Article Content
Abstract
Demonstratives can be used to locate a referent in space but they can also be used to refer to discourse referents located in the common ground. In English, proximal demonstratives are used for novel referents (indefinite specific this) while distal that can be used to refer to familiar referents. The empirical goal of this paper is to explore whether a similar pattern is found in other languages. To this end, we explored the use of demonstratives in 22 languages and found that this correlation is robust: if demonstratives are used for both spatial and grounding purposes, it is always the proximal demonstrative that is used for novel discourse referents and the distal demonstrative that is used for familiar discourse referents. The cross-linguistic solidity of this ‘Spatial-Grounding Correlation’, invites the conclusion that it is grammatically conditioned. We develop an analysis according to which the grounding use of spatial demonstratives is syntactically derived, utilising the Nominal Interactional Structure, independently motivated in Ritter and Wiltschko (2018, 2019, 2024).
Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.
- Applied Linguistics
- Comparative Linguistics
- Corpus Linguistics
- Linguistic Anthropology
- Linguistics
- Sociolinguistics
1 Introduction
The goal of this paper is to describe and analyse a curious generalisation regarding the multifunctionality of demonstratives from a cross-linguistic perspective. Specifically, it is well-known that demonstratives which are used to point out a close (proximal) entity in space (English this; (1a)) can also be used in a non-spatial way, namely to introduce novel discourse referents, as in (2). Similarly, demonstratives which can be used to point out distant entities in space (English that; (1b)) can also be used to refer to familiar discourse referents, as in (3).Footnote1



To the best of our knowledge, the opposite pattern is not attested, as shown in (4): proximal demonstratives cannot be used for familiar discourse referents (4a), while distal ones cannot be used for novel ones (4b).

We refer to this generalisation regarding the multifunctionality of demonstratives as the Spatial-Grounding Correlation (SGC), summarised in Table 1.
The empirical goal of this paper is to explore the cross-linguistic validity of the SGC. In particular, we will establish that the SGC is categorical: across many unrelated languages we observe the same unique directional correlation. The theoretical goal of this paper is to argue that the grounding use of demonstratives is syntactically conditioned.
The paper is organised as follows. In Sect. 2, we describe the patterns of multifunctionality of demonstratives in more detail to motivate our research questions. In Sect. 3, we introduce our methodology for cross-linguistic comparison. In Sect. 4, we discuss the data that emerge as a result of our empirical investigation, which includes 22 languages from different families. We observe that even in languages with different demonstrative systems, the SGC is never violated. Hence, we conclude that the SGC cannot be a coincidence. In Sect. 5, we develop a syntactic analysis to derive the SGC. Finally, in Sect. 6 we draw some conclusions and discuss questions for future research.
2 The multifunctionality of demonstratives
It is well-established from a typological perspective that demonstratives are universal (Diessel 1999). What is also well-known is that they are typically multifunctional (Halliday and Hasan 1976; Lyons 1977; Levinson 1983, 85–89; Webber 1991; Fillmore 1997; Himmelmann 1997; Diessel 1999). The purpose of this section is to describe this multifunctionality of demonstratives in more detail. In Sect. 2.1, we describe the core spatial uses of demonstratives (henceforth, spatial demonstratives): they are used to locate the referent in the deictic space. In Sect. 2.2, we describe the use of demonstratives as locating referents in the common ground (henceforth, grounding demonstratives). In Sect. 2.3, we introduce the research questions that arise from this multifunctionality.
A note on terminology is in order. The distinction between spatial and grounding demonstratives cuts across the classic distinction between endophoric and exophoric demonstratives (Diessel 1999; i.a.). Exophoric demonstratives are the ones that refer to individuals present in the context; i.e., they correspond to our spatial demonstratives. In contrast, endophoric demonstratives are the ones which refer to discourse referents that have been established through linguistic antecedents or through their presence or absence in the common ground. Traditionally, these demonstratives are further subdivided into different subtypes: anaphoric, discourse deictic, and recognitional, as summarised in the schema in (5).
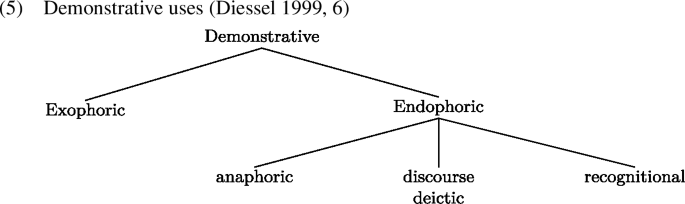
There is yet another demonstrative use, which is typically referred to as the ‘specific indefinite’ use (Prince 1981a, 233). Diessel (1999, 138–139) does not include this use in the sub-classification of demonstratives. This is because he analyses it as instantiating articles which have been grammaticalised from demonstratives. We depart from this classification and assume that even in their specific indefinite use, they instantiate demonstratives. In particular, we shall argue that they are grounding demonstratives. This proposal is based on the fact that they have the form of a demonstrative and not of an article and we consider morphosyntax to be the determining factor for categorical classification. This contrasts with Diessel (1999), who takes the indefinite interpretation to be the determining factor for his classification. As a piece of evidence in favour of his claim, Diessel (1999) reports data from the Urim language in (6).

While Diessel argues that the presence of the indefinite article ur in this sentence supports the idea that the demonstrative pa is an article, we disagree with this conclusion. Rather, based on the classic argument of complementary distribution, the non-complementarity of the indefinite article ur and the demonstrative pa suggests that they do not instantiate the same category.
In what follows, we discuss spatial demonstratives (§2.1) and grounding demonstratives, which are comprised of the recognitional and the specific indefinite use (§2.2). We also discuss how the anaphoric and discourse deictic uses differ from grounding demonstratives.
2.1 Spatial demonstratives
All demonstrative determiners we here consider (i.e., this and that and their variants in other languages) have spatial uses. Hence, we consider this use to constitute the core meaning of demonstrative determiners.Footnote2 In what follows, we refer to demonstrative determiners simply as demonstratives. Though crucially we do not mean to include other demonstrative forms, like demonstrative adverbials (here vs. there). Languages differ as to how the spatial use of demonstratives is anchored to the context. In some languages, the anchor is the utterance location, which creates a system that distinguishes between here (proximal) and there (distal). We have already seen English as an example of such a system in Sect. 1. Another type of system makes use of a three-way contrast anchored to the speech act participants. This yields a system that distinguishes close to Speaker (prox 1; (7a)), close to Addressee (prox 2; (7b)) and away from both Speaker and Addressee (distal; (7c)). This system is found in European Spanish:

Finally, there are also systems in which the demonstratives themselves do not vary according to the location of the referent. Rather, a spatially unspecified demonstrative is accompanied by a locative particle (sometimes referred to as the ‘reinforcer’; Roehrs 2010) to locate the referent in space. For instance, in French cette ci (8a) refers to referents close to the Speaker and the Addressee, and cette là (8b) to referents distant to both the Speaker and the Addressee.

In sum, what these patterns reveal is that there is a basic distinction between proximal and distal demonstratives that holds across all languages. However, languages differ in the way they encode this distinction: it can be marked with a demonstrative which intrinsically encodes the spatial contrast (henceforth, ‘intrinsic’ demonstratives; e.g., English), or it can be marked with an additional particle that encodes the spatial distinction (henceforth, the ‘locative particle’; e.g., French). The proximal vs. distal distinction can also arise through a person-oriented system where proximal can be either close to the Speaker or close to the Addressee.Footnote3 This is summarised in Table 2. Of note is the fact that, to the best of our knowledge, three-way systems are always intrinsic systems and are never derived via locative particles.Footnote4
Next, we turn to the grounding use of demonstratives, which has been previously observed but has not been systematically documented from a cross-linguistic perspective.
2.2 Grounding demonstratives
Grounding demonstratives differ from spatial demonstratives in that they do not refer to an individual who is physically present in the utterance context. Rather, they refer to referents in the mental worlds of the interlocutors, i.e., the (common) ground of the interlocutors. But they do so in different ways, as we now discuss.
Our notion of the ground derives from the Stalnakerian notion of the common ground (Stalnaker 2002). Modelling language as it unfolds during conversational interaction requires us to include reference to the knowledge-states of the interlocutors. This is because one of the goals of a conversation is to update the common ground. That is, we can use linguistic interaction to synchronise our minds. As we shall see, it is important to not only recognise the common ground of the interlocutors, but also the individual knowledge states of each interlocutor, since they may differ throughout the interaction. This is what we refer to as the individual grounds (Speaker’s Ground and Addressee’s Ground; see Wiltschko 2021 for discussion). Furthermore, what is crucial for the purpose of this paper is the fact that the grounds not only contain the propositions the interlocutors know, but also individuals and other inanimate/animate referents they know and/or have talked about. Crucially, an individual in the common ground can either be already established or not.
Grounding demonstratives serve the purpose to locate the referent in the Speaker and the Addressee’s Ground (which we refer to as the ‘common ground’). For example, if a referent is not already established in the common ground, it can be introduced via a demonstrative. This is known as the ‘indefinite specific’ use (Prince 1981a; see also Fodor and Sag 1982; Lambrecht 1994; Chafe 1994; Diessel 1999, 109). To see this consider the example in (9): the proximal demonstrative this introduces a new referent into the Addressee’s Ground. That is, at the time of utterance the hippie is only in the Speaker’s Ground but (the Speaker assumes that it is) not in the Addressee’s Ground.

In contrast, if the referent is already established in the common ground, it can be referred to with a distal demonstrative. There are two different ways in which a referent can already be established in the common ground: (i) through common knowledge, or (ii) through anaphoric reference.Footnote5 For instance, in (10) the distal demonstrative that refers to a dog which is known to both the Speaker and the Addressee. This is known as the ‘recognitional use’ of endophoric demonstratives (Auer 1981, 1984; Chen 1990; Gundel et al. 1993; Himmelmann 1996, 1997).
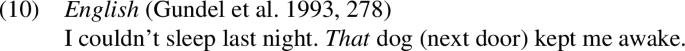
Note that in both cases, the recognitional use of that and the indefinite specific use of this, the referent has not been mentioned in the previous discourse. In other words, the recognitional and indefinite specific use are not anaphoric. However, it is well-known that demonstratives can be used anaphorically as well, i.e., when the referent has been previously mentioned (Diessel 1999, 96). There are two such anaphoric uses: demonstratives can be anaphoric to a previous nominal referent or to a previous propositional referent.
In this paper, we strictly focus on the recognitional and the indefinite specific uses for reasons we briefly discuss below. Everything else being equal, we might expect that the anaphoric use is always an instance of the familiar grounding use as the referent has been introduced. If so, based on the SGC, we would expect that it is always the distal demonstrative that instantiates the anaphoric use. However, we observe that both the spatial proximal and the distal demonstratives can be used in anaphoric contexts, as shown in (11) for German and (12) for Romanesco.Footnote6


We hypothesise that the possibility for both spatial proximal and distal demonstratives can be explained as follows. The spatial distal demonstrative used in grounding familiar contexts is predicted by the SGC because an anaphoric referent will always be familiar. As for the unexpected spatial proximal use, we suggest that it is a special kind of spatial use such that it refers back to the previous linearly preceding instance of the referent, as schematised below in (13). In contrast, the distal demonstrative refers to the familiar discourse referent in the common ground, as schematised in (14).
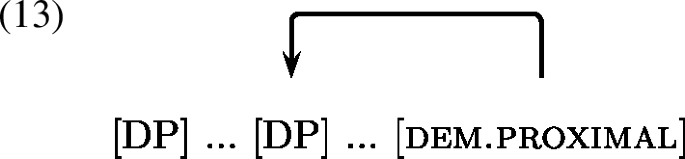
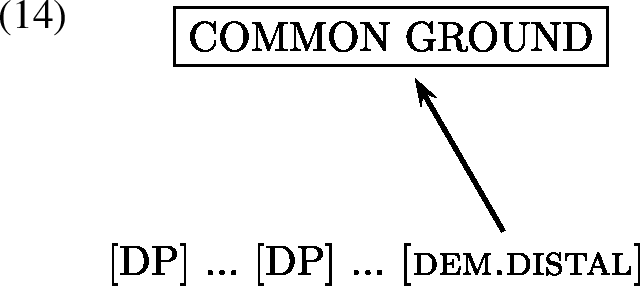
Note that this ambiguity never arises in the recognitional use because there is no previous mention of a referent and thus the spatial use is not available.
For completeness, note that there is independent evidence for the distinction between the spatial, the anaphoric, and the recognitional use of demonstratives. In its spatial use the noun can be omitted, and depending on whether the noun is overt or not, the form of the demonstrative changes in Romanesco. Specifically, quel is the form used when a noun follows, whereas quello is the form used in the absence of a noun, as shown in (15). In its anaphoric use, the presence of the overt noun is infelicitous, instead the demonstrative quello is used, as shown in (16). Crucially, in their recognitional use, the noun cannot be omitted, as shown in (17). See also Hinterwimmer and Bosch (2016) for German.



Similar considerations hold for demonstratives that anaphorically refer to a previously introduced proposition (i.e., Diessel’s (1999, 105) ‘discourse deictic’ use) (18a) or illocution as in ((18b); Lyons 1977; Himmelmann 1997; Fillmore 1997; Krifka 2013).Footnote7

Note that this anaphoric use abides by the SGC: that in (18) still refers to an old referent, even if it is a proposition. Interestingly, the proximal demonstrative this can be used cataphorically to refer to a proposition, as shown in (19).
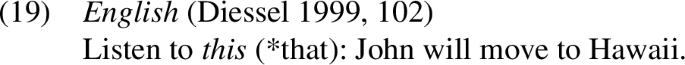
In what follows we set aside the anaphoric use of demonstratives, focusing on the recognitional and the indefinite specific use.
2.3 Introducing the research questions
The SGC raises the question as to whether the spatial deictic value of spatial demonstratives determines their grounding use. Note that the directionality of the SGC is somewhat unexpected, at least on intuitive grounds. One might expect proximal demonstratives to be used to refer to familiar discourse referents. After all, if a discourse referent is in the common ground it appears to be closer to the interlocutors.Footnote8 Given this unexpectedness, our first question is whether this pattern is an accidental quirk of English or whether it is also attested in other languages. To the best of our knowledge, to date there is no linguistic study on the empirical validity of SGC. However, investigating the SGC from a cross-linguistic perspective is crucial, especially given that different languages exhibit different spatial demonstrative systems, as we have seen in Sects. 2.1 and 2.2.
Specifically, the properties of demonstratives considered thus far lead us to the following research questions.
- 1.Does the SGC manifest itself in two-way and/or three-way demonstrative systems and, if so, how?
- 2.Does the SGC manifest itself in intrinsic and/or locative particle demonstrative systems and, if so, how?
We will show that the SGC is categorically valid in all demonstrative systems. However, we also observe some variation concerning the possibility to reuse spatial demonstratives as grounding demonstratives.Footnote9 We show that, if spatial demonstratives are reused as grounding demonstratives, they never violate the SGC. In three-way demonstrative systems most languages reuse the proximal 1st person demonstrative as discourse novel while one language reuses the proximal 2nd person demonstrative in this way (i.e., Croatian). Crucially, we never find languages in which the distal demonstrative is reused as a discourse novel demonstrative. Finally, we have found that only intrinsic demonstratives can be reused while locative particles are never found in grounding demonstratives. These findings justify the need for an analysis of the SGC and the range of variation attested across our language sample.
3 Methodology
To test the validity of the SGC and to answer our research questions, we collected data from several language families using conversation boards.Footnote10 Conversation board elicitation is modelled on the storyboard elicitation technique (Burton and Matthewson 2015) but it is modified in order to target conversations (Wiltschko 2021). This methodology has proven successful especially for eliciting semantic and pragmatically related data as it provides a visual aid for the context, and hence reduces the cognitive load for the consultant.Footnote11 We used this elicitation technique as a way to collect not only positive but also negative data. Thus, we asked our consultants not only how they would produce well-formed sentences but also to judge ill-formed ones so to obtain a complete set of data for each language. The relation among the different uses of demonstratives has been investigated mostly on the basis of corpus data and previous claims have not been supported by cross-linguistic data. Thus, pertaining to our research question, negative data on the one hand, and systematic cross-linguistic data on the other hand, are currently unavailable.
The data reported here have been collected with speaker linguists and naïve consultants through interviews conducted by the authors in the following languages: Barese (Italo-Romance), Catalan, Cepranese (Italo-Romance), Croatian, Dutch, English, European Portuguese, European Spanish, Greek, Irish, Japanese, Korean, Ktunaxa (isolate), Mandarin, Romanian, Standard French, Standard German, Standard Italian, Swabian German, and Tagalog.Footnote12 In some cases, additional contexts were introduced without conversation boards in order to clarify certain data points. In what follows, we introduce the conversation boards we used to elicit demonstratives in their spatial and grounding use, respectively, focusing on English as the target language.
3.1 Spatial demonstratives
To elicit the spatial deictic use of demonstratives we used the three conversation boards shown below.Footnote13 In each of these cases, the left panel illustrates the scene-setting for the conversation where the Speaker and the Addressee are highlighted, and the right panel illustrates the conversation with the target referent also being highlighted. We have considered three contexts for spatial deixis based on the fact that some languages make a three-way distinction in their demonstrative systems: close to Speaker, close to Addressee, away from both the Speaker and the Addressee. The conversation board in (20) is used to elicit the Speaker proximal demonstrative. In this context the referent (red-haired woman) is close to the Speaker and we observe the use of this rather than that in English.

The conversation board in (21) is used to elicit the Addressee proximal demonstrative. Since English does not have a three-way demonstrative system, unsurprisingly, English speakers differ as to whether they use this or that. This is shown in (21):

Finally, the conversation board in (22) is used to elicit the distal demonstrative. In this context, the referent is away from both the Speaker and the Addressee and this consistently elicited the use of that in English:

3.2 Grounding demonstratives
To collect data for the grounding use of demonstratives, we used two different conversation boards distinguishing between familiar and novel discourse referents. The conversation board in (23) is used to elicit novel uses. There are three panels: the first panel illustrates the situation leading up to the conversation, the second panel illustrates a flashback depicting the Speaker’s memory of the past, and in the third panel the conversation is depicted. The thought bubble indicates that the knowledge of the referent is not shared between the Speaker and the Addressee. Rather the referent (marked with a red arrow) is only known to the Speaker. In this context, English speakers have to use this rather than that.Footnote14

The conversation board in (24) is used to elicit demonstratives in their familiar use. Panel one illustrates the situation that establishes that the interlocutors have shared knowledge from the past. The second panel depicts the context of the conversation itself illustrating the shared knowledge by means of the thought bubble. In this context, the use of that is obligatory in English.

4 The Spatial-Grounding Correlation from a cross-linguistic perspective
The empirical goal of this paper is to address two questions: (i) Does the SGC hold cross-linguistically?, and (ii) What happens in languages which have spatial demonstrative systems that differ from the intrinsic two-way system found in English (i.e., systems with a three-way contrast and systems that use a locative particle)?
As can be seen in Table 3, in our sample of languages there is a fairly even distribution between intrinsic two-way systems (11 languages) and three-way systems (9 languages). However, we have only two languages which use two-way systems with locative particles. In what follows, we discuss the results of our fieldwork on the grounding use of spatial demonstratives across these 22 languages.
4.1 Intrinsic two-way demonstrative systems
Most of the languages in our dataset have an intrinsic two-way system pattern like English. That is, proximal demonstratives are used to refer to novel referents and distal demonstratives are used to refer to familiar referents (‘Pattern 1’). A second pattern for intrinsic two-way demonstrative systems (‘Pattern 2’) is characterised by the fact that the distal demonstrative is reused for grounding familiar referents. But, the proximal demonstrative cannot be reused for grounding novel referents. In other words, in such systems the proximal demonstrative does not have a grounding use. Instead, an existential strategy is used to introduce an Addressee-new referent, as illustrated in (25) for Connemara Irish and in (26) for Mandarin.


For completeness, note that in Pattern 1 languages the existential strategy, which is necessary in Pattern 2 languages, is also possible in addition to the use of the proximal demonstrative. This is illustrated in (27) for Standard Italian.

In Table 4, we summarise our findings for intrinsic two-way demonstrative systems.
4.2 One-way demonstrative systems with locative particles
Next we turn to languages which have no spatial contrast in their demonstrative forms, of which there are only two in our language sample: Standard French and Swabian German. Instead, the same demonstrative is used for proximal and distal referents, and the spatial location can (optionally) be indicated by a (locative) particle. As shown in Table 5, these languages still conform to the SGC. Both languages have in common that the locative particle is never used for grounding. Rather, only the demonstrative form is reused. However, the two languages differ whether they instantiate Pattern 1 and Pattern 2. Specifically, in Standard French the demonstrative including the locative particle cannot be used for grounding (28). However, since no deictic distinction is encoded in the determiner alone, it can be used for novel and for familiar referents.

In contrast, in Swabian German the demonstrative can be used for familiar referents, whereas for novel referents an existential strategy must be used as in (29a). Neither the spatial proximal nor the spatial distal particle can be used for grounding novel referents, as shown in (29b) and (29c).

In Table 5, we summarise our findings for two-way demonstrative systems with locative particles. For completeness, note that an existential strategy is also available in Standard French, as shown in (30).

4.3 Three-way demonstrative systems
Next we turn to three-way demonstrative systems. Given the SGC, the question arises as to which of the demonstratives is reused. Our fieldwork reveals three patterns. In all languages the distal demonstrative is reused for grounding familiar referents consistent with the SGC. The systems differ in regards to which demonstrative is used for grounding novel referents. Most languages use Speaker-oriented demonstratives for this purpose (Pattern 1a; this is exemplified based on European Spanish in (31)); while one language (i.e., Croatian) uses the Addressee-oriented demonstrative (Pattern 1b; see (32)).


We suggest that this cross-linguistic difference might be analyzed as follows. We assume that Speaker-oriented demonstratives are always classified as proximal, hence they can be used for grounding novel referents. In contrast, Addressee-oriented demonstratives differ as to whether they are classified as proximal or distal. This difference in classification might reduce to the difference between so-called ‘distance-oriented’ and ‘person-oriented’ three-way systems (Diessel 1999, 50; Fortis and Fagard 2010). Specifically, according to Fortis and Fagard (2010), three-way demonstrative systems differ depending on whether the deictic centre includes both participants; i.e., the Speaker and the Addressee (person-oriented systems) or whether the deictic centre is restricted to the Speaker (distance-oriented systems). Accordingly, in person-oriented systems, the Addressee-oriented demonstrative patterns with Speaker-oriented ones and is thus classified like a proximal. In contrast, in distance-oriented systems, the Addressee-oriented demonstrative patterns with other-oriented demonstratives and is thus classified as distal. This is summarised in Table 6. We submit that only in person-oriented systems can the Addressee-oriented demonstrative be used for grounding novel referents. Whether this hypothesis is on the right track will have to be established based on a larger sample of data.
Finally, as in the two-way systems, we also find languages where the proximal demonstrative cannot be used for grounding novel referents but instead an existential strategy is used (Pattern 2). This is the case in Korean, Japanese, and Tagalog, which we illustrate in (33).

Note that in languages that make use of Patterns 1a and 1b, novel referents can also be introduced by means of an existential strategy. This is illustrated in (34) and (35) with an example from the southern Italo-Romance language Cepranese and Croatian. The three patterns of cross-linguistic variation are summarised in Table 7.


4.4 Languages with dedicated grounding demonstratives
Finally, there are also languages that do not reuse any of the spatial demonstratives as grounding demonstratives. Instead, these languages have dedicated grounding demonstratives, but again, we observe distinct patterns. First, consider Teiwa (Papuan), which has a two-way spatial demonstrative system (Klamer 2010).Footnote15 However, none of the spatial demonstratives are reused as grounding demonstratives. Rather both novel and familiar referents are introduced by dedicated demonstratives (Klamer 2010, 131–132), as shown in Table 8.
Next, consider Ktunaxa, a language isolate spoken in southern-interior British Columbia, Alberta, Washington, Idaho, and Montana. This language has a three-way demonstrative system (Canestrelli 1894; Morgan 1991). In our fieldwork, we found that none of the spatial demonstratives are reused as grounding demonstratives. Rather, for discourse familiar referents there is a dedicated discourse deictic demonstrative (36) and for novel discourse referents an existential strategy is used.

This is summarised in Table 9.
Note that in Ktunaxa the demonstrative used for familiar discourse referents is otherwise used for non-visible referents. This is not surprising given that this is a defining property of grounding demonstratives, they do not locate referents in physical space but rather within a mental space. As such, they do not refer to individuals visible in the present context.
Next, consider Darma (Tibeto-Burman), which has a three-way spatial demonstrative system (Willis 2007, 208). In this language, the Speaker proximal demonstrative can be reused for grounding novel referents. However, for grounding familiar referents a dedicated grounding demonstrative is used (Willis 2007, 208). This is summarised in Table 10.
4.5 Interim summary
We have now seen that the SGC in Table 1 (repeated below for convenience) holds across a number of geographically and typologically unrelated languages. That is, if spatial demonstratives are used for grounding, it is always the distal demonstrative that is used for familiar referents and the proximal demonstrative for novel referents.
We have also seen that there are differences across these languages, pertaining to two variables: one regarding the number of spatial demonstratives available and the other regarding the reuse of spatial demonstratives as grounding demonstratives. Regarding the number of spatial demonstratives, we have seen that in both two- and three-way systems the SGC holds. In three-way systems, where proximal demonstratives come in two flavours (Speaker- and Addressee-oriented), most languages reuse the Speaker-oriented demonstratives as grounding demonstratives for novel discourse referents. However, we have also found one language where the Addressee-oriented one serves this purpose (i.e., Croatian).
Regarding the reuse of spatial demonstratives as grounding demonstratives, we have observed a variety of different patterns as summarised in Table 11. In the majority of languages in our sample, both proximal and distal demonstratives are recycled to function as grounding demonstratives. Conversely, in a small set of the languages in our sample, spatial demonstratives are never reused for the purpose of grounding. These languages have dedicated grounding demonstratives. In addition, there is a set of languages where only distal demonstratives are recycled to serve as familiar grounding demonstratives. In these languages, proximal demonstratives cannot be reused to introduce novel discourse referents. Instead, these languages make use of other means such as an existential strategy. One of the languages in our sample (i.e., Darma) reuses only the Speaker proximal demonstrative to introduce novel discourse referents while using a different strategy to refer to familiar referents.
5 A syntactic analysis of the Spatial-Grounding Correlation
In this section, we propose a syntactic analysis to account for the SGC as well as the cross-linguistic variation we have observed. We start by introducing some existing syntactic analyses of spatial demonstratives (Sect. 5.1), which will serve as the basis for analysing their grounding use. Then, we introduce the structure we hypothesise is responsible for the grounding interpretation, namely the ‘Nominal Interactional Structure’ in the sense of Ritter and Wiltschko (2018, 2019; Sect. 5.2). We then show how the reuse of spatial demonstratives can be modelled syntactically (Sect. 5.3). Specifically, we propose that spatial demonstratives are interpreted DP-internally, whereas grounding demonstratives are interpreted in the Nominal Interactional Structure. Finally, we add some preliminary discussion regarding the range and limit of variation observed (Sect. 5.4).
5.1 The structure of spatial demonstratives
The majority of treatments of demonstratives in the generative tradition concerns the syntax of spatial demonstratives (see Brugè 1996; Vangsnes 1999; Brugè 2000, 2002; Giusti 2002; Shlonsky 2004; Alexiadou et al. 2007; Guardiano 2010; Roehrs 2010; Dékány 2011; Roberts 2017; i.a.). There is consensus that spatial demonstratives are located within the DP (see Alexiadou et al. 2007, 109 for a review). However, there is disagreement with respect to whether demonstratives are heads (Bernstein 1997) or specifiers, and whether demonstratives are base-generated in SpecDP or whether they are moved into that position; and if they are moved the question is where their base position is (see Brugè 1996; Vangsnes 1999; Brugè 2000, 2002; Giusti 2002; Shlonsky 2004; Alexiadou et al. 2007; Guardiano 2010; Roehrs 2010; Dékány 2011; Roberts 2017; i.a.).
As for the spatial interpretation of demonstratives, it has been argued that it is due to a locative particle, which may or may not be spelled out as a separate morpheme. For example, Leu (2015) argues for the existence of deictic locative elements here and there, which can either be overt or covert. (We represent silent elements with small caps; Kayne 2005.) For example, in English, the demonstrative this is considered to be the spell-out of the determiner the plus the locative particle here (i.e., the+here = this) and the demonstrative that is the spell-out of the determiner the plus the locative particle there (i.e., the+there = that). Alternatively, the two components can be spelled out as distinct morphemes, a determiner and a locative particle. For example, in Colloquial Norwegian den/det realises the determiner whereas herre instantiates the proximal locative particle and derre instantiates the distal locative particle (37).

Leu (2015) argues that the locative particle here/there is an intrinsic part of demonstratives and has to be distinguished from optional locative particles. Evidence that the two are distinct is the fact that they can co-occur both in English (38) and in Eastern Norwegian (39):Footnote16
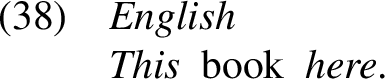
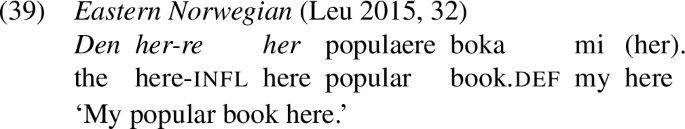
In sum, there is evidence that the spatial component of the demonstrative is introduced by a dedicated deictic element. We here adopt the syntactic structure proposed in Leu (2015, 44), where the demonstrative is a phrase (DemP) consisting of a demonstrative head (the determiner element) and the locative particle. DemP is base-generated nP internally and moves to SpecDP. This is illustrated in (40a) for proximal demonstratives marked by here and in (40b) for distal demonstratives marked by there.
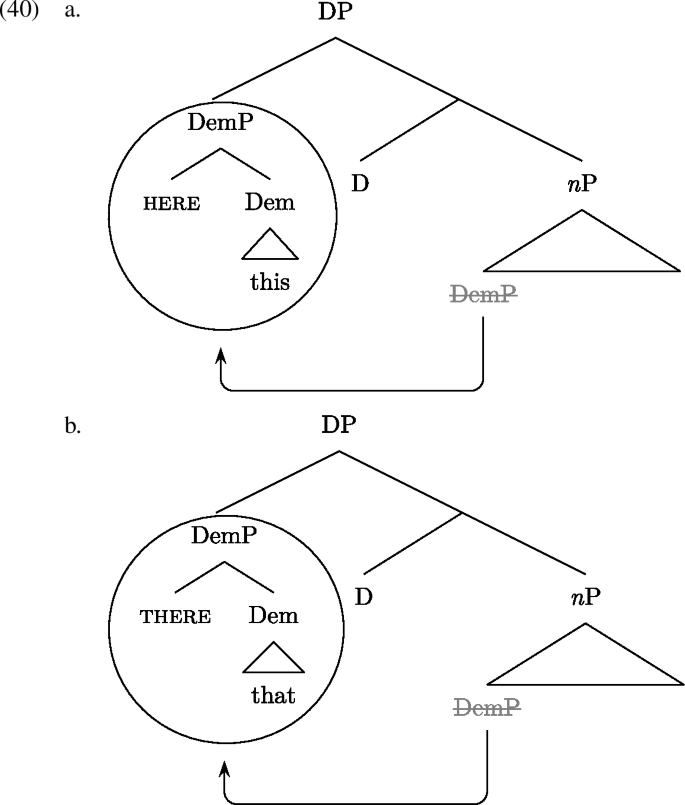
Next we discuss the non-spatial uses of demonstratives, which have received much less attention in the syntactic literature. The literature that does discuss non-spatial uses typically argues that the different demonstrative interpretations motivate the existence of distinct syntactic positions for demonstratives (see Bernstein 1997; Manolessou and Panagiotidis 1999; Manolessou 2000; Panagiotidis 2000; Grohmann and Panagiotidis 2005). For example, it has been claimed that deictic and anaphoric uses of demonstratives constitute evidence for the existence of two DP positions (following a ‘Split DP hypothesis’, akin to Rizzi’s (1997) ‘Split CP hypothesis’; see Manolessou and Panagiotidis 1999; Manolessou 2000; Panagiotidis 2000; Aboh 2004b; Haegeman 2004; Grohmann and Panagiotidis 2005; Laenzlinger 2005). According to this Split DP hypothesis, the lower DP (labelled as DP2 in (41)) hosts anaphoric demonstratives while the higher DP (labelled as DP1 in (41)) hosts deictic ones.
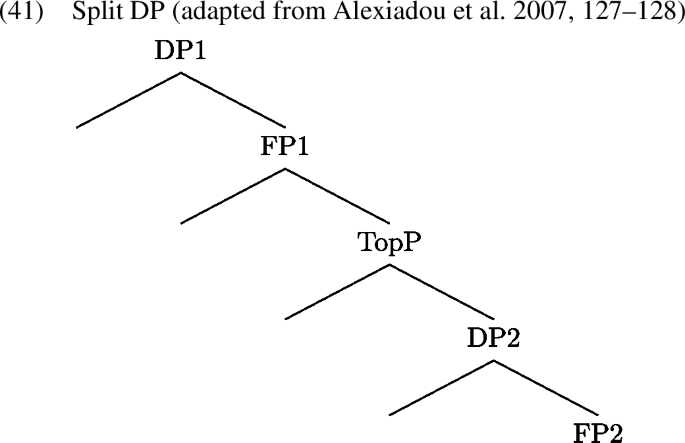
Evidence for the syntactic difference between anaphoric and deictic demonstratives comes from differences in word order. For example, in Modern Greek demonstratives are interpreted deictically in prenominal position (42a) and anaphorically in postnominal position ((42b); Panagiotidis 2000; Grohmann and Panagiotidis 2005). Note that anaphoric postnominal demonstratives are also unstressed.Footnote17

While the difference between anaphoric and deictic uses is captured in this analysis, the difference between spatial and grounding deixis is not.
Recall that grounding demonstratives differ from anaphoric ones in two respects. First, grounding demonstratives must be realised with an overt NP; while anaphoric NPs are only optionally realised with an overt NP with a preference for an elided NP. Second, anaphoric demonstratives require an overt antecedent in the ongoing discourse, whereas grounding demonstratives are used to refer to a discourse referent that is part of the common ground but is not part of the ongoing discourse. If we take the spirit of the Split DP analysis seriously, namely that a difference in interpretation corresponds to a difference in syntactic position, it stands to reason that spatial and grounding demonstratives, too, differ syntactically. In what follows, we develop such an analysis. Specifically, we argue that spatial demonstratives are realised DP-internally (as in (40) above), whereas grounding demonstratives are realised in the Nominal Interactional Structure, which we introduce in the next subsection.
5.2 The Nominal Interactional Structure
Ritter and Wiltschko (2018, 2019, 2024) propose that nominals, like clauses, consist of three layers of structure: a lexical structure (i.e., NP), a functional structure (i.e., DP and PhiP), and an interactional structure, in the sense of Wiltschko (2021).Footnote18 The existence of a Nominal Interactional Structure is motivated on theoretical grounds as follows. First, it is well-established that there exists a structural parallelism between the clausal and the nominal spine (Chomsky 1970; Abney 1987; Szabolcsi 1994). Second, there is growing consensus that the propositional clausal architecture is dominated by a layer of structure dedicated to regulating language use (Speas and Tenny 2003; Haegeman and Hill 2013; Wiltschko and Heim 2016; Wiltschko 2021; Munaro 2018; Miyagawa 2022; i.a.). There is, however, no consensus regarding the labels of the functional projections assumed to comprise this particular layer of structure, with the most commonly used label being ‘Speech Act Phrase’ and/or an articulated version of it (Speas and Tenny 2003; Hill 2007; Giorgi 2010; Krifka 2013; Haegeman 2014; Kido 2015; Corr 2016; Woods 2016); i.a.). However, Wiltschko (2021) highlights that the notion of a speech act is not a primitive and so it is not expected to correspond to a dedicated functional projection in the spine. Moreover, most of the literature on the syntacticisation of speech acts is based on classic speech act theory developed in the 1960s (Austin 1962; Searle 1969), failing to include its subsequent developments. For instance, speech act theory developed into a theory of dialogue-based interaction (see Sacks et al. 1974; Grice 1975; Weigand 2016; i.a.). Considering insights from this body of work, Wiltschko (2021) develops a model of syntacticisation of interaction, which we adopt in this paper. Structurally speaking, Wiltschko (2021) assumes the presence of an interactional structure which dominates the propositional clausal structure. In particular, the functional projections that comprise this interactional structure are two Grounding projections, which serve to negotiate the shared knowledge between interlocutors. Specifically, Wiltschko proposes one Speaker-oriented GroundP (GroundSpkrP) and one Addressee-oriented GroundP (GroundAdrP).Footnote19 The separation of Common Ground into Addressee- and Speaker-oriented Ground echoes the original taxonomy proposed in Prince (1981b) into Speaker old/new vs. Hearer old/new of discourse referents.Footnote20 Assuming a parallelism between nominal and sentential structure, we assume the nominal structure schematised below (see Ritter and Wiltschko 2019, 2024):
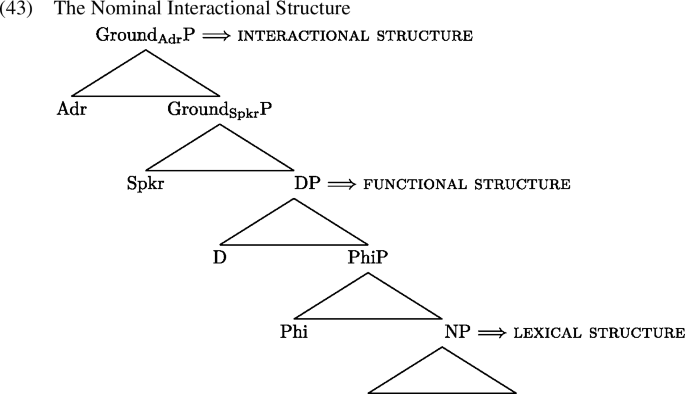
We now turn to the analysis of grounding demonstratives using the Nominal Interactional Structure.
5.3 A syntactic analysis of the Spatial-Grounding Correlation
We propose that the SGC is a consequence of the possibility for spatial demonstratives to be ‘recycled’ into the Grounding layers of the interactional structure, where they are interpreted as grounding demonstratives.Footnote21 Specifically, we propose that the proximal demonstrative is recycled into SpecGroundSpkrP, whereas the distal demonstrative is recycled into SpecGroundAdrP, as illustrated in (44).
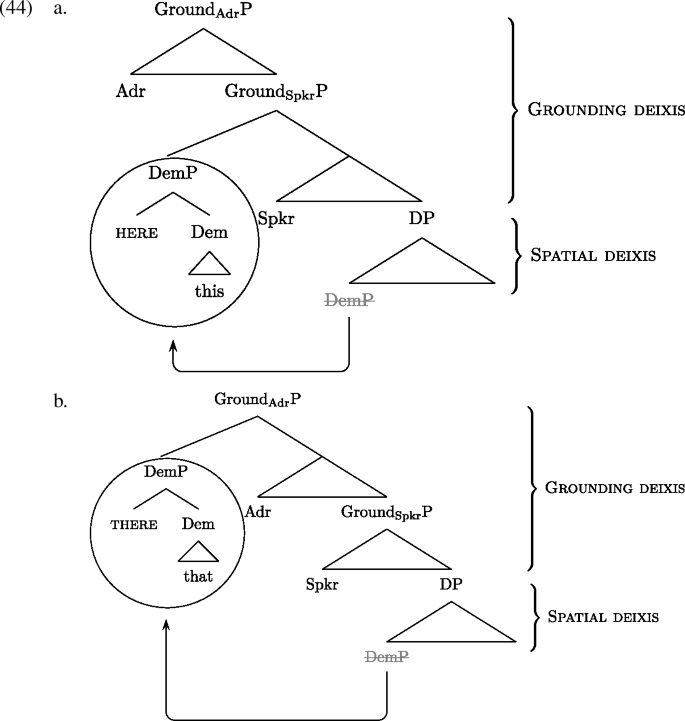
In what follows, we motivate this analysis by addressing the following three questions:
- 1.What is recycling?
- 2.How do the demonstratives in GroundSpkrP and GroundAdrP acquire the novel vs. familiar interpretation?
- 3.What determines which spatial demonstrative is recycled in which position?
First, consider the mechanism of recycling. We consider recycling to be a process whereby a given form that originates in one position is re-associated to a higher position where it receives a different interpretation, namely one that is determined by the interpretive function of this higher structure (Mezhevich 2008; Colasanti and Wiltschko 2019; Ritter and Wiltschko 2019, 2020, 2024).Footnote22 Thus, we assume that recycling is a movement operation, which is driven by interpretation akin to other well-attested strategies such as topicalisation to the left periphery (Rizzi 1997).Footnote23
Next, we turn to the question of how spatial demonstratives are interpreted as referring to novel vs. familiar discourse referents as a result of being interpreted in the grounding structure. We propose that when the proximal demonstrative is interpreted in GroundSpkrP, its referent is interpreted as being part of the Speaker’s Ground. We further assume that the novelty that comes with this interpretation is a matter of Gricean inferencing (Grice 1975). Specifically, adopting Heim’s (1982) notion of Maximise Presupposition we suggest that when the Speaker marks a referent as being in the Speaker’s Ground it is interpreted as being only in the Speaker’s Ground. As a consequence, the referent is interpreted as being novel to the Addressee. Conversely, when the distal demonstrative is interpreted in GroundAdrP, the referent is interpreted as being part of the Addressee’s Ground. Thus, the referent must be discourse familiar. Note that it is not necessary to also mark the referent as part of the Speaker’s Ground. This is because for a Speaker to mark a referent as being in the Addressee’s Ground the Speaker must be familiar with it. Consequently, the referent must be familiar to both the Speaker and the Addressee.
Finally, we turn to the third question, namely as to what determines which spatial demonstrative is recycled into which grounding position. Recall from Sect. 4.3 that in three-way systems Speaker-oriented demonstratives pattern with proximals. Additionally, in some languages (e.g., Croatian) Addressee-oriented demonstratives, too seem to pattern with proximals. Thus, in three way systems either Speaker- or Addressee-oriented demonstratives may be recycled into GroundSpkrP where they are interpreted as novel. In contrast, distal demonstratives are always recycled in GroundAdrP where they are interpreted as familiar. The question is why this should be the case and why it could not be the other way round. Without an answer to this question, the rationale that underlies the SGC still remains a mystery.
We argue that the spatial deictic components (here and there) of the demonstratives are responsible for determining the landing site of the recycling operation. Specifically, there is an intuitive sense in which deictic here correlates with a Speaker-oriented interpretation while there correlates with an Addressee-oriented interpretation. We thus argue that here is only interpretable in GroundSpkrP while there is only interpretable in GroundAdrP. To formalise this intuition, we adopt Terenghi’s (2019) analysis of demonstratives, according to which the spatial deictic features of spatial demonstratives are in fact participant features (see also Kayne 2014; Harbour 2016). That is, according to Terenghi (2019), in two-way demonstrative systems, the proximal feature corresponds to [+Author] and distal corresponds to [-Author] (where [±Author] are notional equivalents of Speaker and Addressee). On this analysis, the abstract locative particle is in fact person-oriented and thus allows us to understand the observed restriction on recycling. The abstract particle labelled here is intrinsically tied to the Speaker as it refers to the deictic centre which corresponds to the Speaker. Thus, we argue it is only interpretable in GroundSpkrP. In contrast, there is intrinsically distinct from the Speaker as it is disjoint from the deictic centre and it is intrinsically Other-oriented. This is consistent with its interpretation in GroundAdrP.Footnote24
Tentative evidence for this view on the person-based quality of the apparent spatial modifier comes from the following considerations. Within our dataset, we have observed that locative particles do not participate in recycling. That is, neither in Swabian German nor in French is the locative particle used in grounding demonstratives. This observation also holds for locative particles in English. That is, while spatial demonstratives can be accompanied with an overt locative particle (here and there), as in (45), grounding demonstratives cannot (46).


We hypothesise that the impossibility for an overt locative particle is due to the intrinsic locative character of these particles and that this prevents them from being interpreted in the Grounding layers. If this hypothesis is on the right track, it suggests that the abstract (silent) deictic element within demonstratives is not intrinsically locative (see also Leu 2015, 33, 39). If the silent modifiers of this (i.e., here) and that (i.e., there) were indeed qualitatively identical to their overt counterpart, then the impossibility for overt locative particles in grounding demonstratives would remain unaccounted for. Thus, our data supports the claim that the silent deictic elements here/there of demonstratives are not intrinsically locative, unlike their overt locative counterparts here/there. We submit that the silent particles that make the demonstratives deictic are intrinsically person-oriented.Footnote25 Note further that the hypothesis that overt locative particles are intrinsically locative rather than person-based is further confirmed by the fact that they are restricted to two-way demonstrative systems. If overt locative particles were person-based (i.e., denoting [±Speaker]), then we would expect them to be found in three-way demonstrative systems, as well, contrary to fact.
In sum, the SGC derives from the way spatial deictic features can be reinterpreted in the Nominal Interactional Structure: the proximal (Speaker) feature of a demonstrative can only be interpreted in the Speaker-oriented grounding layer where it marks novel discourse referents; conversely, the distal (Addressee) feature can only be interpreted in the Addressee-oriented grounding layer where it marks familiar discourse referents.
5.4 Preliminary remarks on the range and limits of variation
We conclude this section with a few remarks regarding the predictive power of the recycling analysis with respect to the range and limits of variation observed in this paper. Importantly, the recycling analysis accounts for all of the observed patterns. Significantly, the SGC is never violated. That is, we have seen that some languages do not recycle all of their spatial demonstratives as grounding demonstratives, some languages do not recycle any of their spatial demonstratives, while yet another set of languages recycle distal demonstratives. What the recycling analysis cannot predict is which language will fall into which category. However, we do not consider this to be a problem of our analysis. A similar indeterminacy can be found in the domain of information structure, where theories propose strategies for marking it but they cannot predict which strategy a specific language will use (see, for instance, cartographic approaches to information structure; e.g., Rizzi 1997; Rizzi and Bocci 2017; Belletti 2004). It remains an open question whether there are other factors in a given language which correlate with the type of recycling strategy used. For example, one might reasonably expect that the grounding use of demonstratives interacts with the system of definiteness available in the language. However, this goes beyond the scope of our study and will require a more in-depth typological study.
6 Conclusions and consequences
The empirical goal of this paper was to introduce a novel generalisation concerning the multifunctionality of demonstratives that we call the ‘Spatial-Grounding Correlation’. Specifically, if a language reuses its proximal demonstrative for grounding it will be used for novel referents and if a language reuses its distal demonstrative it will be used for familiar referents. We have demonstrated that the reuse of spatial demonstratives as grounding demonstratives follows the same basic pattern across 22 languages from different language families. However, there is some variation concerning whether a language does reuse its demonstratives and if so, which ones. We have not found any language where the pattern of reuse is the reverse. We have therefore concluded that the SGC is not a language-specific coincidence and thus deserves a principled explanation.
To this end, we have proposed an analysis according to which the SGC is syntactically conditioned. Specifically, we have adopted the wide-spread analysis of spatial demonstratives as being generated within the DP and being associated with an abstract deictic element that is responsible for its spatial interpretation (e.g., Leu 2015). We have argued that this abstract element is person-based (see Terenghi 2019): proximal demonstratives come with a Speaker-oriented specification while distal demonstratives come with an Addressee-oriented specification. We have further argued that grounding demonstratives are derived by movement into the Nominal Interactional Structure (in the sense of Ritter and Wiltschko 2018, 2019). Unlike what happens in other movement strategies, the demonstrative is reinterpreted in the derived position. We referred to this process as recycling. Specifically, we argued that the Speaker-oriented feature of proximal demonstratives can only be interpreted in GroundSpkrP, which derives the fact that a proximal demonstrative can introduce a novel discourse referent. In contrast, the Addressee-oriented feature of distal demonstratives can only be interpreted in GroundAdrP, which derives the fact that they refer to familiar discourse referents. Thus, the proposed analysis captures the SGC, which at first sight appeared rather counter-intuitive. That is, one might expect that a proximal demonstrative would refer to a discourse referent which is already in the common ground (and thus proximal to the interlocutors) while a distal demonstrative might be expected to locate discourse referents that are outside of the common ground. This pattern would be expected if the grounding use of demonstratives were a matter of metaphorical extension (e.g., Yang 2011). That is, if the SGC were derived by simply extending the physical space onto the conceptual space (i.e., the common ground) we would expect that proximal demonstratives are metaphorically extended to refer to referents close to our conceptual space and distal ones to refer to referents distant from it. But the empirical evidence we have introduced here shows that the contrary is true. We take this as strong evidence that the SGC is conditioned by grammar rather than being based on metaphoric extension. The crucial aspect of our analysis is that it does not consider the reinterpretation from the perspective of common ground, which is construed as a perspective that the interlocutors share. Rather the key to understanding the SGC is to consider the common ground as derived from two separate grounds: one belonging to the Speaker and one to the Addressee. That is, the proximal (thus Speaker-oriented) demonstrative links the referent to the Speaker’s Ground and (via Gricean maxims) only to the Speaker’s Ground. Hence, the referent is interpreted as being novel from the point of view of the Addressee. In contrast, the distal (thus Addressee-oriented) demonstrative links the referent to the Addressee’s Ground. Hence, the referent is interpreted as being familiar from the point of view of the Addressee, which is a prerequisite to being part of the shared common ground.
A crucial prerequisite for our understanding of the SGC is thus the separation of common ground into a Speaker- and an Addressee-oriented Ground. And this is precisely what the interactional spine allows us to do. Thus, in as much as the analysis is on the right track, it provides new evidence for the Nominal Interactional Structure. Analysing the systematic multifunctionality of demonstratives as syntactically mediated in the way we proposed supports the assumption that the spatial interpretation of demonstratives is the basic one. This is generally known as localism, which Lyons (1977, 718) defines as “the hypothesis that spatial expressions are more basic, grammatically and semantically, than various kinds of non-spatial expressions […]”. According to this view, spatial expressions are linguistically more basic and can provide a structural template for other expressions, which is at the core of our analysis.
There are several consequences that derive from this analysis which we shall briefly outline in the remainder of this conclusion. First, if our analysis is on the right track, we are led to conceptualise two distinct notions of deixis with two distinct syntactic positions: spatial deixis in DP and grounding deixis in GroundP. In turn, this may lead us to expect that other deictic notions can come in two guises. For person, this has been argued to be the case in Ritter and Wiltschko (2019, 2024) to account for differences between personal pronouns of the Indo-European-type and Japanese-type pronouns. For social deixis, this appears to be true in that languages differ as to whether honorificity is realised as a DP-internal feature or a grounding feature. The former is instantiated by Maithili, where honorific marking has all the hallmarks of a phi-feature (Kumari 2023). The latter is instantiated by honorific markers that are realised in utterance final position such as Korean and Japanese politeness markers (Zanuttini and Portner 2003). If indeed there is a crucial interpretive difference that correlates with syntactic position, we predict there to be a difference between definite determiners and distal demonstratives used as familiar grounding demonstratives. While both are used to refer to familiar referents they are by hypothesis associated with different syntactic positions, which are expected to correlate with a difference in interpretation and hence in a difference in context of use. This is indeed the case. For example, definite determiners can be used to refer to individuals which are familiar by virtue of being unique in the world (like the sun or the moon). In contrast, neither proximal nor distal demonstratives can be used to refer to such individuals. This is shown in (47).

We might thus conclude that the familiar interpretation comes about in two distinct ways. We have argued that in the interactional structure, the familiarity of the discourse referent arises because it is associated with the Addressee’s Ground. As for definiteness, it has been argued that their semantic core cannot be defined based on familiarity, but instead that it involves the notion of domain restriction (Gillon 2006). The present findings indirectly support this conclusion.
Next we turn to another question that our analysis raises, namely what determines whether to use a demonstrative in its spatial or in its grounding use. While in the physical absence of the referent it will have to be the grounding demonstrative, the situation is less clear in the case where the referent is physically present. In this case, both options are possible. To see this, consider the examples in (48). In this context, the discourse referent is spatially close (the Speaker holds the bottle in their hand). Thus, when the Speaker refers to the bottle in their hand, the spatial proximal demonstrative must be used, as in (48a). However, in the same context, the Speaker may also talk about that same bottle as an instance of a familiar discourse referent, in which case the distal grounding demonstrative must be used, as in (48b).

Thus, when eliciting demonstratives in context or when analysing corpus data, one has to carefully distinguish between the spatial use and the grounding use in contexts when both are possible in principle.
Finally, we briefly return to the other instances of multifunctionality that have been observed for demonstratives (see Sect. 2). While we have not explored the full range of functions in our cross-linguistic study we note that our analysis also captures generalisations regarding some anaphoric uses. Specifically, as mentioned in Sect. 2.2, distal demonstratives are used to refer to discourse referents that have been previously introduced in a conversation, hence these are considered discourse familiar. While for nominal discourse referents the preferred strategy to refer back to a previously introduced discourse referent is via pronouns or definite determiners, there are still contexts in which the SGC can be observed, namely with propositional referents. This can be seen in the example below:
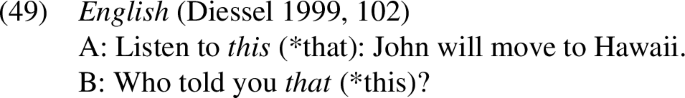
In (49), that refers back to a previously introduced proposition (i.e., a familiar referent), whereas this introduces a new referent by cataphorically relating to the following proposition.Footnote26
In conclusion, we hope that this article inspires more research into the multifunctionality of demonstratives. In particular, it remains to be seen whether the SGC holds across a larger sample of languages and if there are other patterns of variation that we have not yet uncovered. From a theoretical perspective, we hope to have shown that incorporating interactional structure into the realm of syntactic analysis allows us to straightforwardly capture patterns that lie at the syntax-pragmatics interface. The cross-linguistic systematicity of the SGC strongly supports the view that grammar is responsible for its existence.
Notes
-
In this article we adhere to The Leipzig Glossing Rules. The language data for this article have been collected with speaker linguists and naïve consultants through interviews conducted by the Authors. See Sect. 3.
-
See Sect. 6 for an alternative view.
-
It is an empirical question whether the Addressee-oriented demonstrative patterns with the Speaker or Other. See also Sect. 4.3 for different types of three-way systems.
-
We thank an anonymous reviewer for pointing out that the fact that three-way systems are always intrinsic could be plausibly related to morphology. For instance, in the Englishes which have three-way systems, only two of the three exponents are morphologically th-words (this/that vs. yon). This is also true for German dies-/d- vs. jen-.
-
For completeness, we note that when the referent is globally unique, demonstratives cannot be used even if it is already in the common ground. In this case, the referent can be referred to with either their name (e.g., John) or with a definite article (e.g., the sun).
-
In this specific example, the demonstrative forms are necessarily anaphoric to the object DP. To anaphorically refer to the subject, a personal pronoun is used (Diessel 1999, 96).
-
In (18a) that refers to the proposition that they promoted Fred to second vice president, whereas in (18b) that refers to the fact that A said that Fred was promoted to second vice president.
-
An anonymous reviewer points out that the SGC might in fact be intuitively expected in the following way: since every discourse unfolds over time, the moment a referent is introduced is now and near (i.e., this), but immediately after, as the discourse continues, the referent’s appearance gets more and more removed in discourse-time (i.e., that).
-
We describe here the observed patterns in terms of reuse. This implies that the spatial use is in some sense more basic and the grounding use is derived, which foreshadows the syntactic analysis we develop in Sect. 5. Thus, at least in the domain of demonstratives, we subscribe to a localist view, according to which spatial expressions in general are more basic (see Sect. 6).
-
We are thankful to Christina Lee for drawing all our conversation boards.
-
For more details see the Totem Fields Storyboards (https://www.totemfieldstoryboards.org/) and Burton and Matthewson (2015).
-
We acknowledge that for a typological study, this is a relative small sample size with a very strong representation of the Indo-European language family. We still submit that our findings are empirically significant and support the SGC. We hope that this study, which is unique in its kind, will inspire other researchers to explore the correlation between spatial and grounding demonstratives in other languages.
-
We also used conversation boards with inanimate referents. However, since we did not find any differences based on animacy, we restrict our discussion to animate referents.
-
Other possibilities to introduce the novel referent include ‘this one hippie’ and ‘a hippie’. Our consultants indicated that they preferred the use of this or this one in this context while the use of the regular indefinite determiner (a) was less preferred in this context. Although interesting, we do not consider these possible choices in this paper. For more empirical details and for discussion see Prince (1981a), Fodor and Sag (1982), Maclaran (1982), Lambrecht (1994), Chafe (1994), Ionin (2006) and references therein.
-
We were unable to conduct fieldwork on Teiwa and Darma.
-
As reported by Leu (2007, 32), the overt demonstrative herre shows adjective-like agreement in Eastern Norwegian.
-
Personal communication P. Panagiotidis. In this example afto in (42b) is anaphoric and hence the proximal demonstrative can be used to refer back to a previously uttered referent. See discussion in Sect. 2.2.
-
The intuition that there is additional structure on top of the DP (and CP) is also found in Aboh (2004a), Laenzlinger (2005), Leu (2015). However, the structures proposed in these previous works do not include Speaker- and Addressee-related notions, which are crucial for the analysis proposed in this paper.
-
The interactional structure also contains a Resp(onse)P which is responsible for the regulation of turn-taking. Nominal RespP plays no role in the typology of nominals developed here; see however Ritter and Wiltschko (2020) for evidence of nominal RespP based on vocativisers such as hey.
-
See also Clark and Brennan (1991) and Gunlogson (2001).
-
The analysis that grounding demonstratives are recycled into the Grounding layers is consistent with the observation that in some languages demonstratives are reanalysed as discourse markers (Næss et al. 2020).
-
For a similar idea of ‘recycling’ in grammar see Rooryck (2019), Biberauer (2019). Other authors use a similar idea without calling it ‘recycling’ (as well as Massam 2009).
-
Based on the data we have considered thus far, this appears to be a covert movement. It remains to be seen whether any overt syntactic or morphosyntactic evidence can be found in support of this movement.
-
This raises an interesting question as to whether there is a featural difference between person-oriented and distance-oriented demonstrative systems (see Sect. 4.3). We have to leave this as a question for future research.
-
An anonymous reviewer points out that a piece of positive evidence in favour of the idea that (in some languages) deictic/spatial demonstratives may be person-oriented comes from languages in which personal pronouns and spatial deictic expressions (such as demonstratives) share their morphological forms, as is particularly clear in Turkish, for instance (specifically noted in Leu (2015, §2.7.2) and in Harbour (2016, §7.2.2), who also mentions other languages).
-
Our analysis is also compatible with the recent analysis developed in Staps and Rooryck (2022), who argue that the complementiser that, like the spatial demonstrative, contains a distal feature, which in turn is responsible for reference to a shared discourse space.
References
-
Abney, S. 1987. The English Noun Phrase in its Sentential Aspect, Ph.D. thesis, MIT.
-
Aboh, E. 2004a. The morphosyntax of complement-head sequences. Clause structure and word order patterns in Kwa. Oxford: Oxford University Press.
-
Aboh, E. 2004b. Topic and focus within D. Linguistics in the Netherlands 21:1–12.
-
Alexiadou, A., L. Haegeman, and M. Stavrou. 2007. Noun phrase in the generative perspective. Berlin: de Gruyter.
-
Auer, P. 1981. Zur indexikalitätsmarkierenden Funktion der demonstrativen Artikelform in deutschen Konversationen. In Sprache: Verstehen und Handeln, eds. G. Hindelang and W. Zillig, 301–311. Tübingen: Niemeyer.
-
Auer, P. 1984. Referential problems in conversation. Journal of Pragmatics 6:627–648.
-
Austin, J. L. 1962. How to do things with words, Vol. 88. Oxford: Oxford University Press.
-
Belletti, A. 2004. Aspects of the low IP area. In The structure of CP and IP, ed. L. Rizzi, 16–51. Oxford: Oxford University Press.
-
Bernstein, J. 1997. Demonstratives and reinforcers in Romance and Germanic languages. Lingua 102:87–113.
-
Biberauer, T. 2019. Factors 2 and 3: Towards a principled approach. Catalan Journal of Linguistics 1–44.
-
Brugè, L. 1996. Demonstrative movement in Spanish: A comparative approach. Working Papers in Linguistics 6(1):1–53.
-
Brugè, L. 2000. Categorie funzionali del nome nelle lingue romanze. Milano: Cisalpino.
-
Brugè, L. 2002. The positions of demonstratives in the extended nominal projection. In Functional structure in DP and IP: The cartography of syntactic structures, ed. G. Cinque, 15–53. Oxford: Oxford University Press.
-
Burton, S., and L. Matthewson. 2015. Targeted construction storyboards in semantic fieldwork. In Methodologies in semantic fieldwork, eds. M. R. Bochnak and L. Matthewson. 135–156. Oxford: Oxford University Press.
-
Canestrelli, P. 1894. Grammar of the Kutenai Language. Santa Clara: Typis N. H. Downing.
-
Chafe, W. 1994. Discourse, consciousness, and time: The flow and displacement of conscious experience in speaking and writing. Chicago: University of Chicago Press.
-
Chen, R. 1990. English demonstratives: A case study of semantic expansion. Language Sciences 12:139–153.
-
Chomsky, N. 1970. Remarks on nominalizations. In Readings in transformational grammar, eds. R. Jacobs and P. Rosenbaum. Needham Heights: Ginn
-
Clark, H., and S. Brennan. 1991. Grounding in communication. In Perspectives on socially shared cognition, eds. Lauren B. Resnick, J. M. Levine, and S. D. Teasley, 127–149. Washington: APA Books.
-
Colasanti, V., and M. Wiltschko. 2019. Spatial and discourse deixis and the speech act structure of nominals. In Proceedings of the Canadian Linguistic Association Annual Meeting (CLA), 1–3 June 2019, Vancouver BC.
-
Corr, A. 2016. Ibero-Romance and the Syntax of the Utterance, Ph.D. thesis, University of Cambridge.
-
Dékány, É. K. 2011. A profile of the Hungarian DP: The interaction of lexicalization, agreement and linearization with the functional sequence, Ph.D. thesis, Universitetet I Tromsø.
-
Diessel, H. 1999. Demonstratives: Form, function and grammaticalization. Amsterdam: Benjamins.
-
Fillmore, C. J. 1997. Lectures on deixis. Stanford: CSLI.
-
Fodor, J., and I. Sag. 1982. Referential and quantificational indefinites. Linguistics and Philosophy 5(3):355–398.
-
Fortis, J. M., and B. Fagard. 2010. Space in language. Presented at the Leipzig Summer School on Linguistic Typology, University of Leipzig.
-
Gillon, C. 2006. the semantics of determiners: Domain restriction in Skwxwú 7mesh, Ph.D. thesis, University of British Columbia.
-
Giorgi, A. 2010. About the speaker: Towards a syntax of indexicality. Oxford: Oxford University Press.
-
Giusti, G. 2002. The functional structure of noun phrases: A bare phrase structure approach. In Functional structure in DP and IP: The cartography of syntactic structures, ed. G. Cinque, 54–90. Oxford: Oxford University Press.
-
Grice, H. P. 1975. Logic and conversation. In Speech acts, eds. P. Cole and J. L. Morgan. Vol. 3 of Syntax and semantics, 41–58. San Diego: Academic Press.
-
Grohmann, K., and P. Panagiotidis. 2005. An anti-locality approach to Greek demonstratives. In Contributions to the 30th Incontro di Grammatica Generativa, eds. L. Brugè, G. Giusti, N. Munaro, W. Schweikert, and G. Turano, 243–263. Venezia: Editrice Cafoscarina.
-
Guardiano, C. 2010. Demonstratives and the structure of the DP: Crosslinguistic remarks. In Workshop on disharmony in nominals, Linguistics Association of Great Britain annual meeting. Leeds University.
-
Gundel, J. K., N. Hedberg, and R. Zacharski. 1993. Cognitive status and the form of referring expressions in discourse. Language 69:274–307.
-
Gunlogson, C. 2001. True to Form: Rising and Falling Declaratives as Questions in English, Ph.D. thesis, UC Santa Cruz.
-
Haegeman, L. 2004. DP-periphery and clausal periphery: Possessor doubling in West Flemish. In Peripheries: Syntactic edges and their effects, eds. D. Adger, C. de Cat, and G. Tsoulas. Norwell: Kluwer Academic.
-
Haegeman, L. 2014. West-Flemish verb-based discourse markers and the articulation of the speech act layer. Studia Linguistica 68(1):116–139.
-
Haegeman, L., and V. Hill. 2013. The syntacticization of discourse. In Syntax and its limits, eds. R. Folli, C. Sevdali, and R. Truswell, 370–390. Oxford: Oxford University Press.
-
Halliday, M. A. K., and R. Hasan. 1976. Cohesion in English. London: Routledge.
-
Harbour, D. 2016. Impossible Persons. Cambridge: MIT Press.
-
Heim, I. 1982. The semantics of definite and indefinite noun phrases, Ph.D. thesis, University of Massachusetts, Amherst.
-
Hemmilä, R. 1989. The demonstrative pronouns pa and ti in Urim discourse. Language and Linguistics in Melanesia 20:41–63.
-
Hill, V. 2007. Vocatives and the pragmatics-syntax interface. Lingua 117(12):2077–2105.
-
Himmelmann, N. 1996. Demonstratives in narrative discourse: A taxonomy of universal uses. In Studies in Anaphora, ed. B. Fox, 205–254. Amsterdam: Benjamins.
-
Himmelmann, N. 1997. Nominalphrase. Zur Emergenz syntaktischer Struktur. Tübingen: Niemeyer.
-
Hinterwimmer, S., and P. Bosch. 2016. Demonstrative pronouns and perspective. In The impact of pronominal form on interpretation, eds. P. Grosz and P. Patel-Grosz, 189–220. Berlin: de Gruyter.
-
Ionin, T. 2006. This is definitely specific: Specificity and definiteness in article systems. Natural Language Semantics 14(2):175–234.
-
Kayne, R. 2005. Movement and silence. Oxford: Oxford University Press.
-
Kayne, R. S. 2014. Why isn’t this a complementizer? In Functional structure from top to toe: A festschrift for Tarald Taraldsen. Oxford: Oxford University Press.
-
Kido, Y. 2015. On the Syntactic Structure of Bai and Tai in Hichiku Dialect, Ph.D. thesis, Department of Linguistics, Faculty of Humanities, Kyushu University.
-
Klamer, M. 2010. A grammar of Teiwa. Berlin: de Gruyter.
-
Krifka, M. 2013. Response particles as propositional anaphors. In Proceedings of SALT XXIII, ed. T. Snider. Vol. 23, 1–18.
-
Kumari, P. 2023. Portmanteau Honorificity Agreement in Maithili. Manuscript, University of Konstanz.
-
Laenzlinger, C. 2005. French adjective ordering: Perspectives on DP-internal movement. Lingua 115:645–689.
-
Lambrecht, K. 1994. Information structure and sentence form: Topic, focus, and the mental representations of discourse referents. Cambridge: Cambridge University Press.
-
Leu, T. 2007. These HERE demonstratives. UPenn Working Papers in Linguistics 13:141–153.
-
Leu, T. 2015. The architecture of determiners. Oxford: Oxford University Press.
-
Levinson, S. C. 1983. Pragmatics. Cambridge: Cambridge University Press.
-
Lyons, J. 1977. Semantics. Cambridge: Cambridge University Press.
-
Maclaran, R. 1982. The Semantics and Pragmatics of the English Demonstratives, Ph.D. thesis, Cornell University.
-
Manolessou, I. 2000. Greek Noun Phrase structure: A study in syntactic evolution, Ph.D. thesis, University of Cambridge.
-
Manolessou, I., and P. Panagiotidis. 1999. Ta dhiktika tis ellikis ke i shetikes epiplokes. [Greek demonstratives and relevant complications]. In Studies in Greek linguistics: Proceedings of the 19th annual meeting of the Department of Linguistics, 199–212. Aristotle University of Thessaloniki.
-
Massam, D. 2009. Noun incorporation: Essentials and extensions. Language and Linguistics Compass 3(4):1076–1096.
-
Mezhevich, I. 2008. A feature-theoretic account of tense and aspect in Russian. Natural Language and Linguistic Theory 26(2):359–401.
-
Miyagawa, S. 2022. Syntax in the treetops. Cambridge: MIT Press.
-
Morgan, L. 1991. A Description of the Kutenai Language, Ph.D. thesis, University of California Berkeley.
-
Munaro, A. 2018. On the syntactic encoding of lexical interjections in Italo-Romance. In Italian dialectology at the interface, eds. S. Cruschina, A. Ledgeway, and E. M. Remberger, 185–202. Amsterdam: Benjamins.
-
Næss, Å., A. Margetts, and Y. Treis. 2020. Introduction: Demonstratives in discourse. In Demonstratives in discourse, eds. Å. Næss, A. Margetts, and Y. Treis, 1–20. Language Science Press.
-
Panagiotidis, P. 2000. Demonstrative determiners and operators: The case of Greek. Lingua 110:717–742.
-
Prince, E. 1981a. On the inferencing of indefinite-this NPs. In Elements of discourse understanding, eds. A. K. Joshi, B. L. Webber, and I. A. Sag, 231–250. Cambridge: Cambridge University Press.
-
Prince, E. F. 1981b. Toward a taxonomy of given/new information. In Radical pragmatics, ed. P. Cole, 223–254. New York: Academic Press.
-
Ritter, E., and M. Wiltschko. 2018. Distinguishing speech act roles from grammatical person features. In Proceeding of Canadian Association of Linguistics Meeting 2018, ed. E. Dmyterko.
-
Ritter, E., and M. Wiltschko. 2019. Nominal speech act structure: Evidence from the structural deficiency of impersonal pronouns. Canadian Journal of Linguistics 64(4):709–729.
-
Ritter, E., and M. Wiltschko. 2020. Interacting with vocatives! In Proceedings of the Canadian Linguistic Association Annual Meeting 2020, eds. A. Hernández and M. E. Butterworth.
-
Ritter, E., and M. Wiltschko. 2024. Pronouns beyond phi-features: The speaker–addressee relation in Japanese pronouns and its implications for formal pronouns. Journal of Linguistics 1–36. https://doi.org/10.1017/S0022226724000306.
-
Rizzi, L. 1997. The fine structure of the left periphery. In Elements of grammar, ed. L. Haegeman, 281–337. Berlin: Springer.
-
Rizzi, L., and G. Bocci. 2017. The left periphery of the clause: Primarily illustrated for Italian, 2nd edn. In The Wiley Blackwell companion to syntax, 1–30. Oxford: Blackwell.
-
Roberts, I. 2017. The final-over-final condition in DP: Universal 20 and the nature of demonstratives. In The final-over-final condition: A syntactic universal, 151–186. Cambridge: MIT Press.
-
Roehrs, D. 2010. Demonstrative-reinforcer constructions. Journal of Comparative Germanic Linguistics 13(3):225–268.
-
Rooryck, J. 2019. ‘Recycling’ evidentiality: A research program. In Mapping linguistic data. Essays in honour of Liliane Haegeman, eds. B. Metin, B. Anne, and D. C. Karen, 242–261.
-
Sacks, H., E. A. Schegloff, and G. Jefferson. 1974. A simplest systematics for the organization of turn-taking for conversatio. Language 50:696–735.
-
Searle, J. R. 1969. Speech acts: An essay in the philosophy of language. Cambridge: Cambridge University Press.
-
Shlonsky, U. 2004. The form of Semitic noun phrases. Lingua 114(12):1465–1526.
-
Speas, P., and C. Tenny. 2003. Configurational properties of point of view roles. In Asymmetry in grammar, ed. A. M. D. Sciullo, 315–345. Amsterdam: Benjamins.
-
Stalnaker, R. 2002. Common ground. Linguistics and Philosophy 25(5/6):701–721.
-
Staps, C., and J. Rooryck. 2022. On the demonstrative nature of finite complementizers. Linguistics 61(5):1195–1231.
-
Szabolcsi, A. 1994. The noun phrase. In The syntactic structure of Hungarian, eds. F. Kiefer and K. É. Kiss. Vol. 27 of Syntax and semantics, 179–274. San Diego: Academic Press.
-
Terenghi, S. 2019. Demonstrative-reinforcer constructions and the syntactic role of deictic features. In Linguistics in the Netherlands, Vol. 36, 192–207. Amsterdam: Benjamins.
-
Vangsnes, Ø. A. 1999. The Identification of Functional Architecture, Ph.D. thesis, University of Bergen.
-
Webber, B. L. 1991. Structure and ostension in the interpretation of discourse deixis. Language and Cognitive Processes 6(2):107–135.
-
Weigand, E. 2016. The dialogic principle revisited: Speech acts and mental states. In Interdisciplinary studies in pragmatics, culture and society, eds. A. Capone and J. Mey, 209–232. Berlin: Springer.
-
Willis, C. M. 2007. A descriptive grammar of Darma: An endangered Tibeto-Burman language, Ph.D. thesis, the University of Texas at Austin.
-
Wiltschko, M. 2021. The grammar of interactional language. Cambridge: Cambridge University Press.
-
Wiltschko, M., and J. Heim. 2016. The syntax of sentence peripheral discourse markers: A neo-performative analysis. In Outside the clause: Form and function of extra-clausal constituents, eds. G. Kaltenböck, E. Keizer, and A. Lohmann, 305–340. Amsterdam: Benjamins.
-
Woods, R. 2016. Investigating the syntax of speech acts: Embedding illocutionary force, Ph.D. thesis, University of York.
-
Yang, Y. 2011. A cognitive interpretation of discourse deixis. Theory and Practice in Language Studies 1(2):128–135.
-
Zanuttini, R., and P. Portner. 2003. Exclamative clauses: At the syntax-semantics interface. Language 79:39–81.
Acknowledgements
We are grateful to all our language consultants. We would also like to thank three anonymous reviewers and the journal editors for their invaluable comments and feedback. The usual disclaimers apply.
Funding
Open Access funding provided by the IReL Consortium. This work was supported by a Social Sciences and Humanities Research Council of Canada (SHHRC) Insight grant titled: How to do things with nominals: A linguistic investigation of referring speech acts (435-2018-1011), awarded to the second author (Martina Wiltschko). Open access has been funded by the IReL consortium through Trinity College Dublin’s membership.
Ethics declarations
Ethics approval and consent to participate
All data were collected during the academic year of 2019/2020. This data collection was approved by the ethics committee of the University of British Columbia (UBC) 2019/2020 BREB Number: H18-01816.
Competing Interests
No competing interests to declare.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and permissions
About this article
Cite this article
Colasanti, V., Wiltschko, M. Demonstratives locate referents in common space and ground: A comparative syntactic approach. Nat Lang Linguist Theory (2025). https://doi.org/10.1007/s11049-025-09675-3
- Received
- Revised
- Accepted
- Published
- DOI https://doi.org/10.1007/s11049-025-09675-3
Keywords
- Common ground
- Language variation
- Demonstratives
- Nominal Interactional Structure