clauses. Rizzi (1997) already acknowledges that subordinate questions hosting wh-phrases and foci, like (5), are grammatical (Rizzi 1997: 300, FN 18). For this reason, Rizzi (2001) proposed that wh-phrases and foci target the same FocP projection in root clauses, but distinct projections in subordinate clauses. This proposal has been widely adopted since (e.g., Rizzi and Bocci 2017; Rizzi and Cinque 2016). Therefore, the corrective questions studied in this paper are problematic for the FocP hypothesis only if they constitute root clauses. As §5 will show, they do.
- (5)

Also significant for this paper is which focus types are assumed to be interpreted in specFocP. Not all are maintained to do so. For example, Belletti (2004) claimed that new-information foci target a lower focus projection.Footnote4 Similarly, Bianchi and Bocci (2012) claimed that non-corrective contrastive foci do not front and are interpreted in-situ. Corrective and mirative foci, however, are still maintained to move to FocP for their interpretation. Corrective foci, in particular, have most widely and consistently been assumed to do so. They are also the foci that Rizzi (1997) used as evidence for the FocP hypothesis. For these reasons, this study examines questions containing corrective foci rather than other focus types.
The corrective questions examined in this paper constitute a serious challenge to the FocP hypothesis. I will argue that—at least as far as corrective focalization is concerned—it should be abandoned and replaced by focalization in-situ.Footnote5 I will also argue that the distribution of corrective focalization is more regular and less surprising than entailed by the FocP hypothesis. In-situ corrective foci will be shown to be possible across declarative and interrogative clauses, whether root or subordinate, thus revealing a less constrained model of human grammar where the distributions of corrective foci and wh-phrases are independent from each other and unaffected by the root/subordinate distinction. The study of focused hanging topics and fronted corrective foci in §6 will add further evidence to these claims.
The paper is organized as follows: §2 presents the definitions of corrective focalization followed in this study. It provides English examples of questions with and without corrective focus and presents the minimal extensions to Rooth (1992) and Neeleman and Vermeulen (2012) that enable their interpretation. §3 presents the class of Italian corrective questions at the heart of this study, describing the contexts that license them and their prosody. §4 presents the experiment that demonstrated the grammaticality of Italian corrective questions based on the acceptability judgements of 30 participants assessing five constructions across six different contexts. §5 presents converging evidence across semantics, prosody, and syntax for the root status of Italian corrective questions, also examining them in relation to Farkas’ canonical questions criteria. §6 discusses the theoretical consequences for the FocP hypothesis, also examining correctively focused left-peripheral hanging topics, fronted corrective foci, and Bocci et al.’s (2018) experimental data in support of the FocP hypothesis. §7 presents the paper’s conclusions.
2 The role of focus and contrast in corrective questions
I assume that corrective focalization occurs when focalization à la Rooth (1985, 1992, 2016) is combined with contrast à la Neeleman and Vermeulen (2012) as discussed in this section. These two notions were originally developed for declarative clauses rather than interrogative clauses. Therefore, a minimal natural extension to Rooth’s and Neeleman and Vermeulen’s proposals is necessary to ensure that the corrective foci of corrective questions remain interpretable. As the next subsections show, the proposed extension is both plausible and possible, showing that there are no interpretative obstacles to the grammaticality of corrective questions. This also means that the ban on co-occurring corrective foci and wh-phrases in the FocP hypothesis has no semantic justification and, therefore, it cannot be motivated as mandated by the syntax-semantic interface.
I start with a brief summary of the proposals by Rooth and Neeleman and Vermeulen for declaratives and then describe the minimal extension necessary for corrective questions.
2.1 Corrective moves expressed by declarative clauses
Under Rooth’s alternative semantics model (1985, 1992, 2016), the focus value of a declarative clause containing a focused phrase is equal to the set of alternative propositions formed by replacing the referent of the focused phrase with alternatives of the same semantic type (plus a further restriction to contextually salient referents). For example, the focus value of Jo likes APPLESF, with APPLES stressed and focused, is the set containing the propositions ‘Jo likes apples,’ ‘Jo likes pears,’ ‘Jo likes bananas,’ etc.Footnote6
Neeleman and Vermeulen (2012) define contrast based on Rooth’s definition of focus. They maintain that the presence of contrast on a focused constituent entails that at least one of the alternative propositions evoked by focalization is false.Footnote7 The presence of contrast is also claimed to optionally license focus fronting (Krifka 2008; Neeleman and Vermeulen 2012).
Following Neeleman and Vermeulen, I assume that conversational exchanges where focalization conveys a correction combine Rooth’s focalization with Neeleman and Vermeulen’s contrast. The assumption that contrast is key to corrective focalization is uncontroversial and maintained across several studies. These include Rizzi (1997) and Belletti (2004), where corrections are assumed to involve contrastive focus (as opposed to non-contrastive focus) and to require overt or covert fronting. Similarly, in Cruschina (2021a), contrast may give rise to corrective exchanges and licenses focus fronting.
Under the assumptions laid out so far, answer B in the corrective exchange (6) involves contrastive focalization on FRANCE. The presence of contrast lets speaker B exploit the focalization of FRANCE to reject the proposition ‘John visited Italy’ introduced by speaker A. (Throughout the paper, round parentheses mark optional material; small caps represent non-emphatic nuclear stress; capitals represent emphatic stress. The difference between non-emphatic and emphatic stress in Italian is described in §3 in relation to examples (10) and (11)).
- (6)A: John visited italy.B: (No.) John visited FRANCEF. (Not Italy.)
As Leusen (2004) explained, corrective exchanges depart from the typical monotonic updating of the common ground, where every newly added proposition is consistent with all prior ones. Corrections require the interlocutors to retract a previously entered proposition and replace it with a new one. In (6), the addition of contrast to the focalization of FRANCE unleashes a corrective move where the proposition ‘John visited Italy’ is retracted from the common ground and replaced by the proposition ‘John visited France.’
2.2 Corrective moves expressed by interrogative clauses
Since questions denote sets of propositions, rather than individual propositions, the notions of focus, contrast, and corrective exchange just introduced need to be slightly extended in order to apply to corrective questions.
Before describing such extension, note that I intentionally will not address the issue whether wh-phrases are or aren’t themselves focused, but see the insights in Beck and Reis (2018) and Badan and Crocco (2019) on focused wh-phrases in echo questions, Cruschina (2021b) on Sardinian wh-phrases, and Bocci et al. (2021) on the relation between wh-phrases and focus features.Footnote8 In this paper, focalization within an interrogative clause always concerns the focalization of a constituent other than the wh-phrase.
Similarly, I will not discuss the intervention effects caused by specific scope configurations of wh- and focus operators and their ultimate causes (see a.o. Beck 2006; Kamali and Krifka 2020; and Howell et al. 2022). Though the corrective questions described herein might be relevant to this topic,Footnote9 for the goals of this paper it is sufficient to note that their acceptability attests that no intervention effect is at play.
Having clarified these caveats, we may consider the interpretation of corrective questions. Like declarative clauses, interrogatives clauses may or may not contain a focused constituent. When they do, the focused constituent may or may not involve contrast. The proposed extension to the notions of focalization and contrast is best conveyed by considering each of these three cases and examine how their interpretations differ.
2.2.1 Interrogative clauses lacking an internal focus
Following Krifka (2008), I maintain that questions manage expectations about how the common ground is going to be updated, rather than directly updating the common ground with new propositions like assertions do. Consider a simple question like (7) uttered by a mother to her husband as she hears her only son having a phone conversation in a separate room. This question lacks an internal focused constituent.
- (7)Who is Bill calling?
Under Krifka’s model, question (7) creates the expectation that the next proposition entering the common ground will be chosen from those in the question’s denotation, i.e., one picked from the set of propositions of the form ‘Bill is calling X,’ with X ranging over a contextually delimited set of individuals (Hamblin 1973).
2.2.2 Interrogative clauses containing a non-contrastive focus
Now consider (8), where the father’s reply illustrates the case of an interrogative clause containing a focus, but lacking contrast. This time there are two children, Bill and Mary, and a babysitter. Both children are having a phone call, each in their separate rooms. The parents just got home. The mother hears Bill’s call and asks the babysitter the same question we saw in (7), using the same intonation. The father hears both calls and wants to know who each child is calling. He uses focalization to bring the daughter’s call into the discussion while still keeping the mother’s question active (indeed his question can be introduced by and). This is achieved by focalizing Mary through nuclear stress while destressing the discourse-given VP calling. Note how the father’s interrogative clause lacks the intonational terminal rise of the mother’s simpler interrogative in (7). Yet, it still expresses a genuine question, i.e. one demanding an answer (Schwabe 2007). Henceforth, the absence of the terminal rise, which also characterizes the Italian data, will be represented by adding the subscript ntr (no terminal rise) to the final question mark.
- (8)Mother: Who is Bill calling?Father: (And) who is MaryF calling?ntr
Since Mary is focalized, the focus value of the father’s question ought to contain all the questions of the type ‘who is X calling?’ with X ranging over potential callers, thus including the son as well. This set corresponds to the denotation of a more general question under discussion (QUD) that has the uttered questions ‘who is Bill calling?’ and ‘who is Mary calling?’ as its sub-questions (see also Constant 2014;Footnote10 Büring 2003; Wagner 2012).
The difference between the mother’s question in (7) and the father’s question in (8) is brought about by the presence of a focused constituent. Note that focalization remains non-contrastive, though. Indeed, its interpretation does not fit any of Cruschina’s (2021a) categories of contrast: it is not a correction; it has no mirative import (it doesn’t concern expectations); and it is not exhaustive (it does not exclude other questions from being posited or considered).
2.2.3 Interrogative clauses containing a contrastive focus
Interrogative clauses containing an internal focus that is also marked by contrast give rise to corrective exchanges. They trigger the retraction and replacement of a previous question from the set of active questions waiting for an answer.
An example is provided in (9) under a scenario where two twins, Bill and Mark, have very similar voices and one of them is calling a friend. Their mother comes home with their aunt and meets the father, who was already at home and might know which friend is being called. The aunt hears the phone conversation and, mistakenly identifying the caller as Bill, asks the father who is Bill calling?. The mother, who can discern her children’s voices, corrects the aunt by asking, still with the father as addressee, who is MARKF calling?. Focalization here involves emphatic stress on MARK and the question’s prosody lacks a terminal rise.
- (9)Aunt: Who is Bill calling?Mother: (No.) Who is MARKF calling?ntr (Not Bill.)
The mother’s question represents a corrective move involving the retraction and replacement of the aunt’s question. Unlike (8), where at the end of the exchange the mother’s and the father’s questions remain both active and answerable, in (9) the aunt’s question who is Bill calling? is retracted and replaced by who is MARK calling?. Any answer provided by the father, for example Jane, will be interpreted as identifying who Mark is calling, not Bill. The corrective nature of the mother’s contribution is confirmed by the optional presence of the initial and final negative tags No and Not Bill that Leusen (2004: 418) describes as typical of corrective exchanges and that we already observed with corrective declaratives in (6).
The presence of parallel properties across declarative and interrogative corrective exchanges suggests that they share the same analysis. I propose that the corrective move unleashed by the mother’s question in (9) follows from the addition of contrast to the focalization of MARK. As mentioned, under Neeleman and Vermeulen’s definition, contrast entails that at least one of the propositions in the sentence’s focus value is invalid. Correspondingly, I propose that the presence of contrast on a focused constituent inside an interrogative clause entails that at least one of the alternative questions in its focus value is invalid, and thus no longer allowed to potentially manage expectations about the future evolution of the common ground.
Put differently, the presence of contrast on the focalized subject MARK in (9) informs the participants to the exchange that the propositions about to update the common ground will have the form ‘Mark is calling X,’ rather than ‘Bill is calling X.’ By contrast, in (8), the absence of contrast in the focalization of Mary ensured that the common ground was expected to be updated with propositions with either of the forms ‘Mary is calling X’ and ‘Bill is calling X.’
Focalization à la Rooth plus contrast à la Neeleman and Vermeulen thus account for the interpretation of questions lacking a focus, containing a non-contrastive focus, or containing a contrastive focus. The Italian corrective questions examined in this paper belong to the third class and are found in corrective exchanges similar to (9).
As the parallelism between declaratives and interrogatives shows, the contrastive foci found in corrective questions are the exact same foci found in the corrective declaratives typically examined by FocP analyses (e.g., Rizzi 1997, 2004; Bianchi 2013; Bianchi and Bocci 2012; Cruschina 2021a). Therefore, I will from now on follow the cartographic terminology and simply call this class of contrastive foci ‘corrective foci.’
In conclusion, we have seen how focalization à la Rooth and contrast à la Neeleman and Vermeulen easily extend and account for the interpretation of corrective questions and the corrective foci they contain. There are no semantic obstacles to the acceptability of corrective questions. The next two sections show that there are no syntactic obstacles either. Under the appropriate context and prosody native speakers find them acceptable.
3 Corrective questions in Italian
In Italian, corrective questions can be built at will whenever an appropriate context is provided. This section introduces a few examples—including some that were used as experimental items in the experiment described in the next section—and examines their prosodic properties.
Consider a situation involving three brothers with a very stern mother. One of the brothers, Alberto, received a bad mark at school. The other two, Sandro and Marco, worry about their parents’ reactions over the bad news. The exchanges in (10) and (11) take place under the context just described, with Sandro and Marco addressing their questions to Alberto. In both, Sandro asks Alberto what he told Dad. Immediately after that, and before Alberto can reply, Marco asks Alberto what he told Mom. Whereas Sandro’s questions are identical across both exchanges, Marco’s questions have different prosodies, leading to very different interpretations even if the words remain the same.
In (10), Marco only intends to add his own question to the set of active questions without removing Sandro’s from the set. His question could optionally be introduced by the conjunction E (and), and its prosody, with non-emphatic nuclear stress on mamma (mom), resembles that of Sandro’s question. A recording of my pronunciation for Marco’s question in this exchange is provided in Fig. 1.Footnote11 The pitch contour matches one of the pitch contours typically available for Italian questions (the prosody of Italian questions is described in §5.1). Note the terminal rise on the second syllable of mamma, which in Italian remains possible for this class of questions, though not obligatory. Under this prosody, Marco’s words express a simple question that successfully joins Sandro’s in the set of active questions. Alberto is expected to answer both.
- (10)

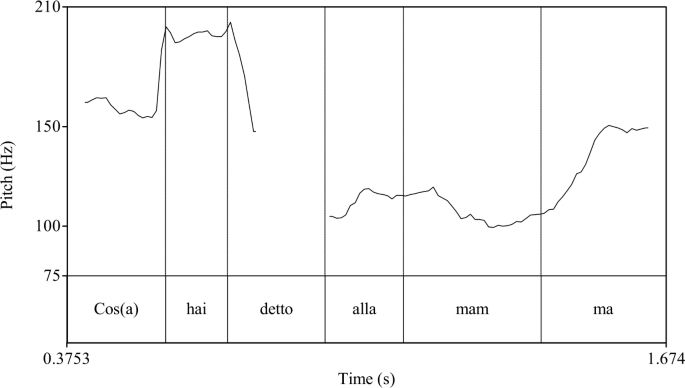
Pitch contour for Marco’s reply in exchange (10)
Exchange (11) also starts with Sandro’s question. This time, Marco intends to correct Sandro’s question and replace it with his own. A suitable context for (11) would be one where Marco believes that Sandro’s is asking the wrong question because what the brothers should worry about is the reaction of their stern mother, not their father’s. Therefore, Marco uses emphatic stress to correctively focalize MAMMA and replace Sandro’s question with his own. After Marco’s question, Alberto may legitimately consider Sandro’s initial question as withdrawn from the set of active questions and answer only Marco’s. The corrective move associated with this question also licenses the optional negative tags in parentheses that Leusen (2004) associated with corrective focalization in declaratives. As expected, the same tags are not felicitous in the previous correction-free exchange (10). Conversely, the previously available optional initial E (and) is unavailable in (11).
- (11)

In (11), Marco’s question obligatorily lacks a terminal rise and places emphatic stress on the first syllable of MAMMA (the syllable carrying lexical stress). These properties are visible in Fig. 2, which shows the pitch contour of my pronunciation when the question is asked without negative tags. The same recording was used in the experiment described in the next session and was deemed acceptable by most participants.
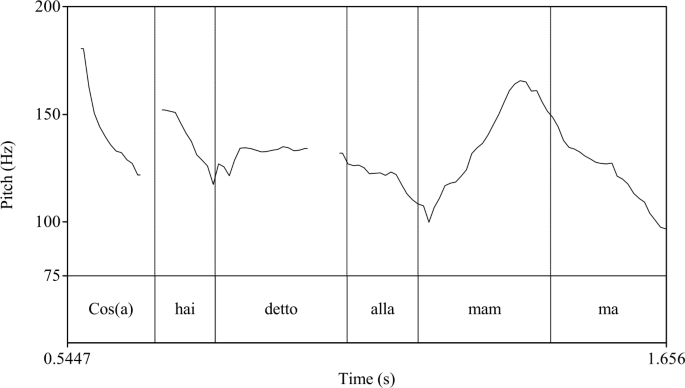
Pitch contour for Marco’s reply in exchange (11)
Similar exchanges can be built at will. Here, I provide just another example, also used in the experiment, whose prosody is worth noticing. Consider a situation where Lisa and Nino manage a team of tax inspectors responsible for checking the financial statements of several companies, including large and small ones. Today, Lisa and Nino are speaking with a group of inspectors. Lina asks how they checked the financial statements of small companies. Nino believes that the question that should be asked should concern the statements of large companies, not small ones. He applies corrective focalization on the adjective to correct Lina’s question and replace it with his own.
- (12)

The corresponding pitch contour when the question is asked without negative tags is in Fig. 3. This recording, too, was used in the experiment and deemed acceptable by most participants. As before, emphatic stress falls on the focused constituent, and there is no terminal rise. What is noteworthy is that the terminal rise remains absent even though corrective focus in this question is non-final, suggesting that the absence of a terminal rise follows from the presence of corrective focus rather than the close proximity of emphatic stress to the sentence’s edge.Footnote12
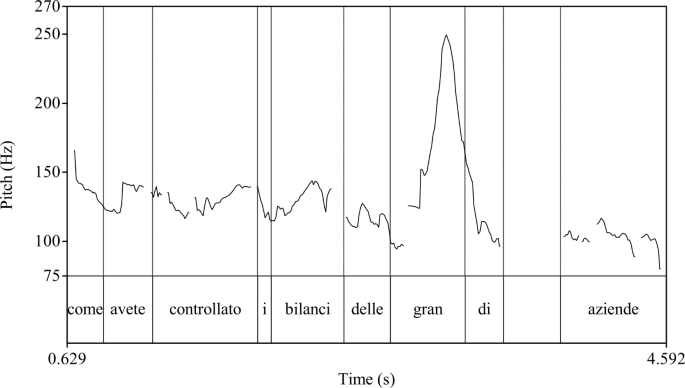
Pitch contour for Nino’s reply in exchange (12)
Before concluding this section, let me present a few examples of corrective questions mentioned by other scholars, who often also noticed the absence of a terminal rise. A first example was provided in Callegari (2019) in a talk concerning questions with foci. The talk’s handout presents the exchange below with speaker B’s corrective question deemed acceptable only when lacking a terminal rise (in the original handout, B’s question is shown with a full stop replacing the question mark; Elena Callegari (pc) kindly confirmed the interpretation, acceptability, and obligatory absence of a terminal rise for this example).
- (13)

A second example is provided in Seguin (2023) in her investigation of in-situ wh-phrases in the Franco-Provençal language Valdôtain Patois spoken in the Aosta valley in Italy. Seguin observes that Valdôtain Patois allows for the co-occurrence of wh-phrases and contrastive focalization, mentioning the example below. The audio recording of this sentence, which she kindly provided, appears to assign stress to the in-situ wh-phrase and it lacks a terminal rise.Footnote13
- (14)

Corrective questions also appear possible in German, English, and Norwegian. Three German scholars consulted by email about exchange (15) below and informed about its context and stress location found the corrective question by the senior inspector fully acceptable (the exchange was supplied with no question mark on the corrective question, but using written emails prevented me from properly checking for the presence/absence of a terminal rise).Footnote14 The same exchange is also possible in English, where the terminal rise is absent; see (16).
- (15)

- (16)Context: same as (15).Junior inspector: Who saw the victim?
Senior inspector: Who saw the MURDERERF?ntr
Finally, Callegari (2019) provides the Norwegian exchange in (17). She also confirmed that her informants found B’s corrective question acceptable only when it lacked a terminal rise (Callegari pc).
- (17)

While these examples are too unsystematic to be viewed as firm evidence, they do suggest that corrective questions might be available crosslinguistically. The next section describes the experiment that confirmed the acceptability of corrective questions in Italian, while the following §5 presents the evidence for their root clause status.
4 Experimental evidence for the acceptability of corrective questions
Italian corrective questions similar to those described in the previous section were tested through the online experiment described below. The experimental results, whose interpretation is discussed in detail later in this section, show that corrective questions with in-situ foci are generally deemed acceptable by native speakers. Those with fronted foci are also acceptable, but only when the fronted foci are non-objects.
4.1 Participants
Participants, both linguists and non-linguists, were recruited by email, rather than via an automatic platform like Prolific, to ensure that they were all native speakers of Italian. Most were contacted directly, while a few were recruited by the participants themselves. The invitation email provided a very brief description of the experiment and a link that launched the experiment on the Gorilla platform (Anwyl-Irvine et al. 2020). The participants received no remuneration.
Of the contacted participants, 34 accessed the experiment on the Gorilla platform, but only 31 completed it. Of these 31, one was excluded from the statistical analysis because the information supplied by Gorilla showed that in four occasions they had given assessments without first playing the corresponding audio recordings, thus rendering their assessments spurious. The remaining 30 participants all played all audio stimuli before providing their assessment.
The distribution of these 30 participants is reasonably balanced across age and sex, which were the only collected demographic data. Age-wise, there were 5 participants in the 18–30 age bracket, 6 in the 31–40 bracket, 6 in the 41–50 bracket, 9 in the 51–60 bracket, and 4 in the 61–70 bracket. Sex-wise, 15 were female and 15 males (“other” and “I’d rather not say” options were provided but left blank).
All participants provided their informed consent and confirmed that they were native speakers of Italian (an “other” option was provided but left blank).
4.2 Materials
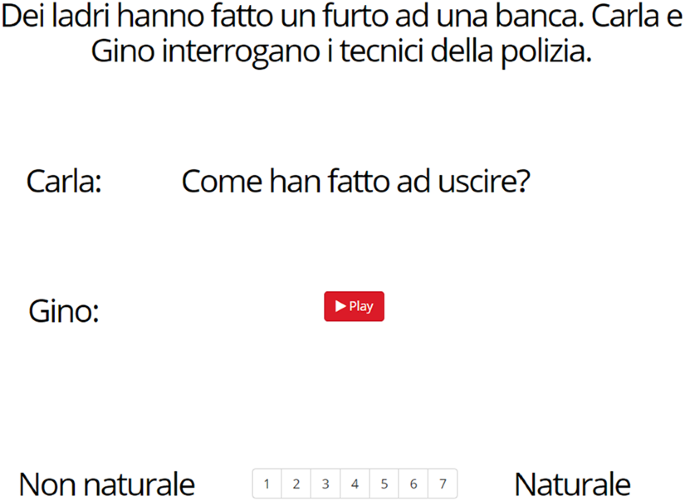
The experimental items presented to each participant consisted of 30 exchanges conducted in Italian between two speakers. Each experimental item consisted of one or two lines describing the situational context in which the exchange was assumed to take place, followed by the first speaker’s monoclausal information-seeking question presented in written form with the word receiving nuclear stress left in lower case, followed by a second question by the second speaker. This second question, which could be a corrective question or a filler, was provided in audio format and constituted the stimulus that the participants were asked to assess. All audio stimuli were recorded by the author, a male. For this reason the fictional names used for the second speaker were all masculine. An example is shown in (18), with the second question shown in written form. When reading the second question, remember that it lacks a terminal rise and that it is uttered with the intention to correct and replace the previous question. The original recordings are available for inspection at Samek-Lodovici (2024b).
- (18)

Each experimental item was presented in a single screen and entirely in Italian, without translations. The audio stimuli were accessed by pressing a red “Play” button and could be listened up to three times. The item illustrated in (18) would thus look as in (19) with the button “Play” colored in red.
- (19)Dei ladri hanno fatto un furto ad una banca. Carla e Gino interrogano i tecnici della polizia.Carla: Come han fatto ad uscire?
Gino:

The target stimuli were presented in audio format, rather than as written sentences, in order to naturally convey the prosodic pattern of the associated questions. Audio stimuli dispense with written representations and instructions about the position and intensity of stress or the presence/absence of a terminal rise, which are unlikely to be correctly interpreted by participants, especially non-linguists. This is particularly important when assessing the acceptability of constructions involving focalization.
Audio stimuli also prevent participants from attributing to the stimuli a prosody that diverges from the relevant one. Participants assess the prosody they hear, rather than the imagined prosody they would project on a written sentence, which cannot be controlled. Since prosody determines which phrases are interpreted as focused and whether a terminal rise is present/absent, using audio stimuli ensures that participants assess the intended focalization, rather than a different one not pertinent to the experiment.
All audio stimuli consisted of a single question with no negative tags. This ensured that participants assessed each stimulus without being influenced by any preceding or following information that could accidentally invite a focus, topic, or givenness interpretation that diverged from the one intended.
All participants assessed all 30 experimental items. The latter were organised in six groups. The five experimental items in each group shared the same situational context and first speaker’s question but presented a different audio stimulus. These stimuli, further detailed below, included the target stimuli—namely two versions of the same corrective question, one with focus in-situ, the other with a fronted focus—plus three other questions, each belonging to a different question type, that acted as fillers. With three fillers and two targets in each of the six groups, the participants assessed a total of 18 fillers and 12 target stimuli, thus fulfilling Keating and Jegerski’s (2015) recommendation for a preponderance of fillers relative to target stimuli.
An example is provided in (20), which collects together the stimuli of the five experimental items that shared the specific context and first question provided here. The first two, henceforth labeled “FISQ” for “focus in-situ question” and “FFQ” for “fronted focus question,” illustrate the target stimuli whose acceptability was being tested. Both matched the words of the first speaker’s question, except for the constituent being correctively focused through emphatic stress, and both lacked a terminal rise. FISQ and FFQ items also acted as reciprocal distractors.
The next stimulus illustrates the first class of fillers, henceforth labeled “OrQ.” These questions mapped the first speaker’s question into a corresponding closed question with two alternatives. In Italian, this class of closed questions can typically be uttered with or without a terminal rise. In this experiment, they lacked it.
The next class of fillers, labeled “&Q,” involved questions that started with the conjunction E (and). These fillers introduced a new question that complemented the first speaker’s question and joined it in the set of active questions. Most also presented a terminal rise. Both OrQ and &Q questions are quite natural in Italian and were expected to be deemed acceptable.
- (20)

The last filler class, labeled “*Q,” involved questions that were expected to be deemed ungrammatical while not being just plain gibberish. These questions repeated the words of the first speaker’s question but replaced its wh-phrase with a different one. They also assigned emphatic stress to the auxiliary, rather than the new wh-phrase, and they ended with a terminal rise. Their word choice and word order could be acceptable under a different context or prosody, but failed multiple grammar constraints under the prosody and context provided in the experimental items that hosted them. Firstly, by leaving the wh-phrase unstressed even if it provided new information and contrasted with the wh-phrase in the first question of the exchange. Secondly, by placing emphatic stress on the auxiliary despite its unfocused discourse-given status. Thirdly, by ending in a terminal rise, which, as discussed earlier, is incompatible with the presence of emphatic stress.
All audio stimuli were recorded using a VeeTop USB desktop microphone and uploaded onto the Gorilla platform. The questions in the first four classes (FISQ, FFQ, OrQ, &Q) are all acceptable in my idiolect. Therefore, I used the prosody that I found most natural for the proposed contexts. As mentioned, this prosody lacked a terminal rise for FISQ, FFQ, and OrQ questions. A terminal rise was instead present for &Q questions with the exception of the “and how quickly?” one (see recordings at Samek-Lodovici 2024b). Nuclear stress fell rightmost across all OrQ and &Q questions, and it was replaced by emphatic stress on the focused phrase in FISQ and FFQ questions. The prosody of *Q, with their emphatic stress on the auxiliary and terminal rise, was instead arrived at by producing a standard question with a terminal rise, while also adding emphasis on the auxiliary.
The twelve FISQ and FFQ target stimuli involved different common wh-phrases typically maintained to target specFocP under the FocP hypothesis (thus excluding why). Their focused constituents varied in syntactic category and grammatical function, ranging across an object DP, an adjective within an object DP, an indirect object PP, a temporal adverb, a PP adjunct, and a clausal complement. All six FISQ target stimuli are listed below with their corrective focus underlined. The corresponding FFQ target stimuli are identical, but with the focus fronted right before the wh-phrase.
- (21)

The variation in situational context, question type, and focused constituent category made the 30 experimental items substantially different from each other, thus preventing satiation and carry-over effects. There were only two situations potentially involving a repetition of sort and both would still have involved very different items. The first could occur if, despite randomization, a participant faced two immediately subsequent items sharing the same situational context. The corresponding audio stimuli would remain significantly different because they would necessarily involve stimuli questions plucked from two separate types amongst the five &Q, OrQ, FISQ, FFQ, and *Q types described above. For example, if two subsequent items both referred to the specific situational context provided in (20), the corresponding audio stimuli would necessarily involve two different questions amongst those listed in (20). As the reader can see, these questions are very different from each other, and hence very unlikely to determine either a carry-over or satiation effect.
The only other case potentially involving a semblance of repetition could occur if, despite randomization, two immediately subsequent experimental items involved different contexts but presented audio stimuli belonging to the same question type, for example two FISQ questions. In this case, besides the distracting factor provided by the different situational contexts and different first questions, the two FISQ audio stimuli would necessarily vary in lexical content (since they concern different contexts), and also in the content, category and function of the focused constituent they contain, which, as mentioned above, could involve an adjective, direct object, indirect object, temporal adverbial, PP adjunct, or clausal complement, and never present the same choice across both stimuli. For example, the two hypothetical successive experimental items could involve two of the six FISQ questions listed in (21). These questions are very different from each other, and hence unlikely to determine satiation or carry-over effects.Footnote15
It is also worth noticing that Sprouse (2007) showed that satiation effects are typically small and less problematic than normally assumed. Sprouse’s study also showed that satiation is much more likely with yes/no categorical tasks than with the 7-point Likert scale assessment tasks used in this experiment because scale tasks behave similarly to magnitude estimation tasks (Sprouse 2007: 10), and the latter are not prone to satiation (Sprouse 2007: 85). Furthermore, Sprouse (2007: 91) showed that satiation is more likely when the number of sentences expected to be unacceptable by hypothesis is much larger than the number of those acceptable by hypothesis, for example, 70% of all items. In the experiment reported here, the corresponding ratio is just 20%, determined by the 6 ungrammatical—and hence by hypothesis unacceptable—*Q items.
4.3 Procedures
As mentioned, the experiment was provided online through the Gorilla platform (Anwyl-Irvine et al. 2020). After completing the informed consent and demographic questionnaires, participants were provided with instructions briefly describing the format of the experimental items and asking them to rate the naturalness of the audio stimuli on a 7-point Likert scale. They were also told the number of experimental items they would consider (namely 30), and the likely completion time (ten minutes).
The instructions were followed by a brief training session of four pseudo-experimental items with the same layout as the genuine ones, but involving unrelated constructions. This session allowed participants to familiarize with the format of the experimental items, including pressing the “Play” button to listen to the audio recording and supplying their assessment by pressing one of the 1 to 7 buttons at the bottom of the screen representing the 7-point Likert scale. A written message on the final screen announced the end of the training session, leaving participants free to wait as long as they wished before launching the actual experiment.
The order in which the experimental items were presented to each participant was automatically randomized by the Gorilla platform. The screenshot in Fig. 4 shows how the individual items were presented by the platform, with the situational context text at the top, the names of the two speakers, the written question by the first speaker, the red “Play” button for the audio stimulus, and the Likert scale buttons at the bottom. As mentioned, the audio stimulus could be listened up to three times. There was no limit to the allowed response time. Once a response was provided by pressing one of the numeric buttons, the experiment quickly moved to the next item after briefly showing a screen with the symbol “+.”
Screenshot of an experimental item
4.4 Results
The 900 analyzed Likert acceptability scores are available for inspection at Samek-Lodovici (2024b). The scores were standardized via a Min-Max normalization so that all scores would range between 0 and 1, with 0 representing the minimal Likert score assigned to an item by any participant (namely 1), and 1 the maximal score assigned by any participant (namely 7). The overall mean, standard deviation, and sample variation across all question classes were then calculated, yielding the values in Table 1.
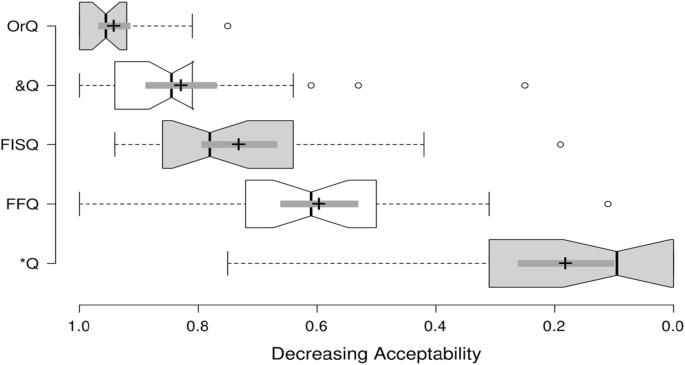
A box plot of the normalized mean acceptability scores for each question type is provided in Fig. 5 (obtained with the BoxPlotR software, Spitzer et al. 2014). Acceptability decreases from left to right, with 1.0 and 0.0 respectively representing maximal and minimal acceptability. The box plot shows the distribution of the thirty mean scores recorded for the corresponding question type, where each mean score provides the mean of the scores that each participant provided for the six experimental items presenting that specific question type. The boxes represent the second and third quartiles. The thick black vertical line in each box represents the median. The cross represents the mean, with the 95% confidence interval shown as a horizontal dark grey thick line extending at its sides. The plot also displays Turkey style whiskers extending 1.5 times the interquartile range, with individual outliers beyond these whiskers shown as circles.
Box plot of the experimental results
All standardized data were entered into a one-way repeated measures ANOVA using the JASP statistical software (JASP Team 2023). Sphericity was tested under Mauchly’s test and found to be violated (Table 2). Therefore, the ANOVA was run with the degree of freedom df corrected using the Greenhouse–Geisser sphericity estimate.
The ANOVA with a Greenhouse–Geisser correction and a 0.001 significance threshold signalled that there was a statistically significant effect of question type (Table 3).
The post hoc analysis of pairwise comparisons across the five question types with a Bonferroni adjustment with a p < 0.001 threshold, in Table 4, showed (i) a significant difference between *Q and all other question types; (ii) a significant difference of FFQ relative to OrQ and &Q, but not FISQ; (iii) a significant difference of FISQ relative to OrQ, but not &Q; (iv) no significant difference between OrQ and &Q.
The statistical analysis just described included all outliers, here defined as the mean scores of individual participants for a specific question type that diverged more than two standard deviations from the across-participants means listed in Table 1. A separate analysis excluding the outliers was also conducted. While it slightly raised the means for FISQ and FFQ questions, thus marginally improving their overall acceptability score, the question type pairs showing a significant effect in the post hoc Bonferroni adjusted comparison matched those in Table 4, thus leaving the most meaningful statistical results unaffected.
4.5 Discussion
As is always the case with experiments involving acceptability judgements, their interpretation hinges on the relation between the recorded assessments and the aspect of grammar the experiment is intended to test. Here, the experiment concerned the presence or absence of a constraint banning the simultaneous occurrence of wh-phrases and corrective foci in root interrogative clauses. The experimental results in the previous section should thus be interpreted under the assumption that the perceived acceptability of FISQ and FFQ items reflects to a sufficient degree the existence/non-existence of such a constraint.Footnote16 This section describes how the results support the grammaticality of FISQ questions and also examines what factors, some clear and some less clear, are likely to be responsible for the different acceptability scores assigned to the different question types.
The grammaticality of FISQ questions already emerges from the 110 FISQ items, out of the 180 assessed across all participants, that were rated at 6 or 7 (i.e. highly or fully acceptable). It also follows from the absence of a statistically significant difference between their acceptability and that of &Q questions. The corresponding p value of 0.117 in Table 4 is well above the 0.001 threshold used in this study and also above the 0.05 threshold sometimes used elsewhere. Since &Q questions are uncontroversially grammatical—they do not violate any grammar constraints—FISQ questions, too, must be considered grammatical, as otherwise their hypothetical ungrammatical status would have determined a statistically significant effect relative to &Q questions (much like the genuinely ungrammatical *Q questions did, as described later). The experiment thus provided clear empirical evidence against the assumption that wh-phrases and corrective foci compete against each other for the specFocP position because the effect that should inevitably follow from the violation of this assumption—namely, a statistically significant effect across FISQ and &Q questions—is absent.
Inspection of the mean scores across each question type in Table 1 lends further credibility to this result. At 0.73, the average score for FISQ questions sits well above the mid 0.5 value separating scores leaning towards acceptable from those leaning towards unacceptable. It is also much closer to the highest acceptability rating of 0.94 achieved by OrQ questions than the 0.18 rating of the genuinely ungrammatical *Q questions. The median acceptability for FISQ questions, which unlike the mean is unaffected by outliers, is even higher.
The experimental results also show a statistically significant difference between the ratings of FISQ and OrQ questions. This reflects independent factors known to reduce acceptability at statistically significant thresholds even when they apply to items uncontroversially considered as grammatical. One such factor is the decreased acceptability affecting stimuli involving wh-dependences. Goodall (2021: 21) describes it as “one of the most solid well-replicated findings” in the experimental literature. This penalty also applies to the wh-dependency contained in the FISQ stimuli and is a likely cause of their lower acceptability relative to OrQs.
Another well-known adverse factor is the positive correlation between perceived frequency and acceptability (Schütze 2019: 162). FISQ questions are infrequent constructions, certainly less frequent than OrQ questions. As such, they are likely to have suffered an acceptability penalty relative to them.
Finally, overall structural and parsing complexity also adversely affects acceptability independently from the underlying grammatical status of a construction, as is for example the case with garden path sentences before their meaning and structure become clear (Schütze 2019: 160). In this respect, too, the inherent complexity of FISQ questions probably lowered their overall acceptability.
The fact that despite all these adverse factors the acceptability of FISQ questions emerged as comparatively high and statistically not significantly distinct from that of &Q questions further strengthens the conclusion that FISQ questions are grammatical constructions, and, consequently, that wh-phrases and corrective foci can co-occur in root interrogatives.
As for the comparisons concerning the other questions types, an important result concerns the assumed grammaticality of OrQ and &Q questions and ungrammaticality of *Q questions. Consistently with such assumptions, OrQ and &Q questions received the highest acceptability scores (0.94 and 0.83, respectively), and *Q questions the least (0.18). Furthermore, the pairwise post hoc comparison found no statistically significant effect between OrQ and &Q questions (p = 0.038),Footnote17 whereas the acceptability of *Q questions was statistically significantly lower than that of all other question types.
The acceptability ratings of FFQ questions, with their fronted foci, are harder to interpret. Their in-depth analysis is postponed to §6.2 where I also consider the related experimental evidence from Bocci et al. (2018). Here, I only briefly mention the most noteworthy statistical measurements and effects. The post hoc comparisons in Table 4 show a statistically significant difference relative to the ungrammatical *Q questions, but also relative to the grammatical &Q and OrQ questions. When compared against FISQ questions, the mean score of 0.60 for FFQ questions is lower than the 0.73 mean of FISQ questions. This difference is not statistically significant under the adopted 0.001 threshold (though it would be under a 0.05 threshold).Footnote18 Also, the 0.60 mean and slightly higher median are almost twice as distant from the corresponding values for *Q questions than those for &Q questions, but not as convincingly as is the case with FISQ questions.
The factors known to decrease the acceptability of FISQ questions—presence of wh-dependencies, structural and interpretative complexity, perceived low frequency—also affect FFQ questions, partially explaining their lower acceptability relative to &Q and OrQ questions. The additional complexity caused by the presence of focus fronting, in turn, might explain their (non-significant) lower acceptability relative to FISQ questions, where focus remains in-situ.
A closer inspection of the 180 data points concerning FFQ questions reveals an interesting asymmetry between the experimental items involving fronted direct objects and the remaining items respectively fronting an indirect object, an adverb, an adjunct PP, and a clausal complement. As Table 5 shows, the mean scores for fronted direct objects are very low (see the last two columns), whereas those for fronted non-objects in the first four columns are closer to those of FISQ questions. As we will see in §6.2, a similar asymmetry also emerged in the experimental data of Bocci et al. (2018). The same asymmetry is instead absent from the FISQ scores where the mean scores for direct objects are in line with the mean scores of all other items.Footnote19
This suggests that direct objects resist focus fronting for reasons yet to be understood. Their low FFQ scores determine the relatively low 0.60 mean score obtained across all FFQ questions. When fronted direct objects are excluded, the mean for the remaining 120 assessed FFQ items is 71.50, hence closer to that of FISQ questions. Overall, FFQ questions could thus be considered as grammatical except when their focus is, or is contained in, a direct object. The discussion in §6.2 will further strengthen this conclusion.
Summing up, the experimental results support the grammaticality of corrective questions with in-situ foci. Corrective questions with fronted foci also emerge as grammatical, but only when involving non-object constituents.
5 Corrective questions are root interrogative clauses
If focalization can occur in situ, the observed acceptability of FISQ questions is expected. Their wh-phrase and corrective focus do not compete for the same position and are interpreted as described in §2. The acceptability of FISQ questions is instead problematic for the FocP hypothesis, where wh-phrases and in-situ corrective foci compete for specFocP. Under this hypothesis, FISQ questions should be ungrammatical, and hence unacceptable.
Most FocP analyses, however, assume that root and subordinate interrogative clauses differ in their left-peripheral layout. As mentioned in the introduction, root interrogatives are assumed to contain a single FocP projection shared by wh-phrases and corrective foci, whereas subordinate interrogatives are maintained to host two separate FocP and Qemb projections with FocP targeted by corrective foci and Qemb by wh-phrases (Rizzi 2001; Rizzi and Cinque 2016). Subordinate interrogatives thus allow for the co-occurrence of wh-phrases and corrective foci. It follows that the acceptability of FISQ questions genuinely challenges the FocP hypothesis only if they constitute root interrogative clauses. If, despite their root appearance, they actually were subordinate clauses selected by an elided matrix clause, then their acceptability would be accounted for even under the FocP hypothesis.Footnote20
Immediate evidence for the root status of FISQ questions comes from their interpretation. Like other root wh-questions, they demand and expect an answer. Subordinate interrogatives lack this property. As shown in §5.2 below, sentences like I ask you <question> are ultimately assertions that can license replies that do not answer the embedded question. This section will present additional evidence for the root status of corrective questions. The next few paragraphs highlight the theoretical cost associated with viewing FISQ questions as subordinate clauses, followed by additional arguments for their root status in §5.1–§5.4.
There is a considerable literature on subordinate interrogative clauses that display the syntax of root interrogatives when selected by certain predicates such as verbs of saying (e.g., McCloskey 2006 and Dayal and Grimshaw 2009). For example, the subordinate interrogative in (22), from McCloskey (2006), shows the same subject/auxiliary inversion found in its root counterpart in (23).
- (22)The baritone was asked what did he think of Mrs Kearney’s conduct. (James Joyce: Dubliners, 176, The Lilliput Press, Dublin).
- (23)What did he think of Mrs Kearney’s conduct?
This class of subordinate interrogatives—or “Quasi Subordinates” as Dayal and Grimshaw (2009) called them—always allow for a corresponding matching root counterpart. For example, the subordinate interrogative in (22) has the root interrogative in (23) as its matching counterpart. Let me call this the “root counterpart” property.
Since the viability of FocP depends on viewing FISQ questions as subordinate clauses despite their root appearance, it is natural to ask whether FISQ questions are themselves Quasi Subordinates. If they were, however, they would have a root counterpart, and the co-occurring wh-phrase and corrective focus in that root counterpart would once again challenge the FocP hypothesis. It follows that the viability of the FocP hypothesis requires FISQ questions to not belong to Quasi Subordinates.
Put differently, whereas the main insight from the research on Quasi Subordinates is that there exist subordinate interrogatives that mimic their root counterparts, the viability of the FocP hypothesis requires an ad hoc assumption in the opposite direction: namely, that FISQ questions always lack a root counterpart, even though they look like, and are interpreted as, root interrogatives. This is an odd property. It does not follow from known grammar principles and no evidence has been presented in its support.
The following sections show that there is instead converging prosodic, syntactic, and semantic evidence for the root status of FISQ questions. I start with the discussion of their prosody, showing that the absence of terminal rise is well documented in Italian root questions and thus cannot be interpreted as evidence for subordinate status. I then discuss two syntactic tests that should detect the presence of an elided matrix clause, if one were present, but fail to do so. Finally, I show that FISQ questions satisfy the properties that identify canonical questions in Farkas (2022), which, in her model, inevitably require root status.
5.1 Terminal rise and root clause status
Corrective questions lack a terminal rise. Is this property consistent with root status?Footnote21 The considerable research of the last twenty years on the prosody of Italian questions shows that a terminal rise is neither a necessary nor predominant property of root interrogatives. Numerous studies across different regional varietiesFootnote22 repeatedly showed that polar and wh-questions can systematically lack a terminal rise (e.g., Savino 2012 for the preponderant absence of a terminal rise in yes/no questions in spontaneous speech across Italy, and Gili Fivela and Iraci 2017 on wh-questions in the Palermo variety).
Particularly robust in this respect are the findings in Gili Fivela et al. (2015); their study presents the most systematic and comprehensive survey of questions across the Italian peninsula to date. It describes the prosody of different constructions across the 13 regional varieties spoken in the following cities of the Italian peninsula (grouped by macro linguistic area): Milan and Turin (North), Florence, Siena, Pisa, and Lucca (Tuscany), Rome (Centre), Pescara, Napoli, Salerno, and Bari (South), Cosenza and Lecce (Extreme South). The study examined data elicited in relation to 57 pre-designed contexts presented in pseudo-randomized order and recording the prosody of both spontaneous and directed speech (i.e., reading written text).
With respect to standard information seeking root wh-questions, Gili Fivela et al. (2015) identifies four varieties that always lack a terminal rise (Naples, Pisa, Pescara, Lecce); eight varieties allowing for both absence and presence of a terminal rise (Milan, Turin, Lucca, Siena, Roma, Salerno, Bari, Cosenza), and finally the Florence variety as the only one always requiring a terminal rise (Gili Fivela et al. 2015: 178–181).
The twelve varieties in the first two groups demonstrate that the presence of a terminal rise is not a necessary property of Italian root interrogatives. In fact, wh-questions without a terminal rise are so productive that the final summary of the study presents the absence of a terminal rise as the default: “Wh-questions show a statement-like intonation (i.e. H+L* L%), although they may also show a final rising contours (H+L* LH%, similarly to that found for other Romance languages, such as […]).” (Gili Fivela et al. 2015: 195).
It follows that in Italian the absence of a terminal rise is consistent with root interrogative status. The robust empirical findings in Gili Fivela et al. (2015) show that for most Italian speakers root information-seeking wh-questions lacking a terminal rise are perfectly natural. Therefore, the prosody of FISQ questions is entirely consistent with their root status.
The only open issue is why a terminal rise is obligatorily absent. The main difference between corrective and non-corrective questions is the presence of a corrective focus, suggesting that the emphatic stress carried by the corrective focus prevents the presence of a terminal rise. I leave the investigation of the specific mechanics at play open to further research.
5.2 No elided matrix clause
Simons (2007: 1041) observes that even when a sentence’s main point is expressed by a subordinate, a reply might still address the assertion expressed by the matrix clause. This property also holds for subordinate interrogatives. For example, in exchange (24), the initial sì (yes) in speaker B’s reply addresses the matrix clause of A’s utterance. It acknowledges as true that A asked/wants to know what B ate. It does not answer the subordinate question by identifying what food was eaten.
- (24)

The same reply is severely infelicitous with root interrogatives and unsurprisingly so, since there is no matrix clause assertion that could be addressed and acknowledged. For example, B’s reply to root question A in (25) cannot start with sì (yes) because A is a genuine root interrogative lacking a separate matrix clause.
- (25)
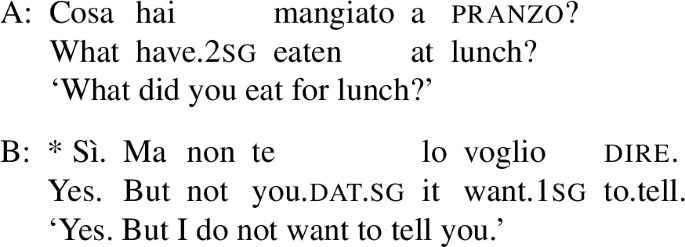
We can exploit this property to test whether corrective questions are root or subordinate clauses. If they were selected by a silent matrix clause, yes-replies should be possible. If, instead, they are genuine root interrogatives, yes-replies should be infelicitous.
The exchange in (26) is formed by adding a final response, namely Maria’s, to one of the exchanges used as experimental items. Maria has a tummy-ache and her parents Franca and Luca are trying to establish the cause by asking Maria what she ate. Luca corrects and replaces Franca’s question through his FISQ question. The exchange would be felicitous if Maria simply provided the sought information, for example, by answering pollo (chicken), which consistently with Luca’s FISQ question would be interpreted as the food Maria consumed at lunch. As the example shows, it is instead completely impossible for Maria to answer Luca’s FISQ question with a sì (yes) answer. Yet this should be possible if Luca’s question involved an elided matrix clause of the I want to know type whose truth Maria would acknowledge through the initial sì.
- (26)

A second example, also based on an experimental item, is provided in (27). Carla and Gino are speaking with the police forensic team to gather information about some bank robbers, with Gino correcting Carla’s question through a FISQ question. The exchange would be felicitous if the final policeman’s reply described how the robbers got out, thus answering Gino’s question. As the example shows, a sì reply is instead completely impossible, consistently with the root status of FISQ questions.
- (27)

Similar sì replies are also impossible across all the other experimental items involving FISQ corrective questions.Footnote23 In conclusion, the above test provides clear evidence against the presence of an elided matrix clause in FISQ corrective questions.
5.3 Lack of condition C violations
The previous section argued for the root status of FISQ questions by showing that they display the properties of root interrogatives, rather than subordinate ones.
Theoretically, a second line of reasoning could consider the distinctive properties of subordinate interrogatives with elided matrix clauses but no root counterparts and then examine whether FISQ questions display those properties. This theoretical test, however, cannot be developed further because no analysis claims the existence of such a class of subordinate interrogatives (remember that they would differ from Dayal and Grimshaw’s Quasi Subordinates). What remains possible, though, is considering a plausible representation of these hypothetical constructions and then test that representation. This section uses this strategy to test for the presence of an elided matrix clause using binding theory.
Consider the following exchange between three young friends: Gianni, Paolo, and Luca. Two parties have been organized, one by Gianni and Luca (the GL party), and one by Gianni and Maria (the GM party). Gianni wants to know who Paolo invited to the GL party. However, his question who did you invite to our party? is insufficiently informative about which party he is considering. The addressee, Paolo, tries to identify the relevant party by repeating and completing Gianni’s question, but incorrectly identifying it with the GM party. Hearing that, Luca intervenes with his FISQ question, which corrects Paolo’s question by reproposing it but replacing our party with festa di Gianni e ME (the party of John and me), i.e. the GL party.
- (28)

If FISQ questions involved elided matrixes, then Luca’s would plausibly have the structure in (29), with the elided matrix clause containing the verb asked or another comparable one.
- (29)
Giannihasasked[who you invited to the party of Gianni and MEF].
This structure, and any conceivable comparable ones, violates condition C, because the subject Gianni in the root clause c-commands Gianni in the subordinate clause. Consequently, Luca’s reply should be ungrammatical, and hence unacceptable. The fact that this is not the case provides evidence against the presence of an elided matrix, and consequently in favor of the root status of FISQ questions.
The hypothetical elided matrix clause for the FISQ questions used in the experiment would have to be slightly different. The form <subject> has asked <question> used in (29) would be pragmatically odd because the FISQ questions in the experimental items never involve the full repetition of a previous question. For example, an experimental item like (30) would require the semantically richer elided matrix  or
or  in (31) to be inferred from the presence of corrective focalization.
in (31) to be inferred from the presence of corrective focalization.
- (30)

- (31)
Franca should have asked / meant to ask[what you ate for LUNCHF].
This slight change in content does not affect the test’s outcome. Replacing Gianni has asked in (29) with Gianni should have asked, or Gianni meant to ask, still incorrectly predicts a condition C violation and the consequent unacceptability of Luca’s FISQ question in (28) where none is present. In conclusion, the hypothesis that FISQ questions are selected by an elided matrix clause is refuted by the absence of condition C effects where the hypothesized matrix clause would be expected to cause them.Footnote24
5.4 Canonical questions and root status
In her paper on non-intrusive questions, Farkas (2022) proposes a unified account of the semantics of questions and declaratives where the different types of non-canonical questions examined in the linguistic literature follow from minimal additions to the fundamental semantic content required to form questions. The key words here is additions; when those additions are absent, what emerges is necessarily a canonical question. Canonical questions thus follow from the minimal set of properties necessary to form a question.
Farkas’ model also establishes a tight relation between the canonical/non-canonical status of a question and the marked/unmarked status of the syntactic construction used to express it. Crucially, her model entails that canonical questions are always realized as unmarked constructions.
Under the plausible assumption that Italian questions are no exception to Farkas’ model, the tight relation between canonicity and syntactically unmarked status provides a diagnostic test for the root status of corrective questions. If they display the distinctive properties of canonical questions, then they necessarily have root status, because root interrogative clauses are the unmarked expression of Italian canonical questions. If, instead, their structure involved an obligatorily elided matrix clause—a highly marked construction—then corrective questions would necessarily constitute non-canonical questions and as such they would necessarily miss or fail at least one of the distinctive properties that characterize canonical questions. Rejecting the premise of this test, i.e. denying the tight relation between canonicity and unmarkedness, is of course legitimate, but it means rejecting the comprehensive understanding of canonical and non-canonical interrogatives provided in Farkas (2022), or, at the very least, questioning its validity for Italian.
The rest of this section shows that Italian corrective questions do indeed constitute canonical questions as far as Farkas’ model is concerned and, consequently, have root status. Arguing for the canonical status of corrective questions might at first appear surprising, as we intuitively associate canonical questions with run-of-the-mill non-corrective questions, whereas corrective questions are infrequent, due to their equally infrequent licensing contexts, and because besides asking a question they express a corrective move. But intuition can be misleading. Farkas (2022) provides a precise definition of canonicity and the properties it entails. Questions that satisfy those properties count as canonical and inherit the properties entailed by their canonical status—here root clause status—no matter their frequency, contexts, or the additional pragmatic moves they might express.
In what follows, I briefly describe Farkas’ model to illustrate the difference between canonical and non-canonical questions and then show that FISQ questions qualify as canonical.
Farkas defines canonical questions as “information seeking acts whereby an ignorant speaker requests an addressee she assumes to be knowledgeable to inform her to the true answer to the question she raises” (Farkas 2022: 297). In her model, the relation between canonical questions and the unmarked constructions expressing them follows logically and directly from the minimal semantic content that a clause needs in order to be interpreted as a question. When nothing is added to this basic content, the result is a canonical question that is logically bound to satisfy the four distinctive properties in (32) (Farkas 2022: 297).
- (32)

Farkas calls these properties the “default assumptions accompanying question acts,” but as their content makes clear the term assumptions here refers to the assumptions that the participants engaged in a conversation make about the cognitive state of the speaker and addressee when processing a basic, i.e. canonical, question. In other words, the default assumptions in (32) are not theoretical assumptions required to make Farkas’ model work, but distinctive properties of canonical questions that in her model are entailed by the minimal semantic content necessary to form a question.
Setting aside non-canonical interpretations due to the properties of specific contexts (Farkas 2022: 328–331), here irrelevant, Farkas shows that non-canonical questions arise when the minimal semantic content necessary to form a question is enriched with additional content whose final effect is to weaken or suppress one or more of the four default assumptions in (32). For example, tag questions—a class of biased questions containing sentences like Susan is coming with us, isn’t she?—arise from additional semantic content that weakens the Speaker ignorance assumption, resulting in a non-canonical interpretation where the speaker epistemic state is biased towards one of the alternative propositions being considered.
The details of Farkas model are too fine-grained and tightly connected to be discussed in full here. Roughly speaking, a question denotes a set of alternative propositions that is tabled by a speaker to an addressee and that is resolved, at least in the simplest cases, when all participants commit to one of the alternative propositions. The actual resolution mechanics is determined by the basic semantic content of the question. All questions encode a “basic conventional discourse effect” (Farkas’ “basic cde”) that enables the few simple operations necessary to resolve a tabled question, such as updating the input context—roughly corresponding to the common ground plus any background information—in accord with one of the alternative propositions denoted by the question.
Crucially, Farkas shows that the operations specified in the basic cde logically entail the four default assumptions in (32). Clauses endowed with just the basic cde thus always give rise to canonical questions.
Non-canonical questions possess the basic cde as well, since it encodes the minimal operations that get clauses interpreted as questions. However, whereas canonical questions are only associated with the basic cde, non-canonical questions—specific contexts aside—always involve one or more additional special cde’s specifying the additional semantic operations that eventually determine the weakening or suppression of one or more of the four default assumptions in (32), thus enabling a non-canonical interpretation.
Under Farkas’ model, these special cde’s might be expressed by specific morphemes. When they are, they give rise to a marked construction. Since only special cde’s give rise to these additional morphemes, and since only non-canonical questions require special cde’s, it follows that canonical questions are never expressed by a marked construction (Farkas 2022: 327).
This important insight provides a test for the root status of Italian corrective questions. As discussed at the start of §5, the FocP hypothesis necessarily requires them to be expressed by a marked structure: namely, a subordinate interrogative clause lacking a root counterpart and selected by an elided matrix clause (not to mention lacking a subject in the elided clause referring to the exchange participants; see footnote 25). Under Farkas’ model, such a marked construction could only follow from the presence of a special cde that also weakened or suppressed one or more of the four default assumptions in (32) (most plausibly Address compliance, since as the previous section showed the hypothetical matrix clause would have the form <subject> should have asked <question>, or <subject> meant to ask <question>, which do not assume that the addressee will provide any information). Put differently, under Farkas model the marked structure that the FocP hypothesis is forced to assume for corrective questions would necessarily associate with a non-canonical interpretation.
This prediction can be tested. We only need to check whether corrective questions satisfy Farkas’ four default assumptions identifying canonical questions. If corrective questions fail one or more of them, then the prediction is met, supporting the FocP view of corrective questions. If corrective questions satisfy all of them, then the prediction is refuted together with the marked structure associated with it, further supporting the claim that corrective questions are root clauses.
Consider, for example, the FISQ question asked by Marco in the exchange below from one of the experimental items. It satisfies Speaker’s ignorance, because Marco does not know what Alberto told their mother. It satisfies Addressee competence, because Marco has good reasons to assume that the addressee Alberto knows the information that is required to answer the question satisfactorily. It satisfies Addressee compliance, because Marco has no reason to doubt that Alberto will consider his question and answer it. It also satisfies Issue resolution goal, because Marco’s aim in asking the question is to have it promptly and satisfactorily answered.
- (33)

It follows that Marco’s question constitutes a canonical question in Farkas’ model. Since Marco’s question is canonical, it must be expressed with the same unmarked constructions used for any other Italian canonical question, namely a root interrogative clause. The fact that Marco’s question also expresses a corrective move does not affect its canonical status, because what matters is only whether the question satisfies the four default assumptions, which it does. The same reasoning applies to all other FISQ questions in the experimental items.
In conclusion, consistency with Farkas’ model requires us to analyze Italian corrective questions as root interrogatives expressing a canonical question. There is nothing special about them. The corrective focus they contain allows them to correct a previous question, but they nevertheless constitute and are interpreted as canonical questions demanding and expecting an answer like any other run-of-the-mill information seeking wh-question. By contrast, viewing them as mandatory subordinates of an elided matrix clause and lacking root counterparts, as required by the FocP hypothesis, turns them into unexplained exceptions to Farkas’ model.
Unrelated to the main argument developed in this paper, it is worth noticing how corrective questions provide a new subclass of canonical questions in addition to classic run-of-the-mill information-seeking questions. Corrective questions differ from classic canonical questions because they also convey a corrective move, yet they still qualify as canonical because they satisfy the canonicity criteria. This shows that the notion of canonical status formally defined in Farkas’ model is a property that can be shared across slightly different classes of questions. This creates an interesting typology where some subclasses of canonical questions may have specific properties—here the ability to express a corrective move via corrective focalization—provided those properties do not affect the four default assumptions inherent to canonicity.
6 Theoretical consequences
The previous sections showed that Italian FISQ questions are grammatical and constitute root clauses. These results are consistent with the focalization in-situ hypothesis and refute the hypothesis that wh-phrases and contrastive foci compete for the specifier of FocP or any other position. If this were the case, FISQ questions would be unacceptable, which they clearly are not. Even FFQ questions would be much less acceptable than they are.
These results point to a model of grammar with fewer stipulations. A model consistent with the null hypothesis that root clauses, whether declarative or interrogative, do not fix the position where focus is interpreted, enabling corrective foci to be interpreted in-situ independently from the presence or absence of wh-phrases.
These results also tell us that the existence of corrective questions with in-situ foci is unremarkable. Corrective questions are inevitable constructions emerging whenever interrogative root clauses host corrective foci, much like corrective statements emerge from declarative clauses hosting corrective foci. We find corrective questions remarkable only because the contexts licensing them are infrequent and because we are used to view them from the perspective of the FocP hypothesis incorrectly telling us that they should not exist.
The paper could end here with in-situ interpretation firmly established for the in-situ corrective foci of corrective questions. However, it is worth examining left-peripheral foci as well, both fronted and base-generated, ones since they played an important role in establishing the FocP hypothesis.
The shorter §6.1 shows that left-peripheral hanging topics can be correctively focused, an expected behavior if they are interpreted in-situ as advocated here, but a problematic one under the FocP hypothesis (see also Samek-Lodovici, to appear).
The more substantial §6.2 examines fronted foci. First, it examines why Rizzi’s well-known 1997 examples, briefly mentioned in (2) above, are ungrammatical, identifying the real causes of their ungrammatical status and showing that they become grammatical once those causes are addressed. Second, it examines the available experimental evidence on the grammaticality of fronted foci in root interrogatives, including an in-depth discussion of the issues that unfortunately undermine the design, and ultimately the results, of Bocci et al.’s (2018) experiment. Finally, it examines the object/non-object divide in acceptability scores that emerged across the experiment presented in this paper and in Bocci et al. (2018). In both experiments, fronted non-object corrective foci emerge as generally acceptable, suggesting that, at least for non-objects, the free distribution displayed by in-situ corrective foci across declaratives and interrogatives extends to focus fronting as well.
6.1 Correctively focused hanging topics
Hanging topics are usually analyzed as base-generated in a position higher than fronted foci (Benincà 2001; Benincà and Poletto 2004; Giorgi 2015). Under the FocP hypothesis, they should thus be unable to correctively focus because that would require lowering them to specFocP and lowering is banned. Under focalization in-situ, instead, they should be able to focalize in their base-generated position like any other constituent.
As B’s reply in exchange (34) shows, hanging topics can indeed be correctively focused. The hanging-topic status of the focused phrase mio MARITO (my husband) is not in doubt because it displays the distinctive properties of Italian hanging topics: namely, dropping of the proposition con (with) normally required for the argument of parlare (to speak), and the obligatory resumption of the entire topic mio MARITO by the clitic ci (with him).Footnote25 The presence of corrective focalization, in turn, is confirmed by the interpretation of B’s reply and the optional presence of Leusen’s negative tags. (The subscript “HT” marks hanging topics.)
- (34)

The existence of correctively focused hanging topics is significant. Since hanging topics are generated too high to focus in FocP, rejecting focalization in-situ would force us to view cases like (34) as involving fronted foci rather than hanging topics. This, in turn, would beg the question of why these foci require clitic-doubling and allow for preposition-dropping, whereas the standard fronted foci typically examined in the focalization literature do not.
Allowing for focalization in-situ dissolves the issue. Hanging topics require clitic-doubling whether they are focused or not. Under this view, whatever factor is responsible for clitic-doubling in these sentences is orthogonal to focalization and relates to the hanging topic status of these constituents alone.Footnote26 Conversely, standard fronted foci do not display clitic-doubling because they are raised from a lower position and co-indexation with a c-commanding clitic would cause a condition B violation.
In conclusion, adopting focalization in-situ straightforwardly accounts for the existence of correctively focused hanging topics. They are instead unaccounted for under the FocP hypothesis because they cannot comply with the required movement to specFocP.
6.2 Fronted foci
One of the main motivations for the FocP hypothesis is the potential explanation it provides for the licensing of fronted foci in declaratives, while also potentially explaining the well-known examples in Rizzi (1997: 291) concerning questions simultaneously hosting a wh-phrase and a fronted corrective focus. As this paper has shown, focalization in-situ makes better predictions than the FocP hypothesis about corrective questions with in-situ foci, but is it consistent with the existence of fronted foci and Rizzi’s examples?
6.2.1 Rizzi’s examples
Let me start with Rizzi’s examples, already mentioned in (2) and repeated below. They originally were, and usually still are, presented without context, as if they were out-of-the-blue sentences. When assessed as such, they are indeed unacceptable. As discussed in §2, corrective focalization in questions is used to correct and replace a preceding question under a suitable context. Without a preceding question to contrast against and eventually replace, corrective focalization in interrogative clauses is unlicensed, explaining the unacceptability of both examples.Footnote27
- (35)
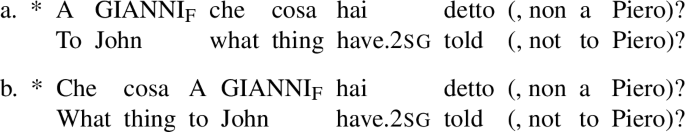
Both examples are also usually presented in written form and without instructions about their prosody. Readers may thus easily project onto them a terminal rise. As we saw in this paper, a terminal rise is unacceptable in Italian corrective questions. These two factors—lack of a licensing context with a preceding question in need of correction and the potential for an inappropriate prosody—account for the ungrammatical status of both examples. Therefore, they cannot be considered evidence for the FocP hypothesis and the associated ban against corrective foci and wh-phrases in root interrogatives.
Once an appropriate context and prosody are provided, these sentences become acceptable. For example, the experimental item for fronted IO foci, repeated below in written form, is identical to (35)(a) but for the substitution of GIANNI with MAMMA and the omission of che.Footnote28 In the experiment, 13 participants assessed Marco’s question in (36) as fully acceptable, assigning it a 7 in the Likert scale. Even its normalized mean acceptability score across all 30 participants, at 0.74, is comparable to that of FISQ questions at 0.73 (where “1” represents full acceptability and “0” full unacceptability). This shows that under an appropriate context and prosody, fronted IO foci in root interrogatives matching those used in Rizzi (1997) are actually acceptable, and hence grammatical.Footnote29
- (36)

6.2.2 Experimental evidence on fronted focus in interrogatives
Determining whether focus fronting is generally possible in root interrogatives is important, as it distinguishes between the FocP and the focalization in-situ hypotheses. The FocP hypothesis predicts fronted corrective foci in root interrogatives to be impossible. Focalization in-situ, instead, makes no predictions on their acceptability. Under this hypothesis, focus fronting in declaratives is not driven by the need to interpret focus because interpretation may already occur in-situ. Therefore, fronting constitutes a separate operation triggered by independent factors.Footnote30 Whether these factors succeed in triggering fronting even in root interrogatives or not does not depend on, nor affect, focalization in-situ, which remains possible under either scenario. Given this predictive landscape, the existence of acceptable root questions containing fronted corrective foci would support focalization in-situ, since they are predicted impossible under FocP, whereas their absence would be consistent with both hypotheses.
Leaving aside Rizzi’s 1997 examples, already addressed above, the experimental evidence on this issue includes the experiment presented in this paper and the experiment in Bocci et al. (2018), henceforth called the “written experiment” because it involved written stimuli. The written experiment compared focus fronting across root and subordinate interrogatives and found, amongst other results concerning the object / non-object divide discussed later, that the stimuli with fronted foci in root interrogatives were significantly less acceptable than fronted foci in subordinate interrogatives. An example of the experimental items used to assess fronted direct object foci in root interrogatives is copied below exactly as it appears in Bocci et al. (2018: 33). Please read it carefully, noticing the negative tag non Marcella (not Marcella) and the fronted focus Paola (Paula) supplied in lower case in the last sentence. This is also the sentence whose acceptability the participants were asked to assess.
- (37)

There are several problems with the design of this experimental item, and any other similar ones, and they are very likely to have adversely affected the experiment’s results.
First, the experimental items were presented in written form. Therefore, the participants did not know under what prosody they should assess the target sentences. This matters, because in Italian prosody provides possibly the strongest cue for determining whether a fronted constituent should be assessed as a topic or a focus, with fronted corrective foci signaled by emphatic stress and topics by a B-accent (Büring 2003).
Bocci et al. (2018) explains that the experiment designers refrained from signaling the position of stress typographically due to the possible confusion this might generate in participants not accustomed with linguistic conventions. While this concern is reasonable, the absence of any such signal or instruction deprived the participants of a crucial cue, letting them examine and assess the target sentences under whatever prosody came to their mind at the time. As a result, we do not know whether they assessed each target sentence under the intended interpretation or a different, incorrect one. For example, as they started reading the target sentence in (37), some participants might have attributed a B-accent to the fronted object Paola and interpreted it as a topic, rather than as a fronted focus as intended. This, in turn, would have affected their assessment.
Bocci et al. (2018: 33–34) acknowledges the issues raised by written stimuli in relation to prosody and provides a detailed explanation of how the content of the experimental items was supposed to guide the participants to the correct interpretation. The explanation is quite dense. Its second, shorter paragraph, copied below, describes which syntactic cues were expected to ensure that participants did not assign a topic interpretation to fronted indirect object (IO) and direct object (DO) foci, such as the fronted DO focus Paola in (37) above.
“Recall that we expect focus fronting not to be possible in root wh-questions. If this hypothesis is correct, the participants might resort to a topic interpretation of the IO in order to save the sentence. In this sense, the presence of the negative tag was instrumental in favoring a focus interpretation of the fronted IO. Note that in case of fronted direct objects the picture is slightly different. Direct objects that undergo focus fronting to the left periphery cannot be resumed by a clitic element, while object topics clitic left dislocated to the left periphery must (Benincà 1988, Cinque 1990, Rizzi 1997). The presence (or the absence) of the resumptive clitic is thus sufficient to disambiguate the nature of an object in the left periphery, even in written stimuli without the negative tag.”
This paragraph suggests that the experiment designers expected the participants to execute two tasks. First, the participants would determine whether the fronted constituent in the target sentence was a topic or a focus by checking the syntactic cues provided in the experimental item. For example, when faced with Paola in (37) above, they were supposed to understand that they needed to consider it a fronted focus, rather than a left-peripheral topic, due to the absence of clitic-doubling. Then, and only then, they would assess the acceptability of the entire sentence under the identified interpretation.
Many participants, however, most probably assessed the experimental items in relation to the first interpretation that came to their mind. For example, since nothing in the presentation of the experimental items prevented it, many participants probably attributed a topic status to the fronted object Paola in (37) and then assessed the sentence as unacceptable precisely because the required clitic-doubling was absent, thus unduly inflating the number of “unacceptable” assessments. The presence of negative tags, itself problematic for reasons discussed later, is also unable to distinguish between topics and foci because topics can themselves be correctively focused and license negative tags, as we saw in §6.1.
A second factor inappropriately inflating the number of “unacceptable” assessments was the absence of instructions about the presence/absence of a terminal rise. For example, even amongst the participants who correctly chose the intended fronted focus interpretation for Paola in the target question of (37), several probably read the question with a terminal rise, thus making it inevitably unacceptable and adding further spurious negative assessments to the experimental results. This is particularly likely to have occurred because written questions tend to invite a terminal rise; see Savino (2012) and Grice et al. (1997) on the effects of reading on the prosody of Italian yes/no questions.
Note, furthermore, that the potential incorrect attribution of a terminal rise affected the experimental items asymmetrically, rather than affecting root and subordinate interrogatives equally, or balancing false positives with false negatives. Whereas root interrogative items were adversely affected in the manner just described, items involving subordinate interrogatives were not because they constitute statements. Since statements lack a terminal rise, the participants assessed these items under the intended prosody. It follows that root corrective questions were more likely to be assessed as unacceptable than their subordinate counterparts, thus artificially inducing or widening any potential acceptability divergence across them.
The last problematic factor concerns the presence of negative tags. Frey (2010: 1430) showed that even a simple final negative tag added to a reply involving a corrective focus is sufficient to remove the need to express the corrective force on the focus itself via the addition of contrast. The experimental items in Bocci et al.’s experiment do not control for Frey’s effect. For example, in (37), the sentence Ti ho chiesto un’altra cosa! (I asked you something else!) preceding the target sentence signals a corrective move, thus making it unnecessary to express this move by adding contrast to the focused phrase Paola. The target sentence itself involves the final negative tag non Marcella (not Marcella), and hence it need not involve contrast on the fronted item. Consequently, the experimental participants might have assessed the target sentence while treating the fronted object Paola as non-contrastively focused, rather than under the intended corrective focus interpretation. This, in turn, might have affected the acceptability of focus fronting.
Unfortunately, these are serious design issues. They undermine the very premise on which the experiment was run, namely that the acceptability of sentences like the target sentence in (37) would reflect the grammatical status of fronted corrective foci in root questions. The premise is not valid because for each recorded assessment concerning root interrogatives it is impossible to know whether it was actually provided under an incorrect topic or non-contrastive focus interpretation of the fronted constituent. Even when it did concern a corrective focus interpretation, it remains impossible to know how many of the collected assessments leaning toward “unacceptable” emerged from the accidental projection of a terminal rise. Since nothing in the design controlled for these factors, the recorded assessments do not constitute a reflection of the grammatical status of root interrogatives with fronted corrective foci, invalidating the experiment’s results.
These problematic design aspects also explain why corrective questions with fronted foci obtained a lower acceptability score in Bocci et al.’s experiment than in the experiment presented in this paper, henceforth called the “audio” experiment because it used audio stimuli. The audio experiment did not suffer any of the issues described above because (i) its participants assessed recordings of spoken data, thus leaving no ambiguity about the focus status of the fronted constituent in the item being assessed; (ii) the assessed items lacked a terminal rise, thus eliminating the related issue; and (iii) the target sentences were never surrounded by negative items or sentences of any sort, thus ensuring that the contained fronted focus would not be stripped of its corrective force. These precautions ensured that fewer items would be deemed unacceptable for the wrong reasons, and that any accidental misinterpretation of the experimental items would apply randomly, rather than asymmetrically.
In conclusion, the acceptability scores recorded for FFQ questions in the audio experiment provide a more accurate measurement of the acceptability of root interrogatives with fronted corrective foci than those recorded in Bocci et al.’s (2018) experiment.
6.2.3 The object/non-object asymmetry
The written and the audio experiments, however, do converge on two interesting observations. The first concerns the decreased acceptability of fronted DO foci vs other fronted foci in root interrogatives. As mentioned in §4.5, the audio experiment found corrective questions with fronted DO foci much less acceptable than with fronted non-object foci. The mean acceptability values of 0.46 and 0.26, respectively, for objects containing a focused adjective and objects focused in their entirety are more than one standard deviation lower than the respective values for non-objects, which ranged in the 0.68–0.76 interval (see Table 5. The standard deviation was 0.18; see Table 1. The values 0 and 1 represent minimal and maximal acceptability).
The same asymmetry also emerges in Bocci et al.’s written experiment where fronted DO foci are significantly less acceptable than fronted IO foci across root and subordinate interrogatives. Though weakened by the issues discussed in the previous section, this finding remains informative, because most of the described problematic factors applied to fronted DO and IO alike. Bocci et al. (2018: 39) also proposes some interesting likely causes for the asymmetry, attributing it to the crossing vs nested configuration of the corresponding wh- and fronted focus chains.
The second observation emerging from both experiments concerns the acceptability of fronted IO foci in root interrogatives, which even in the written experiment—and despite the design factors inflating negative assessments—emerged as acceptable as fronted DO foci in subordinate clauses. Bocci et al. do not report the mean acceptability scores for the fronted IO items, but the chart they provided, copied in Fig. 6 below, shows that their z-score (the pale circle representing IOFFDOWh items in the top vertical segment in the second column) is level with that for fronted DO foci in embedded questions (the dark diamond representing DOFFIOWh items in the bottom vertical segment in the first column). To the extent these two values are comparable, as both the chart and the brief discussion in Bocci et al. suggest, they show that the participants of the written experiment found fronted IO foci in root interrogatives to be as acceptable as fronted DO foci in subordinate questions, i.e. as acceptable as a construction that is considered uncontroversially grammatical across the focalization literature. To the degree we are comfortable accepting these results despite the problematic aspects discussed earlier, they provide evidence for the acceptability–and, therefore, grammatical status—of fronted IO foci in root questions.
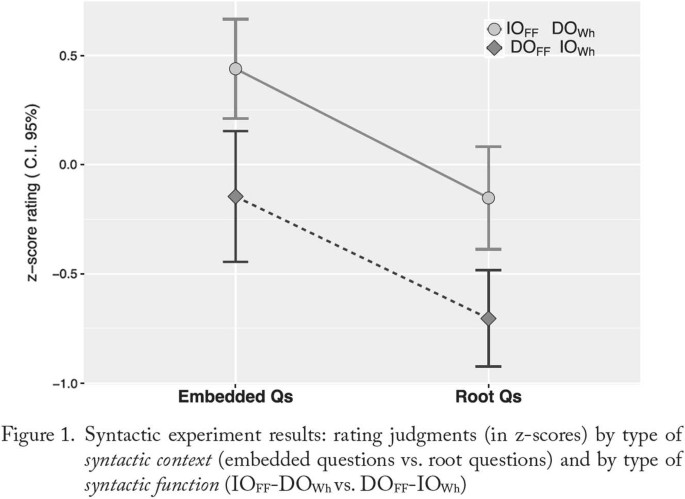
Experimental results chart from Bocci et al. (2018: 35)
The acceptability of fronted IO foci and other non-object fronted foci in root interrogatives also emerged clearly in the audio experiment. As shown in Table 5, the acceptability of non-object FFQ questions ranged between 0.68 and 0.76, and, as we saw in §6.2.1, fronted IO foci structurally identical to Rizzi’s 1997 examples were deemed fully acceptable by 13 participants and as acceptable as FISQ questions across all participants.
Both experiments thus recorded a noticeably high acceptability for fronted non-object foci and a low acceptability for object ones. While further research is necessary to explain the low acceptability of fronted object foci, the attested acceptability of root interrogatives with fronted non-object corrective foci is problematic for the FocP hypothesis, since it predicts that such constructions should be impossible. It is instead unproblematic for the focalization in-situ hypothesis where fronting is driven by independent factors, as discussed at the start of §6.2.2.
Overall, when we consider both in-situ and fronted foci, what emerges is a very different and much less constrained distribution of corrective focalization than the commonly held one where corrective foci are banned from root interrogative clauses and where all foci behave alike. The distribution of corrective foci appears insensitive to the root/subordinate distinction and equally insensitive to the interrogative/declarative divide. In-situ corrective foci are grammatical across both declaratives and interrogatives, and regardless of whether they are root or subordinate. With non-objects, the same distribution extends to focus fronting; they may front in declaratives and interrogatives, and across root and subordinate clauses.
7 Conclusions
This paper showed that Italian corrective foci can co-occur with wh-phrases in root interrogative clauses, where they form corrective questions. This claim is particularly robust for in-situ foci, but as §6.2.1 and §6.2.3 showed it also extends to fronted non-object foci, and fronted indirect objects foci in particular.
Pragmatically and semantically, corrective questions correct and replace a previous question deemed incorrect and display the properties characterizing canonical questions in Farkas (2022). The corrective foci they contain are identical to the corrective foci of declarative clauses. Like them, they are successfully interpreted by Rooth’s (1985, 1992) alternative semantics model combined with contrast as per Neeleman and Vermeulen (2012), provided both notions are extended to interrogative clauses as described in §2.
Prosodically, Italian corrective questions lack a terminal rise, a property also systematically possible with non-corrective wh-questions across most regional varieties of Italian (see §5.1). In most varieties, however, non-corrective wh-questions also optionally allow for a terminal rise. Determining to what extent this asymmetry holds across each Italian regional variety and its ultimate cause is left open to future research.
The existence of corrective questions refutes the FocP hypothesis’ tenet that wh-phrases and foci compete for specFocP. Their existence instead follows if corrective foci can be interpreted in-situ and hence do not compete against wh-phrases for a specific position.
The assumption that root and subordinate clauses have distinct cartographic layouts, with foci and wh-phrases targeting the same unique FocP projection in root clauses but separate projections in subordinate clauses, should also be dispensed with. As Bocci et al. (2018: 36) notes, albeit while still following it, this assumption has the disturbing effect of making subordinate interrogative clauses less constrained than root interrogative clauses, unlike what occurs with other discourse-related constructions. Since corrective foci do occur in root interrogatives, assuming different left-periphery layouts across root and subordinate clauses becomes unnecessary, thus resolving the issue.
Focalization in-situ also accounts for the existence of correctively focused hanging topics (see §6.1). Like any other constituent, they focalize in their base-generated position. There is nothing special about them. Their existence appears remarkable only when viewed from the perspective of the FocP hypothesis, which incorrectly predicts their impossibility by assuming that they have to focalize in SpecFocP.
Overall, what emerges is a simpler, less stipulative grammar where corrective focalization in-situ may apply to any constituent regardless of their base-generated position, and it is available across declarative and interrogative clauses regardless of whether they are root or subordinate.
The same unconstrained distribution extends to fronted corrective foci with the exception of fronted direct objects, an exception whose underlying cause requires further research.
Notes
-
A very interesting and thorough study of focalization in questions is provided in Constant (2014) but it does not cover corrective focalization (i.e. cases that imply the withdrawal and replacement of a preceding question). Like the data examined in this paper, Constant’s (2014) data, when considered within his more general proposal that contrastive topichood is rooted in focalization, challenge the hypothesis that wh-phrases and foci cannot co-occur in root interrogative clauses. Constant’s data, however, substantially differ from those investigated here and including them would make this paper too long and complex. The same applies to the study of focalization in questions in Samek-Lodovici (2015); while some of its examples involve corrective foci, most do not involve the replacement and withdrawal of a former question and are thus ignored here.
-
This is no accident. Allowing in-situ foci to be interpreted outside FocP would undermine the claim that the interpretation of focus requires a dedicated focus projection or that such a projection is unique (at least for phrases undergoing the same type of focalization).
-
In the cartographic literature, covert movement to specFocP is by far the most frequent assumption concerning the interpretation of in-situ foci. Rizzi (2024: 200), however, very briefly mentions—unfortunately just in passing and without further discussion—the possibility that an agreement relation between FocP and an in-situ focus be established via feature movement or unselective binding.
-
Recent experimental studies have challenged this claim, showing that even new-information foci may front; see Samek-Lodovici and Dwyer (2024) for British English, Jiménez-Fernández (2015) for Southern Peninsular Spanish, Feldhausen and Vanrell Bosch (2014) for Catalan, and Skopeteas and Fanselow (2011) for Hungarian, German, Spanish, and Greek. See also Cruschina (2021a) for Sicilian and Sardinian and Cruschina and Majol (2024) for Spanish, Catalan, and Italian, as well as references therein to further studies claiming fronting of new-information foci.
-
Under focalization in-situ, FocP would host only wh-phrases, making WhP possibly a more accurate name for this projection. Adopting focalization in-situ, however, does not per se endanger the cartographic research programme, nor its modeling in terms of criterial markers as per Rizzi (2024). It does, however, raise the question of whether other discourse functions do genuinely require a dedicated projection for their interpretation even when corrective focalization, and possibly also other types of focalization, need none.
-
More precisely, the focus value for the sentence is compositionally assembled by combining together the focus value of each constituent, which denotes a set of alternatives of the corresponding semantic type. See the example provided in Rooth (2016: 29).
-
Bianchi (2013: 206) makes a similar proposal in relation to corrective focalization: “corrective focus can then be characterized as carrying the presupposition that one member of the set of alternatives is incompatible with the focus itself […].”.
-
Regine Eckardt (pc) suggests that wh-phrases themselves might be the target of corrective focalization. This raises the possible existence of correctively focused wh-phrases even when wh-phrases themselves are not assumed to be inherently focused. This issue, too, is left open to future research.
-
The scope relations of the wh- and focus operators in corrective questions are amongst those allowing for a successful interpretation under the semantic models proposed in Beck (2006) and Howell et al. (2022). They might also be of interest with respect to the alternative model in Kamali and Krifka (2020), where contrastive foci in constituent questions are re-interpreted as alternative-bearing contrastive topics. Part of Kamali and Krifka’s evidence comes from Turkish, where the foci found in interrogative clauses appear to follow the syntax of contrastive topics rather than foci. Like Turkish, Italian presents unambiguous syntactic clues to distinguish contrastive topics from contrastive foci because direct object topics require clitic resumption whereas fronted foci resist it. The focus-fronting Italian data described in §6.2 go the opposite way of Turkish because they present fronted foci without clitic resumption, thus going against a contrastive topic analysis.
-
Questions containing non-contrastive foci, like the father’s question in (8), are discussed at length in Constant (2014). Under his analysis, Mary is a contrastive topic, but, crucially, this occurs within a generalized theory of contrastive topics and focalization à la Rooth where contrastive topics constitute focused phrases whose interpretation involves sets-of-questions. In Constant’s model, the father’s question in (8) denotes the same sorted set of questions described here.
-
All pitch contours in this paper were extracted with PRAAT (Boersma and Weenink 2021).
-
It might still be the case that the emphatic stress on the focused constituent adversely affects the prosodic viability of a terminal rise, but it wouldn’t be due to stress adjacency. I leave this issue open to further research.
-
See also Seguin (to appear, Sect. 7.3.1.2) for some interesting Valdôtain Patois examples of root questions containing wh-phrases and non-corrective contrastive foci.
-
Martin Salzmann (pc) finds the senior inspector’s reply ambiguous between a non-corrective interpretation, where the question is simply added to the set of active questions, and a corrective one where it replaces the junior inspector’s question. As in Italian, the optional addition of an initial Und (and) or Nein (no) disambiguates between the two interpretations.
-
An anonymous reviewer asked why carry-over effects were not controlled via a Latin Square experimental design. I would have welcomed the opportunity to use this design, but the strict time deadlines under which the experiment had to be developed, run, and analyzed discouraged its adoption. Under a Latin Square design, the five types of assessed questions used as stimuli—namely OrQ, &Q, FISQ, FFQ, and *Q—would have called for the creation of five different groups of participants (so that each group would assess a separate question for each question type and avoid any repetition; for example, a different FISQ question per group). At the time, I could not know for certain whether I would be able to recruit a sufficient number of participants to create viable groups and still conclude the experiment on time. Since, as discussed, the audio stimuli were sufficiently different to make satiation and carry-over effects highly unlikely, a simple randomized presentation was deemed sufficient.
-
The fact that the stimuli were seldom assessed as completely acceptable or unacceptable is a feature of acceptability tests and as such unproblematic. See, for example, Lau et al. (2017), who argue for the intrinsic gradience of acceptability judgements by highlighting its ubiquity across a set of large-scale experiments. The gradient nature of acceptability judgements is also repeatedly attested across the experimental linguistics literature; see Myers (2017), Alves (2023), and the literature there surveyed. I follow Myers (2017) in assuming that the gradient nature of acceptability judgements follows from their constituting “the final output of psychological processes that unfold over time in a physical brain.” Gradience follows from the processing factors that are at work beyond and in addition to grammatical knowledge. These include linguistic factors, such as those identified a.o. in Bard et al. (1996: 33), Myers (2017), Schütze (2019), and Goodall (2021), concerning the higher acceptability of items with (i) a higher attested frequency in the tested language, (ii) lower structural complexity, (iii) higher semantic or pragmatic plausibility, or (iv) better conforming to a prescriptive norm or prestigious register. Other factors might also have an effect, such as working memory and even emotional state. Despite these confounding factors, Myers (2017), Schütze (2019), and Goodall (2021) defend the relevance of acceptability experiments for testing grammar, presenting a variety of experiments where acceptability tests were demonstrably informative about the underlying grammar constraints being tested.
The large number of experiments producing gradient acceptability judgements has also ignited a debate about the fundamental design of human grammar and specifically (i) whether grammar constraints are categorical (binary) or associated with different violation weights and/or probabilities; and (ii) whether grammar constitutes a separate cognitive module or it is fully integrated with cognitive processing (the one system / two systems debate); see a.o. Sprouse (2007), Lau et al. (2017), Myers (2017), Gerbrich et al. (2020), Kehl (2023), and Alves (2023). Unfortunately, the experimental results reported in this paper do not appear to provide insights on these matters.
-
An anonymous reviewer noted that the lower acceptability score of &Q relative to OrQ questions would be statistically significant under the 0.05 threshold and wondered about its relevance. The presence or absence of a statistical effect between &Q and OrQ questions, or any other grammatical construction, is irrelevant to the argument developed in this paper. Since the compared constructions are both considered grammatical, any observed difference in acceptability, here the lower score of &Q questions, is necessarily just another manifestation of the independent gradience effects affecting all constructions, grammatical ones included; see the discussion in the main text and in footnote 16. When assessing the acceptability of FISQ questions as a proxy for their grammatical status, what matters is that a statistically significant effect relative to the undoubtedly grammatical &Q questions is absent even under the higher 0.05 threshold; see again the p = 0.117 value determined by the post hoc comparison between FISQ and &Q questions in Table 4.
-
Interestingly, similar results emerge when comparing fronted foci against in-situ foci in declarative clauses. In their written-stimuli study of corrective, mirative, and merely contrastive exchanges, Bianchi et al. (2015) show that in declaratives fronted corrective foci attain a statistically significant lower acceptability (p < 0.001) relative to their in-situ counterparts. The simplest explanation for this parallelism is that the lower acceptability of fronted foci across declaratives and interrogatives is determined by the same cause. It is methodologically unsound to instead assume that the observations concerning interrogatives follow from a separate cause specific to them alone, namely the presence of a competing wh-phrase.
-
An anonymous reviewer wondered whether stimuli with fronted direct objects might have been less likely to be re-analyzed into more acceptable constructions and whether this might have affected their acceptability. At this stage, any discussion of such an effect would be highly speculative. Future experiments might be able to investigate or at least control for this potential factor.
-
Thanks to Silvio Cruschina (pc) for alerting me about this possibility. The distinction between root and subordinate interrogatives in corrective questions is also discussed in Callegari (2019).
-
I am grateful to an anonymous reviewer and to Giuliano Bocci (pc) for independently raising this issue.
-
Regional varieties represent how Italian is spoken across different regions. They should not be confused with the dialects of Italy, even though they are affected by them. For example, whereas dialects from non-bordering regions are often mutually unintelligible and differ in phonology and syntax, the respective regional varieties are typically highly mutually intelligible and unlikely to display major syntactic differences.
-
The test can also be run with no replacing yes but it then requires additional conditions because in specific circumstances no answers can legitimately follow root questions. Furthermore, the presence of corrective foci licenses the presence of Leusen’s no negative tags. A valid test with a no answer remains possible provided that the clause following no explicitly addresses the presence of a matrix predicate. For example, the answer No. Non me l’hai chiesto (No. You did not ask me that) would be pragmatically very odd yet marginally possible in (24), where A’s contribution involves the overt matrix clause ti chiedo (I ask you), but completely impossible in (25) where A’s contribution is a root question, thus distinguishing root from subordinate. Like the yes reply discussed in the main text, such no reply remains completely unacceptable in (26) and (27), consistently with the root status of FISQ corrective questions.
-
Martin Salzmann (pc) points out that the presence of a condition C violation depends on the content of the elided clause. For example, no violation would occur in (29) if the elided clause were
 . Determining the hypothetical content of the equally hypothetical elided matrix is inevitably difficult. Nevertheless, there is clear evidence against the impersonal it’s about matrix just considered. FISQ questions have the illocutionary force of questions; they demand an answer. The hypothetical matrix would thus need to preserve the interrogative status of its subordinate FISQ question. Such status is preserved when the matrix involves the verb asked, or a comparable verb, as in the examples discussed. It is instead not preserved by an it’s about matrix, thus excluding this class of clauses from consideration.
. Determining the hypothetical content of the equally hypothetical elided matrix is inevitably difficult. Nevertheless, there is clear evidence against the impersonal it’s about matrix just considered. FISQ questions have the illocutionary force of questions; they demand an answer. The hypothetical matrix would thus need to preserve the interrogative status of its subordinate FISQ question. Such status is preserved when the matrix involves the verb asked, or a comparable verb, as in the examples discussed. It is instead not preserved by an it’s about matrix, thus excluding this class of clauses from consideration.To see this, consider again the typical corrective exchange in (30). When the FISQ question is selected by a non-elided matrix like Franca meant to ask, yielding the Italian equivalent Franca intendeva chiederti cosa hai mangiato a PRANZO (Franca meant to ask what you ate for LUNCH), it can still be interpreted as a question. If, instead, the FISQ question is selected by the impersonal it’s about matrix, as in the Italian equivalent Riguarda cosa hai mangiato a PRANZO (it’s about what you ate for LUNCH), the exchange is no longer coherent and utterly infelicitous. This because the it’s about clause falsely states that what is being discussed is what the addressee ate for lunch, even though the initial question actually concerned what the addressee ate for breakfast, not lunch. Therefore, the hypothetical elided clauses under discussion require verbs such as ask, and these verbs run into the binding test failure presented in the main text.
More generally, the discussion of the hypothetical it’s about matrix shows that in order to evade the condition C violation argument proposed in this section, the elided matrix hypothesis—and ultimately the FocP hypothesis requiring it—must introduce ever more ad-hoc assumptions. Besides stipulating that FISQ questions involve an obligatorily elided matrix and that they always lack a root counterpart, the elided matrix must also be assumed to lack subjects referring to the exchange participants—that’s how the it’s about matrix disables the condition C test—so that the testing of condition C becomes impossible, and with it any potential outcome refuting the existence of the elided matrix itself.
-
The corresponding sentence with a standard fronted focus is provided in (i). Note the obligatory presence of the preposition con (with) and the absence of clitic-doubling.
- (i)
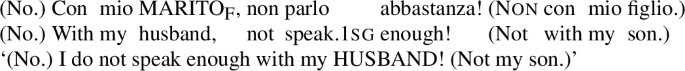
Incidentally, the exchange in (34) was checked with several informants. It was also found acceptable by one anonymous reviewer and left uncommented by a second anonymous reviewer who described themselves as a native speaker of Italian. It was, however, viewed as unacceptable by a third anonymous reviewer, potentially suggesting the presence of a degree of variation amongst speakers.
- (i)
-
The obligatory clitic-doubling of hanging topics follows when analyzing hanging topics as belonging to a separate clause undergoing ellipsis. The clitic then replaces the hanging topic in the second clause; see Samek-Lodovici (to appear) for further discussion and references.
-
Jones’s (1993: 334) and Cruschina’s (2021b:51) studies of Sardinian present unacceptable sentences structurally similar to Rizzi’s 1997 examples. They, too, are presented without a licensing discourse context involving a previous question. As such, they might be unacceptable for the same reasons.
-
Italian che mostly occurs as a complementizer or relative pronoun introducing finite subordinate clauses, much like that does in English. In colloquial usage, che may also correspond to English what/which, as in che scarpe hai comprato? (what/which shoes did you buy?), and even just what when occurring alone, as in che hai comprato? (what did you buy?). Finally, che may optionally precede the wh-phrase cosa (what/thing) in simple questions like (che) cosa hai comprato? (what did you buy?). Rizzi’s examples in (35) are an instance of the latter.
-
In my idiolect, example (35)(b) is also acceptable once an appropriate context and prosody is provided. Detailing its more articulated structure and prosody would add unnecessary complexity and length to this paper, but see Samek-Lodovici (2015: 228–229) for discussion.
-
Some potential independent factors triggering focus-fronting have already been identified in the linguistic literature. For example, Neeleman and van de Koot (2008, 2010) and Neeleman et al. (2009) argue that focus fronting marks the domain of contrast. Samek-Lodovici (2015), in turn, argues that Italian focus fronting is triggered by the application of right dislocation—an extremely productive operation in this language—to the discourse-given clause originally containing the fronting constituent. Focus fronting ensures that the focused constituent does not remain stranded in the dislocated clause where it would cause prosodic and interpretational issues. The analysis accounts for the optionality of focus fronting, which then simply reflects the optional nature of right dislocation, as well as the properties of the constituents following fronted foci, which match those of right-dislocated phrases (for recent advancements on Italian right dislocation, see also Sun 2021; Castiglione 2021, 2024; and Castiglione et al. 2024).
References
-
Abe, Jun. 2016. Make short answers shorter: Support for the in situ approach. Syntax 19(3):223–255.
-
Alves, Fernando. 2023. Categorical versus gradient grammar in phonotactics. Language and Linguistics Compass e12501. https://doi.org/10.1111/lnc3.12501.
-
Anwyl-Irvine, Alexander, Jessica Massonnié, Adam Flitton, Natasha Kirkham, and Jo Evershed. 2020. Gorilla in our midst: An online behavioral experiment builder. Behavior Research Methods 52(1):388–407.
-
Badan, Linda, and Claudia Crocco. 2019. Focus in Italian echo wh-questions: An analysis at syntax-prosody interface. Probus 31(1):29–73.
-
Bard, Ellen Gurman, Dan Robertson, and Antonella Sorace. 1996. Magnitude estimation of linguistic acceptability. Language 72(1):32–68.
-
Beck, Sigrid. 2006. Intervention effects follow from focus interpretation. Natural Language Semantics 14(1):1–56.
-
Beck, Sigrid, and Marga Reis. 2018. On the form and interpretation of echo Wh-questions. Journal of Semantics 35(3):369–408.
-
Belletti, Adriana. 2004. Aspects of the low IP area. In The structure of CP and IP, the cartography of syntactic structures, ed. Luigi Rizzi. Vol. 2, 16–51. Oxford: Oxford University Press.
-
Benincà, Paola. 1988. L’ordine degli elementi della frase e le costruzioni marcate. In Grande grammatica italiana di consultazione 1, ed. Lorenzo Renzi, 129–194. Bologna: Il Mulino.
-
Benincà, Paola. 2001. The position of topic and focus in the left periphery. In Current studies in Italian syntax. Essays offered to Lorenzo Renzi, eds. Guglielmo Cinque and Giampaolo Salvi, 39–64. Amsterdam: Elsevier.
-
Benincà, Paola, and Cecilia Poletto. 2004. Topic, focus and V2: Defining the CP sublayers. In The structure of CP and IP: The cartography of syntactic structures, ed. Luigi Rizzi. Vol. 2, 52–75. Oxford: Oxford University Press.
-
Bianchi, Valentina. 2013. On ‘focus movement’ in Italian. In Information structure and agreement, eds. Maria Victoria Camacho, Ángel Jiménez-Fernández, Javier Martín-González, and Mariano Reyes-Tejedor, 193–216. Amsterdam: Benjamins.
-
Bianchi, Valentina, and Giuliano Bocci. 2012. Should I stay or should I go? Optional focus movement in Italian. In Empirical issues in syntax and semantics 9, ed. Christopher Piñón, 1–18. Paris: CSSP.
-
Bianchi, Valentina, Giuliano Bocci, and Silvio Cruschina. 2015. Focus fronting and its implicatures. In Romance languages and linguistic theory 2013: Selected papers from ‘Going romance’ Amsterdam 2013, eds. Enoch Aboh, Amy Schaffer, and Petra Sleeman. Vol. 8, 1–20. Amsterdam: Benjamins.
-
Bocci, Giuliano, Luigi Rizzi, and Mamoru Saito. 2018. On the incompatibility of Wh and focus. Journal of the Linguistic Society of Japan 154:29–51.
-
Bocci, Giuliano, Valentina Bianchi, and Silvio Cruschina. 2021. Focus in wh-questions. Natural Language and Linguistic Theory 39:405–455.
-
Boersma, Paul, and David Weenink. 2021. PRAAT (Version 6.1.55). Computer Software. https://www.fon.hum.uva.nl/praat/.
-
Borise, Lena, and Maria Polinsky. 2018. Focus without movement: Syntax-prosody interface in Georgian. Proceedings of NELS 48.
-
Brunetti, Lisa. 2004. A unification of focus. Padova: Unipress.
-
Büring, Daniel. 2003. On D-trees, beans, and B-accents. Linguistics and Philosophy 26(5):511–545.
-
Callegari, Elena. 2019. On the (in)compatibility of foci and WH-operators. Talk handout, Unbound seminars in formal linguistics. Switzerland: Université de Genève.
-
Castiglione, Stefano Freyr. 2021. Solving an apparent paradox in Italian Right Dislocation, LAGB conference talk.
-
Castiglione, Stefano Freyr. 2024. A Biclausal Analysis of Italian Right Dislocation, PhD Thesis, University College, London, UK.
-
Castiglione, Stefano Freyr, Ad Neeleman, and Vieri Samek-Lodovici. 2024. Scope Freezing Restricts Binding in Italian Right Dislocation. Linguistic Inquiry:1-16.
-
Cinque, Guglielmo. 1990. Types of A’-dependencies. Cambridge, MA: MIT Press.
-
Constant, Noah. 2014. Constrastive Topic: Meanings and Realizations, PhD Thesis, University of Massachusetts at Amherst, MA, USA.
-
Costa, João. 2013. Focus in situ: Evidence from Portuguese. In From syntax to cognition. From phonology to text, Vol. 1, 621–662. Berlin: de Gruyter. (Original volume does not list the editors.)
-
Cruschina, Silvio. 2021a. The greater the contrast, the greater the potential: On the effects of focus in syntax. Glossa: a Journal of General Linguistics 6(1):3.1–30.
-
Cruschina, Silvio. 2021b. Focus fronting vs. wh-movement: Evidence from Sardinian. In Romance languages and linguistic theory 2018: Selected papers from ‘Going romance’ 32, Utrecht. Current issues in linguistic theory, eds. Sergio Baauw, Frank Drijkoningen, and Luisa Meroni. Vol. 357, 50–69. Amsterdam: Benjamins.
-
Cruschina, Silvio, and Laia Majol. 2024. The distribution of focus and the mapping between syntax and information structure. Journal of Linguistics:1–35.
-
Dayal, Veneeta, and Jane Grimshaw. 2009. Subordination at the interface: The quasi-subordination hypothesis. Ms. New Brunswick: Rutgers University. https://cpb-us-w2.wpmucdn.com/campuspress.yale.edu/dist/6/2964/files/2019/05/QSpaper.pdf.
-
Farkas, Donka. 2022. Non-intrusive questions as a special type of non-canonical questions. Journal of Semantics 39(2):295–337. https://doi.org/10.1093/jos/ffac001.
-
Feldhausen, Ingo, and Maria Del Mar Vanrell Bosch. 2014. Prosody, focus and word order in Catalan and Spanish: An optimality theoretic approach. In Proceedings of the 10th International Seminar on Speech Production (ISSP), eds. Susanne Fuchs, Martine Grice, Anne Hermes, and Doris Mücke. Köln, 122–125.
-
Frey, Werner. 2010. Ā-movement and conventional implicatures: About the grammatical encoding of emphasis in German. Lingua 120(6):1416–1435.
-
Gerbrich, Hannah, Vivian Schreier, and Sam Featherston. 2020. Standard items for English judgment studies: Syntax and semantics. In Experiments in focus: Information structure and semantic processing, eds. Sam Featherston, Robin Hörnig, Sophie von Wietersheim, and Susanne Winkler, 305–328. Berlin: de Gruyter. https://doi.org/10.1515/9783110623093-012.
-
Gili Fivela, Barbara, and Massimiliano Iraci. 2017. Variation in intonation across Italy: The case of Palermo Italian. In Fattori sociali e biologici nella variazione fonetica. Studi AISV 3, eds. Chiara Bertini, Chiara Celata, Giovanna Lenoci, Chiara Meluzzi, and Irene Ricci, 167–188. Milano: Officinaventuno.
-
Gili Fivela, Barbara, Cinzia Avesani, Marco Barone, Giuliano Bocci, Claudia Crocco, Mariapaola D’Imperio, Rosa Giordano, Giovanna Marotta, Michelina Savino, and Patrizia Sorianello. 2015. Intonational phonology of the regional varieties of Italian. In Intonation in Romance, eds. Sonia Frota and Pilar Prieto, 140–197. New York: Oxford University Press.
-
Giorgi, Alessandra. 2015. Discourse and the syntax of the left periphery. In Discourse oriented syntax, eds. Josef Bayer, Roland Hinterhölzl, and Andreas Trotzke, 229–250. Amsterdam: Benjamins.
-
Goodall, Grant. 2021. Sentence acceptability experiments: What, how, and why. In The Cambridge handbook of experimental syntax, ed. Grant Goodall, 7–38. Cambridge: Cambridge University Press.
-
Grice, Martine, Michelina Savino, and Mario Refice. 1997. The intonation of questions in Bari Italian: Do speakers replicate their spontaneous speech when reading? In Phonus 3, eds. Wiliam Barry and Jacques Koreman, 1–7. Institute of Phonetics, University of the Saarland.
-
Hamblin, Charles Leonard. 1973. Questions in Montague English. Foundations of Language 10:41–53.
-
Howell, Anna, Vera Hohaus, Polina Berezovskaya, Konstantin Sachs, Julia Braun, Şehriban Durmaz, and Sigrid Beck. 2022. (No) variation in the grammar of alternatives. Linguistic Variation 22(1):1–77.
-
JASP Team. 2023. JASP (Version 0.18.0). Computer Software. https://jasp-stats.org/.
-
Jiménez-Fernández, Ángel. 2015. When focus goes wild: An empirical study of two syntactic positions for information focus. Linguistics: Beyond and Within 1:119–133. https://doi.org/10.31743/lingbaw.5627.
-
Jones, Michael. 1993. Sardinian syntax. London: Routledge.
-
Kamali, Beste, and Manfred Krifka. 2020. Focus and contrastive topic in questions and answers, with particular reference to Turkish. Theoretical Linguistics 46(1–2):1–71.
-
Keating, Gregory, and Jill Jegerski. 2015. Experimental designs in sentence processing research. Studies in Second Language Acquisition 37(1):1–32.
-
Kehl, Andreas. 2023. Adjunct islands in English: Theoretical perspectives and experimental evidence. Berlin: de Gruyter.
-
Krifka, Manfred. 2008. Basic notions of information structure. Acta Linguistica Hungarica 55(3):243–276.
-
Lau, Jay Hau, Alexander Clark, and Shalom Lappin. 2017. Grammaticality, acceptability, and probability: A probabilistic view of linguistic knowledge. Cognitive Science 41:1202–1241.
-
Leusen, Noor Van. 2004. Incompatibility in context: A diagnosis of correction. Journal of Semantics 21(4):415–441.
-
McCloskey, James. 2006. Questions and questioning in a local English. In Crosslinguistic research in syntax and semantics: Negation, tense, and clausal architecture, eds. Raffaella Zanuttini, Héctor Campos, Elena Herburger, and Paul Portner, 87–126. Washington: Georgetown University Press.
-
Myers, James. 2017. Acceptability judgments. Oxford: Oxford University Press.
-
Neeleman, Ad, and Hans van de Koot. 2008. Dutch scrambling and the nature of discourse templates. Journal of Comparative Germanic Linguistics 11(2):137–189.
-
Neeleman, Ad, and Hans van de Koot. 2010. Information-structural restrictions on A’ -scrambling. The Linguistic Review 27:365–385.
-
Neeleman, Ad, and Reiko Vermeulen. 2012. The syntactic expression of information structure. In The syntax of topic, focus, and contrast: An interface-based approach, eds. Ad Neeleman and Reiko Vermeulen, 1–38. Berlin: de Gruyter.
-
Neeleman, Ad, Elena Titov, Hans van de Koot, and Reiko Vermeulen. 2009. A syntactic typology of topic, focus and contrast. In Alternatives to cartography, eds. Henk van Riemsdijk, Jan Koster, and Harry van der Hulst. Vol. 100, 15–52. Berlin: de Gruyter.
-
Rizzi, Luigi. 1997. The fine structure of the left periphery. In Elements of grammar: Handbook in generative syntax, ed. Liliane Haegeman, 281–337. Dordrecht: Kluwer.
-
Rizzi, Luigi. 2001. On the position of Int(errogative) in the left periphery of the clause. In Current studies in Italian syntax offered to Lorenzo Renzi, eds. Guglielmo Cinque and Giampaolo Salvi, 70–107. Amsterdam: Elsevier.
-
Rizzi, Luigi. 2004. Locality and the left periphery. In Structures and beyond: The cartography of syntactic structures, ed. Adriana Belletti. Vol. 3, 223–251. Oxford: Oxford University Press.
-
Rizzi, Luigi. 2024. On the status of criterial markers in the left periphery of the clause. In Cartography and explanatory adequacy, eds. Ángel Gallego and Dennis Ott, 198–219. Oxford: Oxford University Press.
-
Rizzi, Luigi, and Giuliano Bocci. 2017. The left periphery of the clause – primarily illustrated for Italian. In Blackwell companion to syntax, II edition, eds. Martin Everaert, and Henk van Riemsdijk, 1–30. Oxford: Blackwell Publishing.
-
Rizzi, Luigi, and Guglielmo Cinque. 2016. Functional categories and syntactic theory. In Annual review of linguistics, eds. Mark Liberman and Barbara Partee. Vol. 2, 139–163. Palo Alto: Annual Reviews.
-
Rooth, Mats. 1985. Association with Focus, PhD Thesis, University of Massachusetts at Amherst, MA, USA.
-
Rooth, Mats. 1992. A theory of focus interpretation. Natural Language Semantics 1(1):75–116.
-
Rooth, Mats. 2016. Alternative semantics. In The Oxford handbook of information structure, eds. Shinichiro Ishihara and Caroline Fery, 19–40. Oxford: Oxford University Press.
-
Samek-Lodovici, Vieri. 2015. The interaction of focus, givenness, and prosody. A study of Italian clause structure. Oxford: Oxford University Press.
-
Samek-Lodovici, Vieri. 2024a. Focalization in situ vs focus projection focused topics, focused questions, focused heads, and other challenges. In Cartography and explanatory adequacy, eds. Ángel Gallego and Dennis Ott, 218–248. Oxford: Oxford University Press.
-
Samek-Lodovici, Vieri. 2024b. Dataset for the corrective questions experiment run on Gorilla in July-September 2023. University College London. Dataset. https://rdr.ucl.ac.uk/articles/dataset/Dataset_for_the_Corrective_Questions_experiment_run_on_Gorilla_in_July-September_2023_/24231748.
-
Samek-Lodovici, Vieri. To appear. Correctively Focused Hanging Topics. In The Oxford Handbook of Syntactic Cartography, ed. Sam Wolfe. Oxford: Oxford University Press.
-
Samek-Lodovici, Vieri, and Karen Dwyer. 2024. Experimental testing of focus fronting in British English. In On the role of contrast in information structure, eds. Jorina Brysbaert and Karen Lahousse, 21–40. Berlin: de Gruyter.
-
Savino, Michelina. 2012. The intonation of polar questions in Italian: Where is the rise? Journal of the International Phonetic Association 42(1):23–48. Cambridge: Cambridge University Press.
-
Schütze, Carson. 2019. The empirical base of linguistics: Grammaticality judgments and linguistic methodology. Vol. 2 of Classics in linguistics. Berlin: Language Science Press.
-
Schwabe, Kerstin. 2007. Interrogative complement clauses. In On information structure, meaning and form, eds. Kerstin Schwabe and Susanne Winkler, 425–446. Amsterdam: Benjamins.
-
Seguin, Luisa. 2023. Clause-internal wh-words are actually fronted: Evidence from Valdôtain Patois. MD, USA. Qualifying paper to advance to PhD candidacy. University of Maryland.
-
Seguin, Luisa. To appear. The (in)compatibility of wh and focus in root and embedded questions in Romance and beyond. In The Oxford Handbook of Syntactic Cartography, ed. Sam Wolfe. Oxford: Oxford University Press.
-
Simons, Mandy. 2007. Observations on embedding verbs, evidentiality, and presupposition. Lingua 117(6):1034–1056.
-
Skopeteas, Stavros, and Gisbert Fanselow. 2011. Focus and the exclusion of alternatives: On the interaction of syntactic structure with pragmatic inference. Lingua 121(11):1693–1706.
-
Spitzer, Michaela, Ian Wildenhain, Juri Rappsilber, and Mike Tyers. 2014. BoxPlotR: A web tool for generation of box plots. Nature Methods 11:121–122.
-
Sprouse, Jon. 2007. A Program for Experimental Syntax: Finding the relationship between acceptability and grammatical knowledge, PhD Thesis, University of Maryland, MD, USA.
-
Sun, Yangyu. 2021. The Syntax of Right Dislocation in Mandarin Chinese and Italian, a Comparative Study, PhD Thesis, University of Padova, Italy.
-
Wagner, Michael. 2012. Contrastive topics decomposed. Semantics and Pragmatics 5:1–54.
Acknowledgements
This paper has significantly benefited from the insightful comments of several colleagues. I am particularly grateful for the invaluable help I received from the participants to the Questions at the Interfaces Workshop of June 2023 at Konstanz University (funded by the DFG, FOR2111 research unit); very special thanks for their kindness, time, and excellent advice to Veneeta Dayal, María Biezma, Donka Farkas, Rebecca Woods, Maribel Romero, Regine Eckardt, Edgar Onea-Gaspar, and also to all the speakers, as I learnt a great deal from your talks. I am also grateful for the insightful questions and comments I received at the 53rd Linguistic Symposium on Romance Languages held in Paris in 2023, with special thanks to Lisa Brunetti, Giuliano Bocci, Silvio Cruschina, Elena Callegari, Luisa Seguin, and Stefano Castiglione. My grateful thanks also to Karen Dwyer, Giacomo Presotto, and Tommaso Mattiuzzi for their helpful comments on experimental design and running experiments online. Finally, my thanks to three anonymous NLLT reviewers and the handling editor of this paper; the revisions you proposed greatly enhanced it.
Ethics declarations
Competing Interests
The author declares no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and permissions
About this article
Cite this article
Samek-Lodovici, V. On corrective questions and the position of focus. Nat Lang Linguist Theory (2025). https://doi.org/10.1007/s11049-025-09656-6
- Received
- Accepted
- Published
- DOI https://doi.org/10.1007/s11049-025-09656-6
Keywords
- Corrective focus
- Left periphery
- Focalization in-situ
- Corrective questions
- Canonical questions
- Contrast
- Focus fronting