Article Content
Abstract
fake news detection; cross-modal fusion; information enhancement; social relations; information theory
1. Introduction

-
We propose a novel Semantic-enhanced Cross-modal Co-attention Network for multimodal fake news detection, which focuses on utilizing the entity features for semantic enhancement and exploring the social relation graph.
-
We narrow the gap between different modalities by combining the entities and semantics of different modalities. In addition, we introduce self-supervised learning along with co-attention mechanisms for denoising, ultimately enhancing news semantics.
-
We introduce social relations as the structural features and design an improved GAT to process the social relation graph, thereby improving the representations from learning social relation graphs through enhanced neighborhood aggregation.
2. Related Studies
3. Approach

3.1. Data Preparation
After that, we use the cosine similarity to calculate the similarity coefficient 𝛼𝑖𝑗 between nodes 𝑛𝑖 and 𝑛𝑗, as follows:
where 𝑏𝑖 and 𝑏𝑗 denote the embeddings of nodes 𝑛𝑖 and 𝑛𝑗, respectively.
Based on the findings of a previous study [10], we argue that if there is currently no link between nodes, the potential link may exist if the similarity coefficient is above 0.5. Moreover, if there is already a link between nodes, this link can be regarded as noise if the similarity coefficient is below 0.2. This can be formulated as follows:
where 𝛿𝑖𝑗 is a transition variable that measures the similarity between nodes 𝑛𝑖 and 𝑛𝑗.
Next, we improve the original adjacency matrix A based on 𝛿𝑖𝑗, i.e., removing the noisy links and adding the potential links, which can be formulated as follows:
where 𝑎𝑖𝑗 and 𝑎′𝑖𝑗 are the elements in the initial and improved adjacency matrices A and 𝐴′, respectively.
3.2. Information Extraction and Feature Encoding
3.2.1. Text and Image Representations
Subsequently, we extract the feature vectors from the text and image using the respective encoders. Specifically, we utilize the pretrained BERT [27] and ResNet-50 [28] as the encoders for text and image, respectively. However, the length of the text generally varies for different news stories. Therefore, to facilitate subsequent operations, we set the text of different news to be of the same length, i.e., L, through padding or truncating, which can be denoted as follows:
where d is the dimension of the word embeddings and 𝒯𝑖 is the text embedding of the i-th news item, which consists of L word embeddings.
Next, this embedding sequence is fed into Bi-LSTM [29] to obtain the text feature vector 𝑎𝑇, as follows:
where 𝑊𝑇 is the learnable weight matrix and 𝑏𝑇 is the bias vector.
For the image, we extract the output of the second-last layer of ResNet-50 [28] and subsequently feed it through a fully connected layer to generate a feature vector 𝑎𝐼 with the same dimensions as the text feature 𝑎𝑇. This can be formulated as
where 𝑅𝐼 is the output of the second-last layer of ResNet-50 and 𝑊𝐼 is the weight matrix of the fully connected layer.
3.2.2. Social Relation Graph Representation

-
Attention Weight
Specifically, for node 𝑛𝑖 and its set of neighbor nodes 𝒩𝑖={𝑛1𝑖,𝑛2𝑖,…,𝑛𝑘𝑖} in graph 𝒢′, we first calculate the attention weights ℰ𝑖={𝜀1𝑖,𝜀2𝑖,…,𝜀𝑘𝑖}, where the element 𝜀𝑘𝑖∈ℰ denotes the attention weight between 𝑛𝑖 and 𝑛𝑘𝑖. In detail, it can be seen in Figure 3 that we integrate two common attention mechanisms of the traditional GAT, i.e., the single-layer neural network and the dot product [30]. This can be formulated as
where ‖ is the concatenation operation, 𝑎̃ is a parameter in the single-layer neural network, W is a learnable weight matrix, and 𝑏𝑖 and 𝑏𝑘 are the embeddings of node 𝑛𝑖 and its neighbor node 𝑛𝑘𝑖∈𝒩𝑖, respectively.
-
Attention Coefficient
As a result, inspired by [17], we introduce a sign mechanism to correctly handle the positive and negative relations between nodes. In detail, we obtain ℰ̃𝑖 after taking the opposite number of attention weights ℰ𝑖 for node 𝑛𝑖, i.e., ℰ̃𝑖=−ℰ𝑖={𝜀̃1𝑖,𝜀̃2𝑖,…,𝜀̃𝑘𝑖}. Afterwards, normalization is implemented with the softmax function for the two attention weights ℰ𝑖 and ℰ̃𝑖 to obtain the corresponding attention coefficients. This can be formulated as follows:
where 𝜙𝑗𝑖∈𝛷𝑖 and 𝜙̃𝑗𝑖∈𝛷𝑖′ are the two attention coefficients.
-
Graph Feature
To completely capture the interactions between nodes, we obtain the weighted aggregation of the neighbor nodes of 𝑛𝑖 with 𝛷𝑖 and Φ𝑖′, respectively. Subsequently, the above vectors are concatenated and fed into a fully connected layer to obtain the final vector representation of node 𝑛𝑖. Note that we utilize multihead attention in order to adapt to the complex graph structure in this process. This allows the model to fully take into account the correlation and importance between different nodes, resulting in improved expressive ability. The multihead attention can be formulated as follows:
where K is the number of heads, 𝜎 is the activation function, 𝑊𝑘 is the weight matrix of the fully connected layer of the k-th head, and 𝐵𝑖 is the embedding matrix of the neighbor nodes.
To this point, the final embeddings of all nodes are calculated by Equation (9) and denoted as the node embedding matrix 𝐵′. Finally, the multihead attention mechanism [31] is employed to acquire the features of the social relation graph as follows:
where K is the number of heads and the i-th column of G denotes the graph feature of the i-th news item.
3.3. Information Enhancement and Cross-Modal Fusion
In this section, we perform information enhancement and cross-modal fusion using the feature vectors obtained from Section 3.2 for text, image, and the social relation graph. For the feature vectors of the text and images, we use their entity embeddings to implement self-information enhancement. Specifically, taking an image as an example, we concatenate 𝑎𝐼 and 𝑒𝐼 before feeding them into a multilayer perceptron to obtain the information-enhanced feature vector 𝑍𝐼. Moreover, the information-enhanced feature vector 𝑍𝑇 of the text can be calculated in the same way. For the social relation graph, we acquire the feature vector 𝑍𝑅 with the same dimension as 𝑍𝐼 by feeding G into a multilayer perceptron [31]. This can be formulated as
where 𝜎 is the activation function, 𝑊′𝐼, 𝑊′𝑇, and 𝑊′𝑅 are the learnable weights matrix, and 𝑏′𝐼, 𝑏′𝑇, and 𝑏′𝑅 are the bias vectors.
It cannot be ignored that performing the cross-modal fusion operations inevitably causes intrinsic loss of information between modalities, which should be intrinsic to the representation of different modalities in the original news story. This leads to the features extracted from disparate modalities potentially exhibiting substantial semantic gaps. To address this issue, a novel cross-modal alignment with self-supervised loss is introduced to refine the feature representations. For example, we map the produced feature vectors 𝑍𝐼 and 𝑍𝑇 to the same semantic space as, follows:
where 𝑊𝐼^ and 𝑊𝑇^ are the learnable parameters. After this, we adopt the MSE loss to narrow the distance between 𝑍𝐼^ and 𝑍𝑇^:
where n is the total number of news stories.
Similarly, we can map 𝑍𝑇 and 𝑍𝑅 along with 𝑍𝐼 and 𝑍𝑅 to the same semantic space and calculate their MSE loss as ℒ𝑇𝑅𝑎𝑙𝑖𝑔𝑛 and ℒ𝐼𝑅𝑎𝑙𝑖𝑔𝑛, respectively. Then, we add the above three losses to obtain the final loss of the cross-modal alignment, as follows:
Then, we can produce the cross-modal feature 𝑓𝑇𝐼 between the text and images, calculated as follows:
where 𝑊𝑇𝐼 represents the linear transformation matrix.
However, it is evident that 𝑓𝑇𝐼 is actually the visual feature enhanced by a textual feature, which does not fully reflect the characteristics and relations between the two modalities. Therefore, we exchange the representation of text and image in Equation (15) to obtain another cross-modal feature 𝑓𝐼𝑇, which is the textual feature enhanced by the visual feature. For the other two groups of modalities, we obtain the mutually reinforced cross-modal features in the same way. For convenience of distinction, we denote these as 𝑓𝑇𝑅, 𝑓𝑅𝑇, 𝑓𝐼𝑅, and 𝑓𝑅𝐼, respectively. Finally, we concatenate them as the final multimodal fusion feature, as follows:
3.4. Optimization and Classification
In the optimization and classification module, we feed the final multimodal fusion feature Z into a fully connected layer to predict the labels of news stories, as follows:
where 𝑦̂ denotes the predicted scores.
In our model, the entropy can be used to measure the dispersion and uncertainty of the experimental results. In the proposed framework, high entropy reflects significant divergence between detection results and ground-truth labels, whereas low entropy indicates stable convergence. Information theory offers quantitative frameworks for three critical aspects of probabilistic systems: entropy for uncertainty assessment, KL divergence for distributional differences, and mutual information for dependency measurement. Inspired by the theoretical understanding of entropy in information theory, we adopt the cross-entropy loss function as the loss function for this binary classification problem. The optimization strategy of SCCN explicitly targets entropy minimization through cross-modal feature learning, as follows:
where y indicates the ground truth of the fake news detection label.
Considering that cross-modal alignment is conducted to narrow the semantic gaps between modalities, the generated loss may contribute less to the final classification. Thus, we introduce two parameters, 𝜆𝑎 and 𝜆𝑏, to respectively regulate ℒ𝑐𝑙𝑠 and ℒ𝑎𝑙𝑖𝑔𝑛 in the total loss function. We then combine ℒ𝑐𝑙𝑠 and ℒ𝑎𝑙𝑖𝑔𝑛 to compute the final loss function of SCCN, as follows:
More details of the PGD are provided in Algorithm 1. Specifically, in this algorithm, 𝑠𝑖𝑔𝑛(𝑔) is a function that returns the sign of the gradient g, indicating the direction in which the input should be perturbed in order to maximize the loss. Moreover, 𝑐𝑙𝑖𝑝 and 𝑝𝑟𝑜𝑗𝑒𝑐𝑡 are functions which respectively ensure that the perturbations are within acceptable bounds and that the perturbed inputs are projected back into the valid data space.
| Algorithm 1 Procedure of PGD |
|
4. Experiments
4.1. Datasets

4.2. Baselines
-
EANN [2]: EANN utilizes a cross-modal feature extractor and a fake posts detector to support fake news detection, which can derive event-invariant features that make it easier to detect newly emerging events.
-
MVAE [1]: MVAE uses a bimodal variational auto-encoder to model images and text in order to achieve classification.
-
QSAN [17]: QSAN incorporates quantum-driven text encoding along with a signing mechanism within its framework, which can utilize conflicting information to provide clues for detection. In addition, this method is interpretable.
-
SAFE [15]: SAFE is a fake news detection approach that emphasizes the similarity between textual and visual content more than other methods.
-
EBGCN [21]: EBGCN identifies unreliable relationships existing in rumors and enables the detection of fake news by training an edge consistency framework.
-
GLAN [13]: GLAN is a global–local network that captures structural information for fake news detection by jointly coding global and local information.
-
MPFN [5]: MPFN is able to recognize the level of information represented in the different modalities and use this to build a strong hybrid modality.
-
KMAGCN [22]: KMAGCN is an adaptive graph convolutional network that converts posts into graphs to capture discontinuous semantic relations.
-
MFAN [10]: MFAN introduces the element of comments in posts while considering the complement and alignment between different modalities for better integration.
4.3. Implementation Details
5. Results and Discussion
5.1. Overall Performance
5.2. Ablation Study
5.2.1. Effect of Modules
-
Comparing the four variants of SCCN, we find that the SCCN w/o DPS, SCCN w/o SRG, and SCCN w/o IEM variants all show obvious performance drops, indicating that introducing data processing, social relations, and information enhancement strengthens the performance of our model. From an information-theoretic perspective, greater performance degradation indicates higher uncertainty and entropy in the variants, demonstrating enhanced effectiveness of our model architecture when incorporating the proposed modules. Moreover, the results of the ablation study indicate that combining text, images, and social relations can facilitate cross-modal feature fusion in a way that is crucial for fake news detection.
-
The performance decrease for the SCCN w/o CMF variant proves that the cross-modal fusion module implemented with the co-attention mechanism helps to improve the performance of our model. Furthermore, all variants show similar performances on both the PHEME and Weibo datasets, while the complete SCCN model performs better on Weibo than PHEME dataset, demonstrating that these modules play a greater role in the Weibo dataset.
5.2.2. Effects of Different Types of Modal Embeddings

5.3. Quantitative Analysis

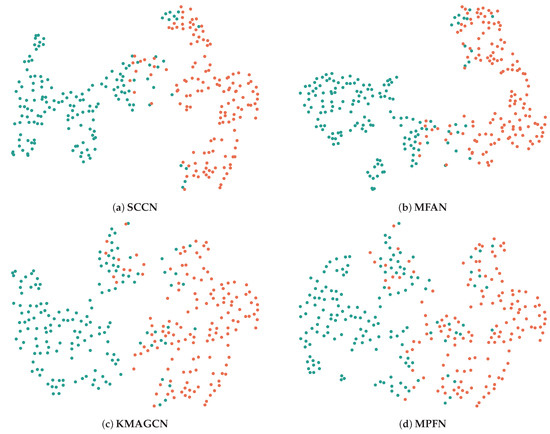
5.4. Convergence Analysis

5.5. Parameter Analysis
5.5.1. Length of Text
5.5.2. Size of the Convolution Kernel

5.6. Case Studies

6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khattar, D.; Goud, J.S.; Gupta, M.; Varma, V. MVAE: Multimodal Variational Autoencoder for Fake News Detection. In Proceedings of the WWW’19: The Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2915–2921. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, F.; Jin, Z.; Yuan, Y.; Xun, G.; Jha, K.; Su, L.; Gao, J. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In Proceedings of the KDD’18: The 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 849–857. [Google Scholar] [CrossRef]
- Islam, M.S.; Sarkar, T.; Khan, S.H.; Kamal, A.H.M.; Hasan, S.M.; Kabir, A.; Yeasmin, D.; Islam, M.A.; Chowdhury, K.I.A.; Anwar, K.S.; et al. COVID-19–related infodemic and its impact on public health: A global social media analysis. Am. J. Trop. Med. Hyg. 2020, 103, 1621. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Wu, Y.B. Early Detection of Fake News on Social Media Through Propagation Path Classification with Recurrent and Convolutional Networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 354–361. [Google Scholar] [CrossRef]
- Jing, J.; Wu, H.; Sun, J.; Fang, X.; Zhang, H. Multimodal fake news detection via progressive fusion networks. Inf. Process. Manag. 2023, 60, 103120. [Google Scholar] [CrossRef]
- Yu, C.; Ma, Y.; An, L.; Li, G. BCMF: A bidirectional cross-modal fusion model for fake news detection. Inf. Process. Manag. 2022, 59, 103063. [Google Scholar] [CrossRef]
- Tseng, Y.; Yang, H.; Wang, W.; Peng, W. KAHAN: Knowledge-Aware Hierarchical Attention Network for Fake News detection on Social Media. In Proceedings of the WWW’22: The ACM Web Conference 2022 Virtual Event (Companion Volume), Lyon, France, 25–29 April 2022; pp. 868–875. [Google Scholar] [CrossRef]
- Wu, Y.; Zhan, P.; Zhang, Y.; Wang, L.; Xu, Z. Multimodal Fusion with Co-Attention Networks for Fake News Detection. In Proceedings of the ACL/IJCNLP (Findings); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2560–2569. [Google Scholar] [CrossRef]
- Liu, P.; Qian, W.; Xu, D.; Ren, B.; Cao, J. Multi-Modal Fake News Detection via Bridging the Gap between Modals. Entropy 2023, 25, 614. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Zhang, X.; Guo, S.; Wang, Q.; Zang, W.; Zhang, Y. MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection. In Proceedings of the IJCAI, Vienna, Austria, 23–29 July 2022; pp. 2413–2419. [Google Scholar] [CrossRef]
- Hu, L.; Yang, T.; Zhang, L.; Zhong, W.; Tang, D.; Shi, C.; Duan, N.; Zhou, M. Compare to The Knowledge: Graph Neural Fake News Detection with External Knowledge. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 754–763. [Google Scholar] [CrossRef]
- Li, P.; Sun, X.; Yu, H.; Tian, Y.; Yao, F.; Xu, G. Entity-Oriented Multi-Modal Alignment and Fusion Network for Fake News Detection. IEEE Trans. Multim. 2022, 24, 3455–3468. [Google Scholar] [CrossRef]
- Yuan, C.; Ma, Q.; Zhou, W.; Han, J.; Hu, S. Jointly Embedding the Local and Global Relations of Heterogeneous Graph for Rumor Detection. In Proceedings of the ICDM, Beijing, China, 8–11 November 2019; pp. 796–805. [Google Scholar] [CrossRef]
- Yang, X.; Lyu, Y.; Tian, T.; Liu, Y.; Liu, Y.; Zhang, X. Rumor Detection on Social Media with Graph Structured Adversarial Learning. In Proceedings of the IJCAI, Yokohama, Japan, 7–15 January 2021; pp. 1417–1423. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, J.; Zafarani, R. SAFE: Similarity-Aware Multi-modal Fake News Detection. In Advances in Knowledge Discovery and Data Mining, PAKDD 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12085, pp. 354–367. [Google Scholar] [CrossRef]
- Wei, Z.; Pan, H.; Qiao, L.; Niu, X.; Dong, P.; Li, D. Cross-Modal Knowledge Distillation in Multi-Modal Fake News Detection. In Proceedings of the ICASSP, Singapore, 23–27 May 2022; pp. 4733–4737. [Google Scholar] [CrossRef]
- Tian, T.; Liu, Y.; Yang, X.; Lyu, Y.; Zhang, X.; Fang, B. QSAN: A Quantum-probability based Signed Attention Network for Explainable False Information Detection. In Proceedings of the CIKM, Virtual, 19–23 October 2020; pp. 1445–1454. [Google Scholar] [CrossRef]
- Chen, Y.; Li, D.; Zhang, P.; Sui, J.; Lv, Q.; Lu, T.; Shang, L. Cross-modal Ambiguity Learning for Multimodal Fake News Detection. In Proceedings of the WWW, Virtual, 25–29 April 2022; pp. 2897–2905. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, C.; Xu, H.; Xu, Y.; Xu, X.; Wang, S. Cross-modal Contrastive Learning for Multimodal Fake News Detection. In Proceedings of the ACM Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 5696–5704. [Google Scholar] [CrossRef]
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. dEFEND: Explainable Fake News Detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, 4–8 August 2019; pp. 395–405. [Google Scholar] [CrossRef]
- Wei, L.; Hu, D.; Zhou, W.; Yue, Z.; Hu, S. Towards Propagation Uncertainty: Edge-enhanced Bayesian Graph Convolutional Networks for Rumor Detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3845–3854. [Google Scholar] [CrossRef]
- Qian, S.; Hu, J.; Fang, Q.; Xu, C. Knowledge-aware Multi-modal Adaptive Graph Convolutional Networks for Fake News Detection. ACM Trans. Multim. Comput. Commun. Appl. 2021, 17, 98:1–98:23. [Google Scholar] [CrossRef]
- Ma, X.; Wu, J.; Xue, S.; Yang, J.; Zhou, C.; Sheng, Q.Z.; Xiong, H.; Akoglu, L. A Comprehensive Survey on Graph Anomaly Detection With Deep Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 12012–12038. [Google Scholar] [CrossRef]
- Kim, D.; Oh, A. How to Find Your Friendly Neighborhood: Graph Attention Design with Self-Supervision. arXiv 2021, arXiv:2204.04879. [Google Scholar] [CrossRef]
- Huang, Y.; Gao, M.; Wang, J.; Yin, J.; Shu, K.; Fan, Q.; Wen, J. Meta-prompt based learning for low-resource false information detection. Inf. Process. Manag. 2023, 60, 103279. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, J.Z.J.; Yao, S.; Wang, R.; Du, H. TLFND: A Multimodal Fusion Model Based on Three-Level Feature Matching Distance for Fake News Detection. Entropy 2023, 25, 1533. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chen, M.; Lai, Y.; Lian, J. Using Deep Learning Models to Detect Fake News about COVID-19. ACM Trans. Internet Technol. 2023, 23, 25:1–25:23. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. arXiv 2019, arXiv:1908.02265. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2018, arXiv:1706.06083. [Google Scholar] [CrossRef]
- Zubiaga, A.; Liakata, M.; Procter, R. Exploiting Context for Rumour Detection in Social Media. In Social Informatics. SocInfo 2017. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10539, pp. 109–123. [Google Scholar] [CrossRef]
- Song, C.; Yang, C.; Chen, H.; Tu, C.; Liu, Z.; Sun, M. CED: Credible Early Detection of Social Media Rumors. IEEE Trans. Knowl. Data Eng. 2021, 33, 3035–3047. [Google Scholar] [CrossRef]
- Liu, K.; Xue, F.; Guo, D.; Sun, P.; Qian, S.; Hong, R. Multimodal Graph Contrastive Learning for Multimedia-Based Recommendation. IEEE Trans. Multim. 2023, 25, 9343–9355.