Article Content
Abstract
In this paper, we provide an in-depth case study of properties of the verbal domain in the Indo-Iranian language Sinhala across different modules of grammar. Specifically, we investigate two seemingly independent grammatical phenomena (i) the phonological (under)application of umlaut and its relation to morphological structure and (ii) the syntactically conditioned choice of negation. As we argue, these phenomena strongly suggest respective analyses in terms of locality domains. Crucially, we find that locality domains in the syntax and the ones in phonology are essentially isomorphic. The set of constructions that we analyse as bi-domainal in the syntax corresponds exactly to the set of constructions that we analyze as bi-domainal in the phonology. This cannot be treated as accidental and we devise a model that derives these parallels in a systematic way. The model rests on the assumptions that (i) the syntax creates locality domains and inherits them to the morphology and the phonology and (ii) specific processes in these modules can manipulate the locality domains in a limited way. This allows us to maintain a restricted model of the syntax-morpho-phonology mapping that proves flexible enough to incorporate systematic exceptions. Such an approach paves the way to a more nuanced understanding of mismatches between different modules.
Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.
- Comparative Linguistics
- Indo-Iranian Languages
- Linguistic Anthropology
- Linguistics
- Phonology and Phonetics
- Theoretical Linguistics / Grammar
1 Introduction
The theoretical concept of locality domains is frequently employed in the research and the theoretical modeling of all core areas of grammar. Throughout all modules, the concept has proven effective for modeling the underapplication of grammatical rules. Whenever a grammatical rule does not affect a given element, even though we might potentially expect it to, one possible analysis is that the rule applies to a different locality domain than the element in question belongs to. In other words, if we see that a rule does not apply to a given target, then the trigger of the rule and the target might be too far away from each other.
In the syntax, where locality domains are currently referred to as phases, they are, for example, used to limit the application of syntactic movement, case assignment, or agreement phenomena of various types. In the morphology and the phonology, where locality domains are more often referred to as levels, strata, or word-internal phases, they have similarly been used to model the underapplication of processes, such as suppletion or allomorphy, as well as stress assignment, vowel harmony, etc. Most current theories of morphology and phonology assume that all grammatical processes in these areas are restricted by a given locality domain.
However, despite the undeniable success of the theoretical concept itself, it is still very poorly understood how these different instantiations of locality domains relate to each other across modules. As the use of the same terms in the different grammatical modules shows, there is the underlying intuition that these locality domains should ideally map onto each other, and that a locality domain in the phonology should not be completely independent from a locality domain in the morphology or the syntax. One strand of research in this area follows the so-called direct mapping hypothesis in assuming that locality domains in the morphology and the phonology are (largely) isomorphic to the ones found in the syntax.Footnote1 One of the most cited works in this line of research is Newell (2008), where she, for example, has shown that the domains required for phonological processes in Turkish, Cupeño, and Ojibwa are exactly those that we would expect in phase-based Chomskyan model of syntax. D’Alessandro and Scheer (2015) show that the phonological differences between actives, passives, and unaccusatives in Abruzzese similarly can be accounted for by appealing to the differences in their status as syntactic phases. However, as D’Alessandro and Scheer (2015) also note, it is methodologically somewhat problematic to assume the presence or absence of a phasal domain in the syntax for phonological reasons; they suggest that “the presence or absence of (…) a given phase needs to be worked out independently for each module and must be based on evidence from that module alone.” (D’Alessandro and Scheer 2015, 603) In other words, in order to arrive at a concrete testable theory of how locality domains in individual modules map onto each other, we need comprehensive studies that provide independent evidence for each module about the presence or absence of locality domains in a given area. Only then can we compare to what extent domains across modules can match or mismatch.
In this paper, we set out to contribute exactly such a study, which would be, to our knowledge, the first of its kind to investigate the issue of locality domains in a large part of a verbal domain of a given language in three modules independently of each other. We will present a case study from the Indo-Aryan language Sinhala that takes a close look at the complex verbal paradigm of the language and compares the need for locality domains in the syntax, the morphology, and the phonology. The phonological locality domains will be diagnosed by an in-depth investigation of the (under)application of the process of umlaut in the verbal domain. Those will be contrasted with the role domains play for the application of root suppletion in the morphology. The syntactic locality domains will be diagnosed by looking at the realization of negation, which differs depending on whether it is located in the highest domain or in an embedded domain. All of these phenomena could straightforwardly be derived by reference to module-specific locality domains (such as phases in the syntax and level 1/level 2-affixes in the morphology). However, as we will show, there is a strong correlation between the domains in the syntax and in the phonology. The syntax will treat some constructions as consisting of two locality domains, and the phonology will treat exactly those verb forms characterizing these constructions as consisting of two locality domains as well. This correlation cannot, we argue, be treated as a coincidence. It strongly suggests that we entertain a model of grammar that allows us to map locality domains onto each other.
In the spirit of the direct mapping approaches mentioned above, we develop such a model in which standard syntactic locality domains (i.e., phases) are transferred to a postsyntactic module, which in turn will then be mapped onto morphological and phonological locality domains. We connect this crossmodular mapping literature to the growing body of work on the dynamicity of phases (or phase extension, domain suspension, phase unlocking, phase sliding), i.e., the assumption that the size of phases can be changed by syntactic processes (see Rackowski and Richards 2005; den Dikken 2007; Gallego and Uriagereka 2007; Bobaljik and Wurmbrand 2013; Bošković 2014; van Urk and Richards 2015; Halpert 2016; Wurmbrand 2017; Fenger 2020). The paper is thus the first one to provide evidence that the effects of phases on phrasal processes, like phrasal movement, should or could potentially find correlates in the (under)application of word-internal morphophonological processes.
The paper is structured as follows: In Sect. 2, we will offer a detailed study of the morphophonological process of umlaut in the verbal domain in this language. We will identify two asymmetries between two classes of umlaut-triggering morphemes, and we will go on to show that these asymmetries strongly suggest an analysis in terms of locality domains. We will further offer a comparison with the purely morphological process of stem-suppletion to further refine the analysis of umlaut in Sinhala. In Sect. 3, we will then move on to look at the syntax of the language, and in particular at the properties and the realization of negation. We will show that negation allows us to diagnose syntactic locality domains, and we will see that they match up (with some systematic exceptions) with the locality domains of the phonology. Section 4 will introduce an analysis that derives both the syntactic properties of negation as well as the morphophonological properties of umlaut by means of the same locality domains. Section 5 then takes a step back and discusses some of the broader implications of the previous discussion. Section 5.1 discusses briefly how our approach relates to existing ones and where we claim to go beyond what has been done in the literature. Section 5.2 discusses a syntactic alternative to the concept of morphological domain extension we propose in Sect. 4.2.
Before we proceed with this, we want to introduce the language under investigation in this paper. Sinhala is an Indo-Aryan language spoken on the island of Sri Lanka by roughly 16 million speakers (Chandralal 2010). The language is characterized by a strong diglossia situation between the written and the spoken version of the language. Literary Sinhala differs in many respects from the colloquial language, including an even more elaborate inventory of verbal affixes. While Literary Sinhala shows a fair amount of different subject agreement markers, for example, the colloquial language shows no subject agreement at all anymore. Nonetheless, we will see that the inventory of verbal affixes as well as the number of grammatical categories expressed on the verb in Colloquial Sinhala is still fairly large. In what follows, we want to note that we will only be concerned with Colloquial Sinhala, even though we will refer to the language as Sinhala from now on.
Sinhala differs from its Indo-Aryan relatives (apart from the other insular Indo-Aryan language Dhivehi (Fritz 2002)) both in terms of its lexicon and also in terms of its grammatical properties. As both Geiger (1938) and Chandralal (2010) discuss, this is, on the one hand, arguably due to the fact that Sinhala is geographically surrounded by Dravidian languages, most notably by Tamil, which is the other main language spoken in Sri Lanka. The other main factor that certainly had an influence on the language are the different periods of colonization by the Dutch, the Portuguese, and the English since the 16th century.
Some of the areally and genealogically typical features that the language displays include the basic head-final word order and the nominative-accusative alignment, differential object marking, as well as the frequent use of non-finite complementation structures.
As for the morphology, we find that the language displays a fair amount of (seemingly) non-concatenative processes, including a lot of allomorphy and suppletion, subtractive morphology, exponence by gemination and reduplication, as well as umlaut, the topic that will be the subject of the next section. This has led researchers like Garland (2005) to classify the language as a non-concatenative or fusional language. As discussed in the next section, however, a detailed investigation of the verbal morphology will show that the language is, underlyingly, perfectly concatenative and that the aforementioned processes only obscure the morphological structure (but in a systematic way).
2 The domains in phonology: The limits of umlaut
In this section, we provide a detailed discussion of the phenomenon of umlaut in the verbal domain in Sinhala. Although we will offer some discussion about the properties of the umlaut process itself, the focus of the discussion throughout this section will be on the locality domains that the process is restricted by. We will proceed as follows: Sect. 2.1 introduces the basic pattern of umlaut in the language and introduces the umlaut-triggering morphemes that will play a role throughout this section. Section 2.2 will then go on to introduce two asymmetries between these triggering morphemes. In both cases, umlaut sometimes underapplies, i.e., it fails to appear, even though we might expect it to. Section 2.3 offers an interim summary and gives a first attempt of an empirical generalization. Section 2.4 provides a closer look at the verbal class marker, which plays a crucial role in simplifying the empirical generalization. Section 2.5 offers a comparison of the phonological process of umlaut with the morphological process of stem-suppletion. Section 2.6 then concludes the discussion of umlaut and gives the final empirical generalization about the limits of umlaut in Sinhala.
2.1 The basic umlaut pattern
Umlaut in Sinhala is characterized by a fronting of the vowel quality of the stem triggered by specific affixes. This process applies to all vowels on the stem and to all back vowels alike. Any /u/ is changed to /i/; any /a/ is changed to /æ/, and any /o/ is changed to /e/. The examples that follow illustrate this property in the nominal domain. The feminine affix /-i/ triggers fronting of all vowels.
- (1)

Two notes are in order about the phonology here (based on discussions in Abhayasinghe 1973 and Letterman 1997). First, we note that the feminine suffix /i/ attaches to the vowel-final stems of the language, which then leads to deletion of the stem-final vowel. This is typical process in Sinhala to avoid vowel hiatus. The second comment concerns the schwa (/ə/) in examples like (1b), which does not seem to undergo fronting, as it does not have a fronted counterpart.
Note that the umlaut process in Sinhala differs from processes like prototypical vowel harmony, as Sinhala allows for front/back mismatches in roots (e.g., gowi ‘farmer’) or root-affix combinations.Footnote2
- (2)

Umlaut is also very common in the verbal domain, which is the focus of this section. The patterns of umlaut described in this section and the next hold for all verbs of the language and have the same properties as for the nominal domain above: It affects all vowels on the stem, and it affects each back vowel. Front vowels and the schwa remain unaffected.
In (3), we see the verb stem bal- ‘look,’ which contains a back vowel, followed by a class marker, a causative, a non-past, and an indicative affix. None of these affixes is an umlaut-trigger, which is why the verb stem is realized with a back vowel. In (4), however, which only differs from (3) by replacing the causative with a passive affix, the stem is realized with a front vowel /æ/. The passive affix -e is an umlaut trigger.Footnote3
- (3)

- (4)
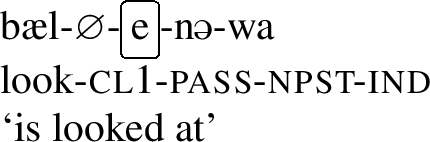
Similar minimal pairs can be constructed with the difference between the non-past and the past affix. The latter is an umlaut trigger, the former is not.
- (5)
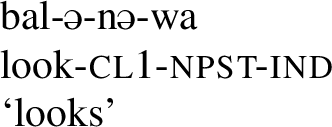
- (6)
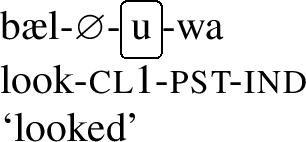
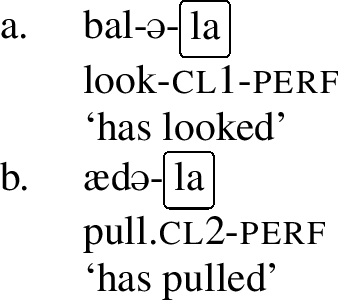
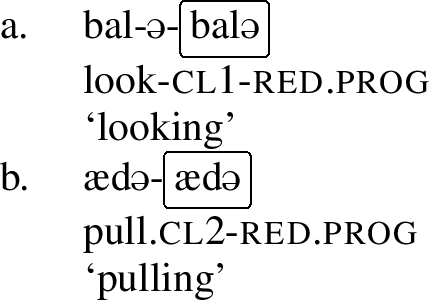
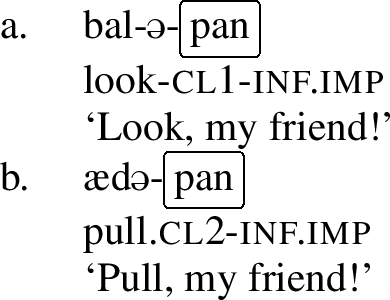
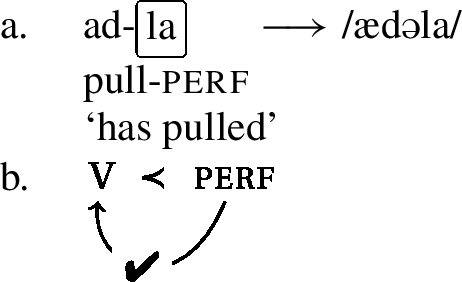
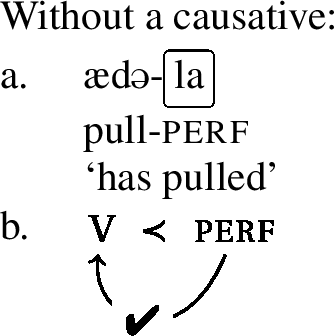
Other umlaut triggers include the perfect marker -la, the informal imperative marker -pan and the progressive aspect marker, which is realized by a full reduplication of the verb stem.Footnote4 Consider the examples below, which involve the verb stem ad- ‘to pull.’ In the regular imperative, which is not a trigger, the stem has a back vowel, but in the informal imperative in (8),Footnote5 in the perfect in (9) and in the progressive in (10), the stem has been umlauted, as each of these morphemes is an umlaut-trigger.Footnote6
- (7)

- (8)
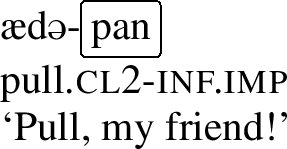
- (9)

- (10)
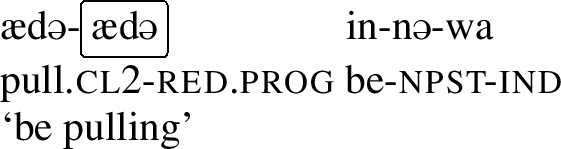
The following, (11) gives a selection of verbal affixes and classifies them into umlaut-triggers and non-umlaut-triggers.Footnote7
- (11)

What this table illustrates is that whether an affix is an umlaut-trigger cannot simply be reduced to its morphological or overt phonological properties. As for the morphology, we see that valency-related affixes, such as causative or passive, differ as to whether they are triggers, and the same holds for tense affixes, such as non-past or past, or the difference between the regular imperative and the informal imperative. As for the phonology, we can also see that it is, synchronically, no longer possible to attribute the property of being an umlaut-trigger to the segmental phonological properties of the affix itself.Footnote8 We see that some of the affixes that trigger umlaut are or contain back vowels themselves (such as one allomorph of the past tense marker, or the perfect). Similarly, we see that some affixes that are front vowels do not trigger umlaut, such as the verbal focus marker -e. Furthermore, some of the umlaut-triggers do not even contain segmental material (such as the other allomorph of the past tense, which is marked by gemination, or the progressive, which is marked by reduplication).
What we take from these observations is that the property of being an umlaut-trigger cannot be predicted from the morphological or the segmental phonological properties of an affix. This conclusion is in line with the general consensus in the literature on Sinhala: Geiger (1938), Parawahera (1990), Letterman (1997); all note that a synchronic treatment of umlaut in Sinhala has to stipulate which affixes trigger umlaut and which ones do not. In what follows, we assume that some affixes (namely the ones on the right in the table above) carry a floating feature that, in the phonology, will float onto the stem and cause umlaut (Lodge 1989; Yu 1992; Lieber 1992; Wiese 1996; Trommer 2021). It is this floating feature that characterizes an affix as being an umlaut trigger, but we want to reiterate that whether a given affix bears a floating feature or not cannot be deduced from any of its morphological or phonological properties. The concrete analysis of umlaut as the result of a floating feature will be made more precise in Sect. 4.3.
Though various sources have made the observation above, there was no attempt in the literature to fully describe or explain the asymmetries between the different umlaut-triggers we discuss in the following subsection:
2.2 Two asymmetries amongst the umlaut-triggers
In the preceding section, we have seen that the property of being an umlaut-trigger must, synchronically, be treated as an inherent property of certain morphemes or exponents. In this section, we will see that, amongst the morphemes that are umlaut-triggers, we seem to find two classes which we will, from now on, call strong umlaut-triggers and weak umlaut-triggers. Strong umlaut-triggers are the past tense marker, and the passive marker and weak umlaut-triggers are the informal imperative, the perfect marker, and the progressive marker. The difference between the weak and the strong umlaut-triggers manifests itself in terms of two asymmetries:
- ➀:
- Intervention: Strong umlaut-triggers, such as [pst] or [pass], will trigger umlaut on the stem across an intervening causative. Weak umlaut-triggers, such as [perf], [prog], and [inf.imp], will not.
- ➁:
- Verb Classes: Strong umlaut-triggers, such as [pst] or [pass], will trigger umlaut in verb classes 1 and 2, whereas weak umlaut-triggers, such as [perf], [prog], and [inf.imp], will only trigger umlaut in class 2 but not in class 1.
In the two subsections that follow, we illustrate and discuss these two asymmetries. After we have done so, we argue in Sect. 2.4 that these asymmetries can actually be unified in the following generalization (12), by taking a closer look at the notion of verb class and class markers. This generalization is the main observation that we set out to explain in the theoretical part of this paper.
- (12)

2.2.1 The intervention asymmetry: Umlaut at a distance
In this subsection, we illustrate the first asymmetry between the different umlaut-triggers. The first one we called intervention asymmetry, and it concerns a configuration where the umlaut-trigger is not linearly adjacent to the stem that is affected by umlaut. The asymmetry is repeated below:
- ➀:
- Intervention: Strong umlaut-triggers, such as [pst] or [pass], will trigger umlaut on the stem across an intervening causative. Weak umlaut-triggers, such as [perf], [prog], and [inf.imp] will not.
In order to illustrate this, we need to test a configuration where an affix linearly intervenes in between the verb stem and the umlaut-triggers. Of course, the intervener cannot be a trigger itself, otherwise we would not be able to test whether the outer morpheme had any effect on the stem. The ideal candidate for an intervener is the causative morpheme -wa (and its allomorph /wə/), which is not a trigger itself, and which is close enough to the stem that it can appear in between the stem and all the affixes we want to test.Footnote9
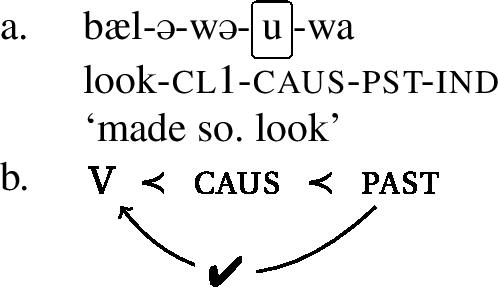
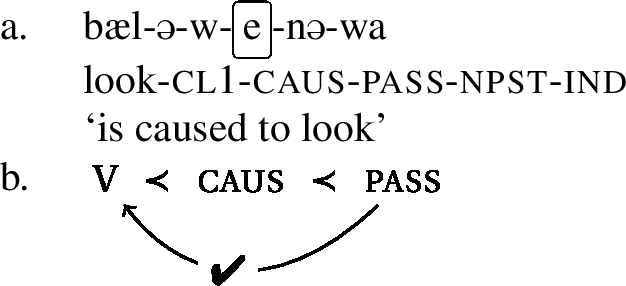
Consider first the configurations in (13) and (14). In both cases, we have constructed a configuration where an umlaut-trigger (past tense in (13a) and passive voice in (14)[a]) attaches to a verb that already bears a causativizing morpheme. And in both cases we see that verb stem does undergo umlaut, as it shows a front vowel. The abstract representations in (13b) and (14)[b] indicate that the umlaut-property that comes from the past or the passive morpheme can reach the stem vowel despite an intervening causative.
- (13)
- (14)
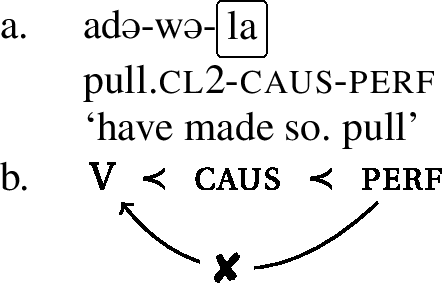
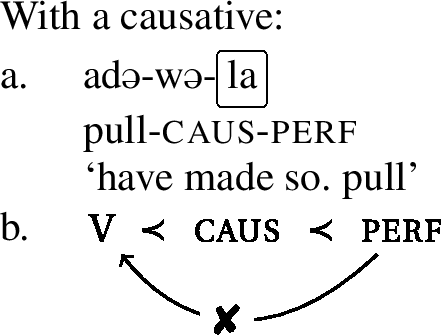
Now consider the examples in (15), (16), and (17). On the surface, we have the exact same configurations as above. The respective umlaut-triggers, the perfect, the informal imperative, and the progressive, are separated from the stem by an intervening causative. And even though we have seen that all three morphemes are umlaut-triggers in the basic forms (see examples (8), (9), and (10)), they do not trigger umlaut in the configurations at hand. The umlaut-property of these three morphemes cannot reach the stem across an intervening causative.Footnote10
- (15)
- (16)
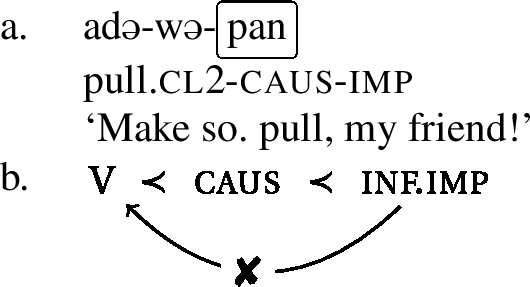
- (17)
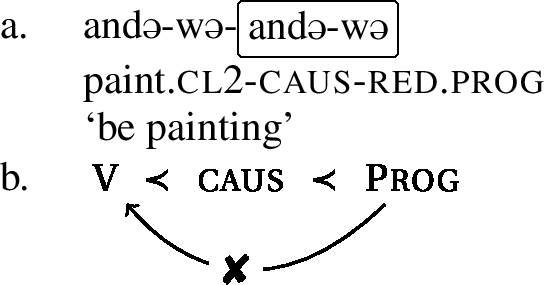
What we see is that there seems to be a dichotomy of umlaut-triggers. Some of them can trigger umlaut at a distance (namely, pst and pass), whereas others (namely, perf, inf.imp and prog) cannot. The latter need to be adjacent to the verb stem in order to trigger umlaut. As noted above, we refer to these two classes of triggers as weak and strong umlaut-triggers. The umlaut-property of weak triggers (perf, inf.imp, prog) cannot reach the stem across an intervener, whereas the umlaut-property of a strong trigger (pst and pass) can.
2.2.2 The verb class asymmetry: Partial vs complete umlauters
In this subsection, we look at another asymmetry that also instantiates the split between the two types of umlaut-triggers we have seen above. This time, it concerns the application of umlaut in the two verb classes in Sinhala.
- ➁:
- Verb classes: Strong umlaut-triggers, such as [pst] or [pass], will trigger umlaut in verb classes 1 and 2, whereas weak umlaut-triggers, such as [perf], [prog], and [inf.imp], will only trigger umlaut in class 2 but not in class 1.
According to standard descriptions (see, for example, Geiger 1938; de Silva 1960; Gair 1970; Chandralal 2010), Sinhala has three verb classes, which can be distinguished by the class markers. In what follows, we only focus on the first two verb classes.Footnote11 The verb classes in Sinhala are most easily distinguished in the infinitive. The marker in class 1 shows up as /a/ (18a). Standardly, the /i/ at the edge of the stem in class 2 is taken to be the class marker for class 2. Note that in many examples, however, the underlying differentiation between the classes is neutralized, because both vowels /a/ and /i/ are reduced to schwa in open syllables ((18b) and (19)[b]).
- (18)

- (19)

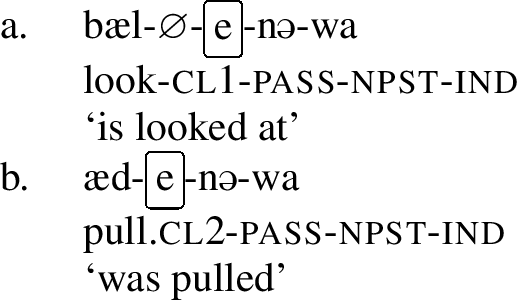
Apart from the different realizations of the class marker, these verb classes behave differently with respect to a number of other processes, including their property to undergo umlaut. Strong umlaut triggers (pst and pass) will trigger umlaut in both verb classes, whereas weak triggers (perf, inf imp, prog) will only trigger umlaut in class 2. Consider first the behavior of pst and pass in the examples below. Pst in (20) and pass in (21) will trigger umlaut on both verb classes. All the verb stems in (20) and (21) have undergone umlaut.
- (20)
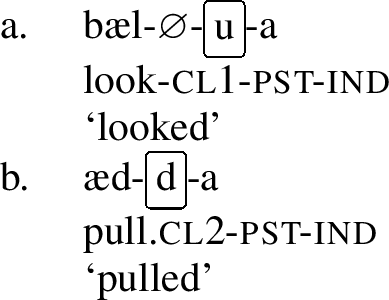
- (21)
Again, that can be contrasted with the behavior of weak umlaut-triggers: perf, inf.imp, and prog in the examples below. In these examples, we see that the class 1 verb bal- ‘look’ does not undergo umlaut, but the class 2 verb ad- ‘pull’ does.
- (22)
- (23)
- (24)
So, as with the asymmetry concerning intervention, we note that there is a difference in behavior between the umlaut-property of strong triggers and the umlaut property of weak triggers. Strong triggers will always trigger umlaut on a verb, regardless of its class membership, whereas weak triggers will only do so in class 2.
2.3 Interim summary
In the two preceding subsections, we have seen two asymmetries that seemingly point to two types of umlaut in Sinhala. Umlaut triggered by strong umlaut-triggers can apply despite an intervening causative and affects both verb classes, and umlaut triggered by weak umlaut-triggers is blocked by an intervening causative and only affects class 2.
An immediate question that this raises is whether we need to stipulate that there are two phonological umlaut processes in the language. We think that it is encouraging that both asymmetries above pick out the same sets of umlaut-triggers. In both cases, it seems to be a difference between pst and pass on the one hand and perf, inf.imp, and prog on the other hand. It is, fortunately, not the case that both asymmetries refer to different sets of triggers, as shown in Table 1.
We take this as sign that there is systematicity, and that, ultimately, the two asymmetries have the same underlying cause. And, as a detour into the phonological properties of the class markers in the next section will show, this is indeed the case. We have good evidence that the two asymmetries can be reduced to one that, on a more abstract level, regulates both properties at the same time.
2.4 A closer look at the verbal class marker
In this subsection, we will take a closer look at the properties of the verbal class marker to get an idea why, at least with some umlaut-triggers, umlaut is restricted to class 2 verbs. We have seen above that, in the infinitive, the two verb classes can be distinguished by the vowel preceding the infinitive affix. This gave rise to the standard classification as /a/ being a class marker for class 1, and /i/ being a class marker for class 2. Note, however, that the two verb classes can also be distinguished by looking at the exponents of the causative and the past tense morphemes:
- (25)

- (26)

For class 1, the causative is realized as /-wə-/, and the past tense is realized with /-u-/. For class 2, however, the causative and the past tense involve gemination rather than a purely segmental exponent. Based on Abhayasinghe (1973), Letterman (1997) argues that this actually suggests that class 2 does not have a class marker underlyingly at all. According to her, the /i/ in the infinitive above, as well as the /ə/ in class 2 in many of the other forms, are merely epenthetic material.Footnote12
To be concrete, Letterman (1997) argues that the past tense exponent is a more abstract element, an empty mora μ, which is realized as /u/ when it is adjacent to a vowel, and as gemination when it is adjacent to a consonant. In class 1 (27), the past marker will always be adjacent to a vowel since there is the class marker present. In class 2, however, according to Letterman (1997), there is no class marker, and hence the empty mora, that is, the tense exponent will be next to the stem-final consonant, leading to gemination (see (28)).Footnote13
- (27)
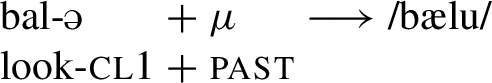
- (28)
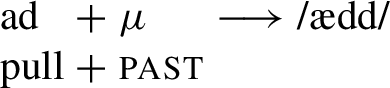
In Class 2 in the present tense, where the tense exponent is an /nə/, the resulting consonant cluster requires the subsequent application of an epenthesis rule that inserts an /i/ in the position where usually the class marker would appear.
- (29)
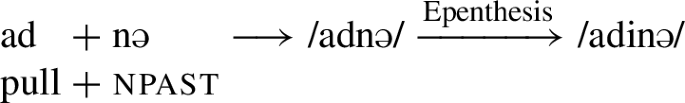
The same conclusion that class 2 does not have a class marker is drawn by Geiger (1938)Footnote14 on the basis of diachronic data. He shows that the vast majority of class 2 verbs are historically all part of the consonant-final verb class in Sanskrit. Further, he shows that older stages of Sinhala often do not show the apparent /i/-class marker with class 2 verbs:
- (30)
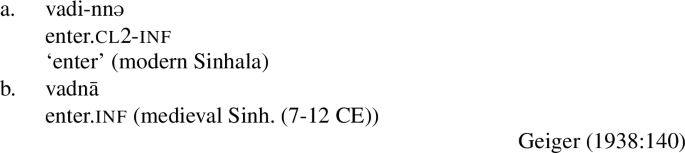
This assumption by Geiger (1938) and Letterman (1997) that class 2 (unlike class 1) actually has no class marker patterns extremely well with our observation that class 2 is more likely to undergo umlaut, as this allows us to reduce the both asymmetries to one, which can simply be phrased in terms of locality. The reason that class 1 does not undergo umlaut with the weak umlaut-triggers is that it has a class marker intervening. We already saw that intervention of the causative blocks umlaut triggered by the weak triggers, so it is not surprising that intervention by any other morpheme, such as the class marker, does the same thing. Class 2, on the other hand, does not have a class marker. The segment that looks like a class marker is merely epenthetic, and, at the point when umlaut applies, it is not present, and thus cannot intervene.
Consider the representations in (31) and (32), both of which feature a verb with a weak umlaut-trigger. In (31), we have a class 1 verb, which comes with its class marker. Thus, the umlaut-property that is introduced by the weak trigger (perf) cannot reach the stem, because there is a morpheme intervening. In (32), we see a class 2 verb, which does not have a class marker. Therefore, when the weak umlaut-trigger attaches to it, there is no intervening morpheme, and thus the umlaut-property of perf can reach the stem as indicated in (32)[b]. The schwa that is usually taken to be the reduced class marker is merely the result of subsequent epenthesis of /i/ plus additional vowel reduction.
- (31)
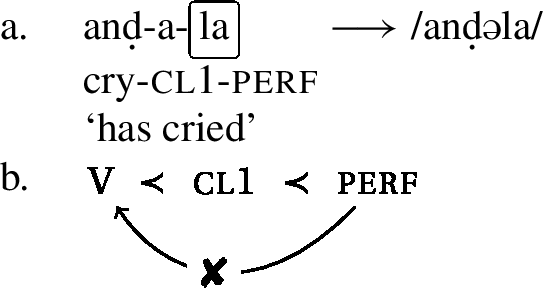
- (32)
In essence, this means that the asymmetry between the two verb classes can be reduced to whether the class has an overt class marker or not. Class 1 does have a class marker, and therefore is not affected by the umlaut-property of weak triggers. Class 2 does not have a class marker, and therefore will be affected by weak triggers. What this means is that we managed to reduce the two asymmetries we saw in Sects. 2.2.1 and 2.2.2 to one, given in (33):
- (33)

This empirical generalization is essentially what we want to understand and derive in the remainder of this paper. As noted above in Sect. 2.3, since there is no clear evidence for different umlaut processes, we maintain the idea that there is a single umlaut process in the language that plays out differently, depending on the morphosyntactic configuration it appears in. We will follow this path in what follows, but first, in Sect. 2.5, we want to compare umlaut to a purely morphological phenomenon, namely stem suppletion. This will help us understand the process of umlaut better and help us motivate the thought that umlaut is an actual phonological process in the language.
2.5 The comparison to morphology: Patterns of stem suppletion
In the preceding section, we arrived at one coherent empirical generalization that explained the two asymmetries. In this section, we compare the process of umlaut to stem suppletion, a process that, on the surface, seems to have very similar properties. In both cases, it seems that an affix has the power to manipulate the surface form of the stem.
And, in fact, recent work by Embick and Shwayder (2017) has suggested that some umlaut patterns in Icelandic and German often have the properties of morphological stem suppletion. They argue that different umlaut patterns in these languages can either be phonological or morphological rules. It thus makes sense to take a closer look at the process of umlaut and compare it to purely morphological processes, such as stem suppletion.
Fortunately, Sinhala has quite a number of verbs that show stem suppletion that is governed by specific tense and aspect configurations, in particular by past tense and perfect aspect. Since these two affixes are also amongst the umlaut-triggers, this allows for a nice minimal comparison between the two processes.
Consider the two verbs ya- ‘go’ and e- ‘come’ in Sinhala, which both supplete for both past tense and perfect.Footnote15 The verb ya- ‘go’ changes to gi- in the past tense and to gihin in the perfect, and the verb e- changes to aa- in the past and to æwit in the perfect:
- (34)

- (35)

Just as with umlaut, we can now test what happens if the trigger of the suppletion and the stem are separated by an intervening morpheme. The obvious candidate is the causative wə-, and as we see in (36) and (37) (below), the pattern is very clear. Each case of suppletion disappears.
- (36)

- (37)

The stem in the examples in (37) does not undergo stem suppletion; in fact, it does not change at all. It is realized as e- throughout. As the ungrammatical versions in brackets indicate, suppleted stems with a causative morpheme are not an option. This indicates that stem suppletion requires immediate adjacency and cannot be triggered across an intervening causative. Even more telling are the examples in (36), where we also see that suppleted versions are not possible. When cooccuring with a causative, the verb stem cannot be realized as gi- or gihin. However, as shown in (36b), in the absence of stem suppletion, umlaut reappears. The verb stem suddenly appears with a fronted vowel. What this means is that, in the identical configuration, one and the same affix fails to trigger suppletion, but manages to trigger umlaut. This is illustrated in (38):
- (38).
We only observe this asymmetry between suppletion and umlaut with the past tense in (37b), of course, and not with the perfect in (37c), because perfect is a weak trigger, and its umlaut-property will be blocked by an intervening causative anyway. Note also that we do not observe this reappearance of the umlaut in the absence of suppletion with the verb e-, as the stem of this verb is a front vowel to begin with.
What we take from this discussion is that the mismatch in examples like (36b), illustrated in (38), shows us that umlaut is, at least for the strong umlaut-triggers, fundamentally different from a purely morphological process, such as stem suppletion. Umlaut can apply despite intervening morphemes, such as the class marker in class 1 or the causative, whereas purely morphological processes cannot. We take this as an argument that umlaut is different from these morphological processes, and that it is a productive phonological process in the language.
Weak umlaut-triggers, on the other hand, require immediate adjacency between the trigger and the target and, in a sense, this seems to indicate that they behave like suppletion. If we were to maintain that analysis, we would thus be forced to assume that there are two types of umlaut in Sinhala: Umlaut triggered by strong triggers is purely phonological as it can apply despite intervening morphemes, and umlaut triggered by weak triggers is morphological as it is blocked by intervening morphemes.Footnote16 However, even though this might look appealing at first, we do not think that this is a tenable analysis. As we have seen, umlaut triggered by weak triggers has the exact same phonological effect as umlaut by strong triggers. Both types will change the vowel quality of the stems in exactly the same way. And they do so completely predictably: changing back vowels to front vowels of the same height. Also, we want to note that both processes are completely productive in the language and affect all verbs alike without exception. If we were to maintain an analysis according to which a morphological umlaut rule and a phonological umlaut rule have the same effect, it would require us to posit that for every single verb in the language, two alternating stems are stored, one with a front vowel one with a back vowel. The one with a fronted vowel is chosen specifically when it appears next to a weak trigger. The one with a back vowel can, however, undergo a phonological process that mysteriously happens to make the surface form look exactly like the independently stored fronted verb stem alternant. We take this to be a very undesirable result and an unnecessary burden for the lexicon, as well as implausible from a learner’s perspective. We therefore do not pursue this approach and continue to assume that there is one coherent phonological process of umlaut in Sinhala that plays out differently, depending on the configuration it appears in.
2.6 Taking stock: The domains in phonology
In the preceding subsections, we have arrived at a simple generalization that describes the limits of umlaut in Sinhala in a somewhat abstract but empirically accurate way.
- (39)

We argued that the different behavior of the umlaut-property with [pass] and [pst] on one hand, and [perf], [prog] and [inf.imp] on the other, should not be taken as evidence that Sinhala shows evidence for two fundamentally different umlaut-processes. Rather, we argued in depth that we can maintain a coherent notion of umlaut in the language, and that the differences in behavior between the different affixes are derived from independent factors. Further, we argued in the previous subsection that the contrast between umlaut on the one hand and stem suppletion on the other strongly indicates that umlaut is indeed a productive phonological process in the language.
The generalization in (39) requires an explanation, and one of the most straightforward options on the table is one in terms of phonological domains. As noted in the introduction already, whenever a phonological process that we might expect to apply fails to do so, one of the possible explanations is one in terms of phonological domains. The intuition becomes clear if we, for a start, simply look at the minimal pairs with a weak umlaut-trigger appearing with or without an intervening causative (recall that the schwa in class 2 verbs are epenthetic, and are therefore represented as part of the verb stem in the examples):
- (40)
- (41)
The intuition that we want to model is that underapplication of umlaut in (40) is due to its trigger being too far away from its target. In (40), the perfect morpheme is not local enough to trigger umlaut, but in (41) it is. This is straightforward, but in order to keep that assumption in line with the strong triggers, we need to assume that strong triggers (like [pst]) are always local enough to trigger umlaut, regardless of whether they are separated from the stem by a causative.
In order to couch this intuition in a theoretical model of morphology, we could follow decades of level-based or stratal accounts of morphology,Footnote17 and attribute the different behaviors to the difference between stem-level and word-level affixes. Strong triggers would then be stem-level affixes, and weak triggers would be so-called dual level-affixes that are flexible with respect to their domain. They can either be stem-level affixes or word-level affixes. If they are adjacent to the stem, then they are stem-level affixes, and if they are non-adjacent, they are word-level affixes.
Aronoff (1976), Selkirk (1982), Mohanan (1986), Giegerich (1999), Kiparsky (2005) discuss dual level affixes that seem to attach to the stem-level or the word-level depending on the configuration such as the well-known case of English -able-affixation. In (42a), -able attached to the stem-level as diagnosed by the fact that the in-allomorph of the negation prefix is chosen. In (42b), -able attaches to the word level, as diagnosed by the un-allomorph of the negation prefix.
- (42)

Whether -able attaches to the stem-level or to the word-level can be shown to have different phonological consequences (such as the change from /mitt-/ to /miss-/ in (42a)).
The underlying intuition in most of the above-mentioned systems (see Giegerich 1999; Kiparsky 2005) is that -able is, by default, a word-level suffix but can, in certain configurations, be integrated into the stem-level. In a similar fashion, we could say that weak triggers, such as the perfect, are dual level-affixes as in (43)–(45), where the inner box represents the stem-level, and the outer box represents the word-level. The perfect morpheme would thus be a word-level suffix but can be integrated into the stem-level if it is adjacent to the verbal root. If we then assume in addition that umlaut is restricted to the stem-level, the behavior of umlaut and in particular the underapplication of umlaut with weak triggers is accounted for.
- (43).

- (44).

- (45).

As argued in Giegerich (1999), Kiparsky (2005), it is the properties of the base that determine whether a dual-level affix will have the properties of a stem-level or a word-level affix. The same can be said for the case at hand. Some affixes (such as passive and past tense) are uniformly stem-level affixes, and they will always belong to the innermost domain. But for others, the properties of the base determine what level they belong to. A dual level affix that attaches to a simplex root will act as belonging to the innermost domain, but if that same affix attaches to a sufficiently complex base, it will act as a word-level affix. As we will see, this intuition will immediately translate into our approach later on.
Thus, we think that the domain-based approach to the underapplication of umlaut is essentially correct, but we want to go one step further and look into the morphosyntax of the respective constructions to figure out whether it is an accident that the morphemes pattern together in the way they do. Recent developments in the study on the interface between morphology and syntax have unearthed a number of interesting predictions about the way that syntactic locality domains and morphological and phonological ones can be mapped onto each other.Footnote18 The underlying research question that we want to answer is the following: Giegerich (1999), Kiparsky (2005) have the intuition that dual-level affixes are essentially affixes of the outer domain that are exceptionally integrated into the inner domain in a specific context. If that is true, and it is also true that the locality domains in syntax, morphology, and phonology map onto each other, then we might find evidence in the syntax that constructions involving weak triggers, such as perfect, progressive, or informal imperatives, involve two locality domains, whereas constructions involving strong triggers, such as passive or past tense, do not. As we will see in the next section, this is borne out in a surprisingly straightforward way. The differences between weak and strong umlaut-triggers have a clear correlate in the way these respective constructions are negated.
3 The domains in syntax: The choice of negation
Based on the underapplication of umlaut in some cases, we arrived at what one might call a very rough sketch of an analysis that makes use of the theoretical concept of locality domains. Some verbal affixes, namely the strong umlaut triggers passive and past, are always inside the innermost locality domain (i.e., the stem-level) with the verb stem, whereas others (i.e., the weak triggers perfect, progressive and the informal imperative) are not. They are usually in an outer domain, but they can be exceptionally integrated into the inner domain if they are adjacent to the verbal root. In this section, we will see that this classification of “mono-domainal” constructions and “bi-domainal” constructions finds an unexpected correlation in the syntax, where it helps us solve a longstanding problem about the realization of negation in Sinhala.
The standard way to negate a sentence in Sinhala is to use the verbal particle nææ (Gair 1970; De Abrew 1981; Slomanson 2008; Chandralal 2010). As shown in the minimal pair in (46), negation shows up in the clause-final position, and the verb preceding the negation changes its form to the so-called focus form. The morpheme indicating the focus form replaces the indicative morpheme.
- (46)

Gair (1970) treats the negation nææ as an auxiliary, as it determines the verb form of the lexical verb. He also notes that nææ obligatorily replaces the copulas innəwa/tiənəwa in copula clauses:Footnote19
- (47)
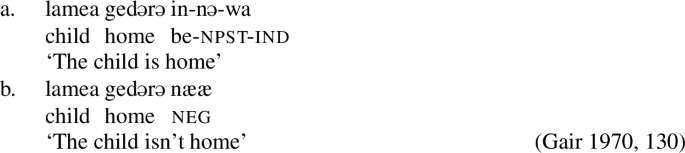
However, Sinhala shows another type of negation that does not use a clause-final particle but rather a verbal prefix no-. According to Gair (1970), De Abrew (1981), this type of negation mainly appears in dependent clauses. In (48a), we see that an embedded infinitive clause can be negated using no-. In (48b), we see a clefting structure, where the dependent embedded clause is negated with no-. In (48c), we see the cooccurrence of two negations, the auxiliary nææ in the matrix clause and the verbal prefix no- in the clause-initial adverbial clause.
- (48)

We want to stress here that examples like (48c) clearly show that the use of no- is not due to non-finiteness but rather is about embeddedness. The embedded verb in the adverbial clause in (48c) is fully finite, as it bears tense and the indicative marker. It could—without the negative prefix—readily function as a matrix verb.
Crucially, matrix clauses cannot be negated with the prefix no-.Footnote20
- (49)
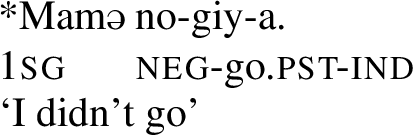
One last thing that we want to note is that it is not a difference between embedded clauses vs matrix clauses, but rather any embedded domain, such as subclausal constituents, can be negated with the prefix no-. We have already seen no- negating an infinitival clause above (48a), and we can add that the complement of the various modal auxiliaries, such as puluwan ‘can’, oonæ ‘should,’ or æti ‘might,’ can be negated with no-.
- (50)
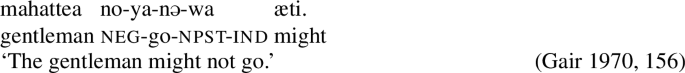
Following Gair (1970), we thus put forward the following generalization (see also De Abrew 1981):
- (51)

Against this background, De Abrew (1981), Foley and Gair (1993), Gair (2003) note, however, that there are some unexpected occurrences of no- in contexts that they do not view as embedded, including the perfect. Gair (2003, 885) notes that the precise range of occurrences of no- remains unclear, and leaves it open why perfect can be negated with no-, but the past tense cannot. Our consultant confirms that matrix clauses can be negated with no- when they are in the perfect.
- (52)

Notably, examples in the perfect can also be negated with the finite matrix clause negation nææ.
- (53)

This seems to suggest that perfect seems to, syntactically speaking, consist of two locality domains. When we negate the higher domain, the result will be the finite matrix negation nææ, and when we negate the lower embedded domain, we get the prefixal no- negation. This strongly contrasts with negation in the past tense, where negation with the prefix no- is impossible.Footnote21
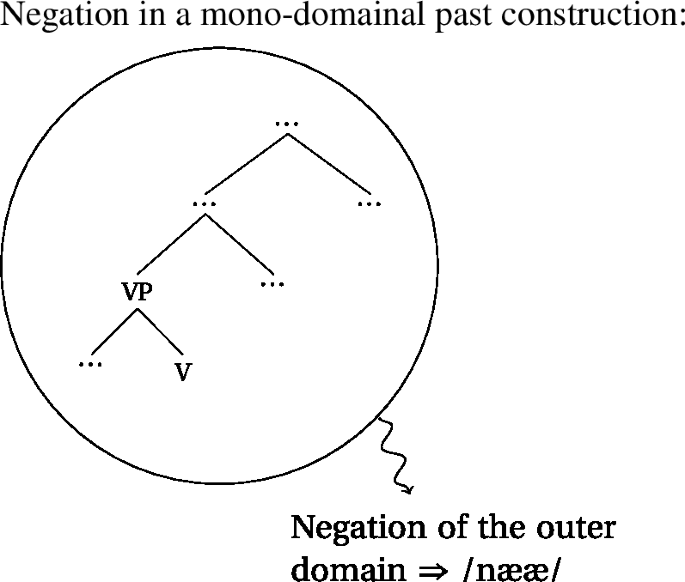
- (54)
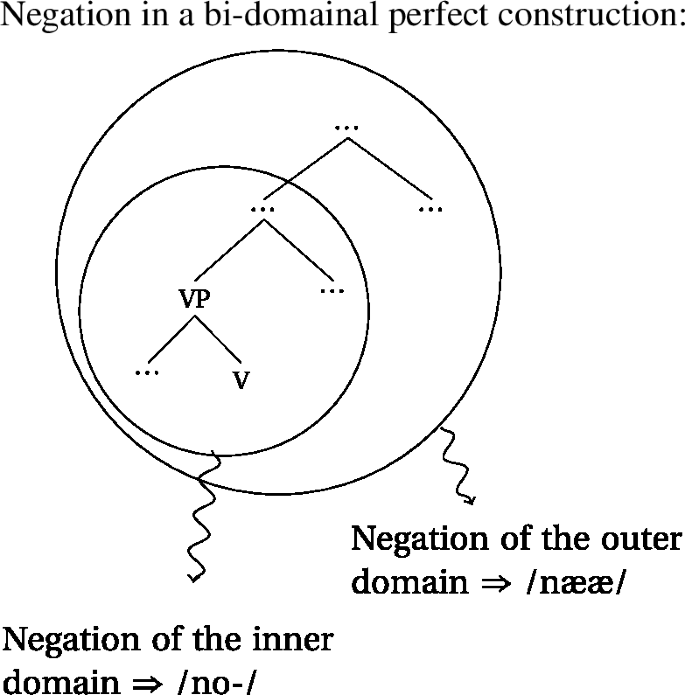
- (55)
The contrast between perfect constructions consisting of two domains and past tense constructions only consisting of one domain is strongly parallel to the domains we had to assume to account for the limits of umlaut in the preceding section. However, the parallel becomes even clearer when we take a closer look at the other weak umlaut triggers in the language. Just like the perfect, the progressive can be negated with the prefix no-, as well as the informal imperative.Footnote22
- (56)
- (57)

The example in (57b) is particularly striking, because it shows that the perfect does not simply count as embedded, because it has an auxiliary. The informal imperative also consists of two domains (in both the phonology and the syntax), even though it is not an auxiliary construction.
What this means is that we do have a strong correlation between the limits of umlaut and the applicability of embedded negation. We assumed in the phonology that the class of morphemes we dubbed weak umlaut triggers (namely, the perfect, the progressive, and the informal imperative) consisted of two phonological domains. In this section, we have seen evidence that exactly that set of morphemes characterizes syntactic constructions that, for completely independent reasons, needed to be analyzed as consisting of two syntactic domains. This contrasts with strong triggers, passive and past tense, which were analyzed as always being one domain in the phonology. And since they are not compatible with embedded negation, this means that, syntactically speaking, they are one domain in the syntax as well. Expanding on Table 1 that we used to summarize the properties of umlaut triggers in Sect. 2.3, we can illustrate the correlation in Table 2.
The empirical correlation between the two types of affixes is already very suggestive and, we think, can hardly be treated as an accident. But the fact that both of the asymmetries can straightforwardly be explained using the concept of locality domains makes the correlation even more striking.
Against the background of this discussion, we want to make the claim that this correlation is not an accident and should be compatible with the general architecture of grammar. As we noted towards the end of Sect. 2, we could simply derive the limits of umlaut with a simple reference to a difference between stem-level affixes and dual-level affixes. Similarly, we could derive the differences between the different realizations of negation in Sinhala by referring to syntactic locality domains, such as phases. However, that would not tell us anything about the correlation. It would be a total coincidence that the bi-domainal structures in phonology correspond to bi-domainal structures in syntax. Rather, we want to assume that the isomorphism we note in the table above follows from the architecture of grammar. Specifically, we believe the data presented are in line with proposals that assume there to be isomorphism between the syntactic and phonological domains (Pak 2008; Newell 2008; Embick 2010; Newell and Piggott 2014; D’Alessandro and Scheer 2015; Fenger 2020). In fact, we want to claim that the evidence for isomorphism we have presented thus far substantially goes beyond the existing evidence in the literature, as it is the first detailed case study of its kind that investigates the locality domains of a substantial part of the verbal paradigm in all three modules alike. In the remainder of this paper, we build on these proposals, where the underlying idea is that the locality domains can be inherited in a crossmodular fashion. Crucially, while the system should derive the isomorphism between syntax and phonology, it must prove flexible enough to adapt to specific ways in which the syntax and the morphology can manipulate the formation of domains. As we have seen, both the syntax and the morphology have an impact on the formation of domains.
4 The analysis: How to match domains
In this section, we present the model that we envisage that accounts for all the data in a systematic way. As we have seen in the previous sections, both the morphophonological process of umlaut as well as the compatibility with embedded negation seem to indicate that they require a solution in terms of locality domains. And, as we have emphasized several times by now, these locality domains—in completely different areas of grammar—show a surprising amount of similarity. The affixes that constitute the set of weak affix triggers characterize exactly the constructions that are compatible with embedded negation. The intuition that we want to model in this section is that this is no coincidence, and that it should follow straightforwardly from our model of grammar.
4.1 The analysis in a nutshell
The preceding sections have demonstrated the need to distinguish two classes of constructions. Moreover, we have seen a correlation between processes differing in terms of two logically independent dimensions. On the one hand, we have seen a correlation between a syntactic process (i.e., the applicability of embedded negation) and a phonological process (i.e., the applicability of umlaut). On the other hand, we have seen a correlation between a process sensitive to word-internal structures (i.e., the applicability of umlaut) and a process sensitive to the clausal or word-external structure (i.e., the choice of negation). Since these are logically independent,Footnote23 we derive them with two logically independent assumptions: The first assumption is that the syntax creates locality domains that are inherited to the morphology and the phonology (Marvin 2003; Arad 2003, 2005; Borer 2005; Marantz 2007, 2013; Pak 2008; Ramchand 2008; Newell 2008; Embick 2010; Newell and Piggott 2014; D’Alessandro and Scheer 2015; Crippen 2019; Sande et al. 2020; Fenger 2020; Guekguezian 2021). This means that, in the unmarked case, these domains will be isomorphic between the different modules. The second assumption is that domains can potentially be extended systematically in the syntax or morphology (Rackowski and Richards 2005; den Dikken 2007; Gallego and Uriagereka 2007; Newell 2008; Embick 2010; Bobaljik and Wurmbrand 2013; Bošković 2014; van Urk and Richards 2015; Halpert 2016; Wurmbrand 2017; Fenger 2020). Here, we are specifically interested in verb-movement which, when it takes the phase head along, also extends the clausal phasal domains. This assumption, typically referred to as phase extension or phase sliding (see, e.g., den Dikken 2007; Gallego and Uriagereka 2007; Bobaljik and Wurmbrand 2013; Fenger 2020), explains why word-internal locality domains correlate with clausal ones.Footnote24
Applied to our Sinhala case study at hand, we assume that strong umlaut triggers (i.e., pst and pass) are picked up by syntactic head-movement during the syntactic derivation. However, words can be built in different ways. Specifically, when they are not built through head movement in the syntax, but are built in the morphology, different configurations are expected. Specifically, we assume that weak umlaut triggers (i.e., perf, prog, and inf.imp) do not combine with their stems through head movement. They attach to the verb at a later stage in the postsyntactic module (Marantz 1988; Embick and Noyer 2001; Newell 2008; Shwayder 2015; Georgieva et al. 2021).
Crucially, the result is of this difference in word-formation is that the elements in question end up in different locality configurations. In regular, synthetic constructions (involving, e.g., pass and pst), all heads that are picked up on the way will be in the same locality domain as the verb stem. In constructions involving perf, prog, and inf.imp, we do not have head-movement up to the relevant heads so that the these heads will be located in outer locality domains. This will explain the different behavior of the given morphemes in the word-internal domain.
Since we follow recent approaches of phase-extension, we predict that there should also be correlates of head-movement in the clausal syntax. Head-movement up to C will result in a situation where there is only one phasal domain per clause. Affixes that are not attached to the verb via head-movement will result in a situation where the clause is divided into two (or more) phasal domains in a clause. And, as we have seen, the choice of negation reflects the number of phasal domains in a clause inasmuch as negation with the no-prefix is only possible in cases where the negation is not in the highest domain.
We can thus derive the distinction between the different classes of morphemes/constructions, which finds its correlates both in the word-internal as well in word-external (clausal) processes. And crucially, since we assume that locality domains are inherited, we can also derive the correlation between the syntax and the phonology.
4.2 Matching domains
This section contains the core ingredients of our analysis and illustrates how the model we set up generates the respective locality domains that then result in different patterns concerning the choice of negation, as well as the limits of umlaut.
The model that we want to develop to account for this parallel is couched in a Y-model of grammar, where the syntax draws on a very reduced (i.e., non-generative) lexicon. The elements the syntax draws from the lexicon are simple abstract features and feature bundles devoid of phonological and morphological content (Halle and Marantz 1993; Harley and Noyer 1999; Borer 2005; Caha 2009; Embick 2010; Harley 2014, a.o.). The structures the syntax creates are shipped off to PF and LF. Certain heads (phases) are triggers for shipping of this material to the interfaces in cycles, and these heads are going to be relevant for both phrasal and word-level domains (Marvin 2003; Newell 2008; Embick 2010, a.o.). At PF, the postsyntactic morphological module transforms these syntactic structures into linear strings in a stepwise fashion (Arregi and Nevins 2012; Shwayder 2015; Kalin 2022; Weisser 2024b, a.o.) and, in the course of doing that, it also enhances them with morphological and phonological features; a process referred to as Vocabulary Insertion, which occurs bottom up (Bobaljik 2000; Kalin 2022; Weisser 2024b). After Vocabulary Insertion, morphophonological and phonological rules then apply.
The idea is that every module can have a limited effect on the formation of locality domains, which will affect the modules later in the derivation. The effects of the syntactic derivation will affect the morphology and the phonology, while the morphological derivation will only affect the phonology. Crucially, the syntax remains completely unaffected by what is going on in the morphology. In what follows, we will go through the modules and the respective interfaces between the modules, and illustrate how each module manipulates the locality domains.
4.2.1 The matching of domains from syntax to morphology
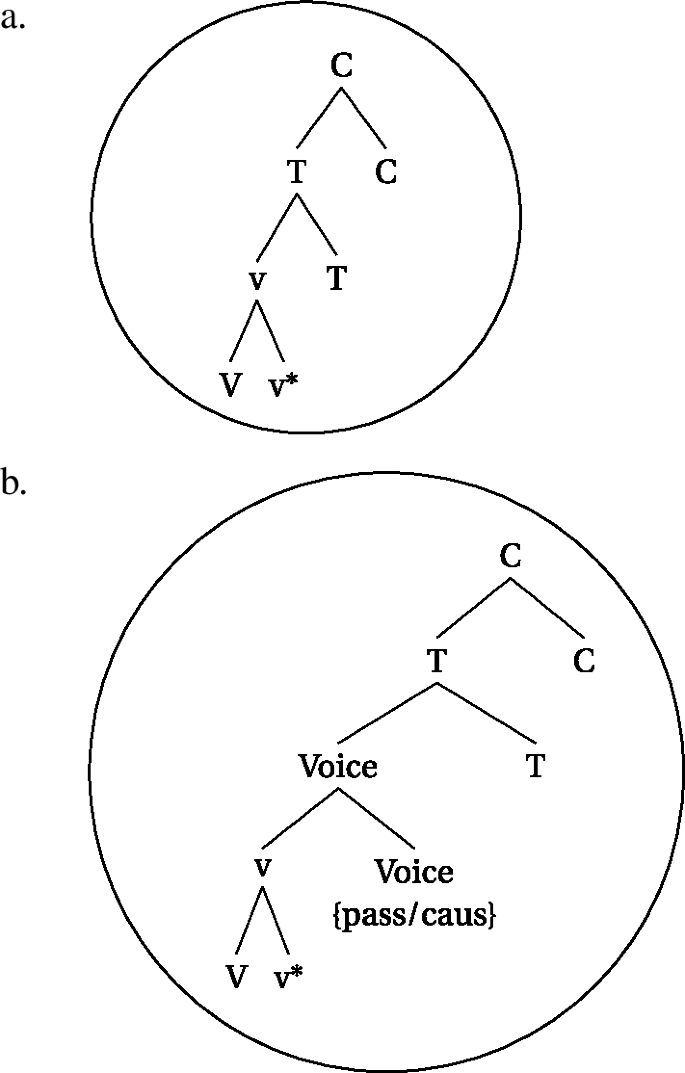
We begin with the syntax, and we focus on the question of how the syntax creates locality domains that are relevant for processes in the subsequent modules. To begin with, we assume that some features (or heads) in the reduced lexicon are specified to be domain delimiters, or, to use a more conventional term: phase-heads. To be more precise, we follow standard assumptions in the current literature and assume that v and C are phase-heads (Chomsky 2001, 2008). We stay agnostic as to whether this is a universal property of languages in general, or whether this is specific to Sinhala. We represent phasehood status with an asterisk (v*, C*).
- (58). v*, C*
These phase heads are triggers for syntactic operations (such as head movement) and for sending material to the interfaces, and when these heads are (re-)moved in the syntax (elaborated on in this section) or the morphology (elaborated on in the next section), the domains can alter minimally. Since CPs will, by assumption, remain to be phases throughout, we will, in what follows, mainly be concerned with the phasehood-status of v, which we will take to be the location of the verbal class marker. For concreteness sake, we assume PIC2 (Chomsky 2001), which means that v will only be sent to the interfaces when the next phase up (CP) is merged.Footnote25
The assumption that v is lexically specified as a phase-head does not necessarily mean that vP (or VP) will inevitably be the phasal domain, that is, the locality domain that will be spelled out. Rather, we follow works that argue that phases can be defined contextually, which we implement by saying that movement of a phase-head extends the phasal domain (see specifically den Dikken 2007; Gallego and Uriagereka 2007; Fenger 2020). This means that head-movement of v* into the higher domain will mean that all affixes that end up in the same complex head will be in the same locality domain.Footnote26 Crucially, this means that syntactic head movement is an operation that can bleed C sending the v*P to the interfaces, since it happens before phases are shipped to the interfaces. The different orders of operations are clear when considering a simple tense and a perfect construction.
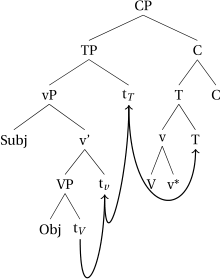
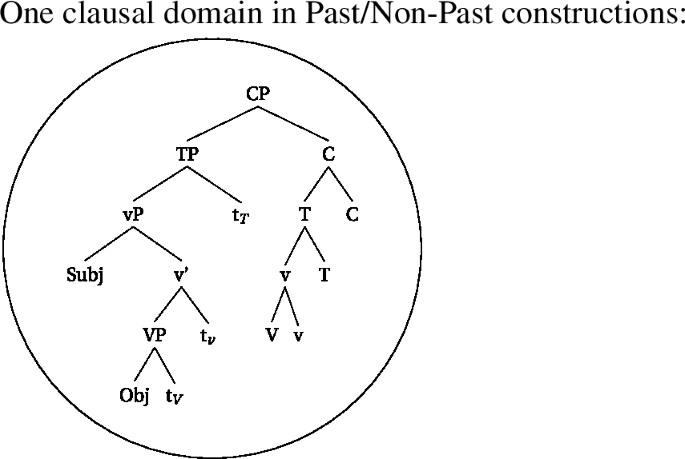
Consider the different derivations for a verb in the past tense as opposed to a perfect construction. As we already gave away above, we assume that strong triggers, such as passive or past tense, are picked up via head-movement, whereas weak triggers are not. In (59), we see a synthetic construction clause, where the verb moves up to v*, which moves up to T, which moves up to C (head-movement indicated by the solid arrows).Footnote27 Since T attracts V-v* before C sends material to the interfaces, a single syntactic (and spell-out) domain is created. We assume that the verbal class marker in class 1 is an instantiation of v, and therefore a derivation as in (59) will result in a simple verb form, such as (60).
- (59).
- (60)
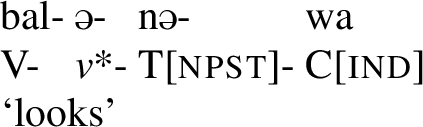
After head movement has taken place, there is a single domain created in the syntax (at the CP level), and in the morphology (the complex head headed by C), which will be shipped off to the interfaces. As a result of the derivation in (59), affixes like tense (past or non-past) will always be in the same locality domain as the verbal root during spell-out, as indicated by the circle in (61a).Footnote28 The same holds for instances of Voice (passive and/or causative), which, by assumption, can also be targeted by head-movement.
- (61)
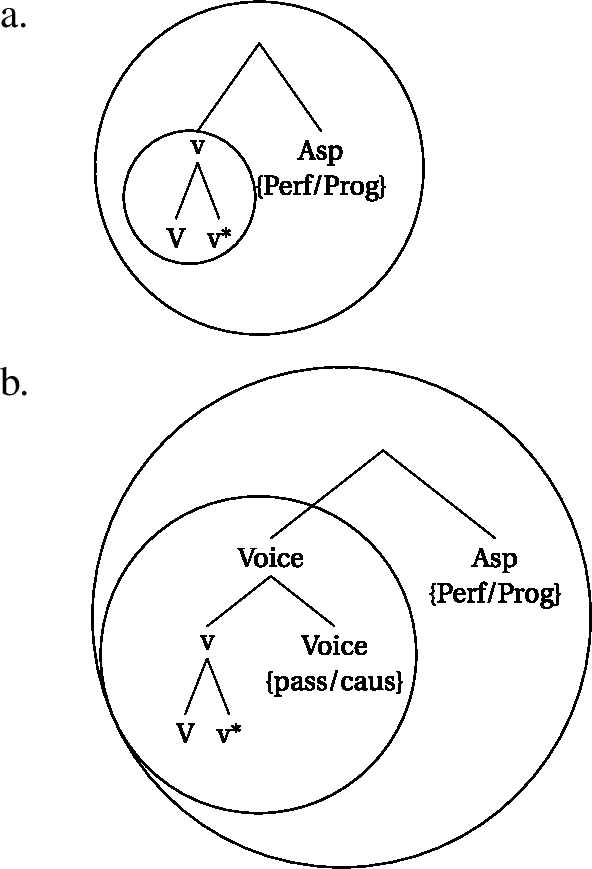
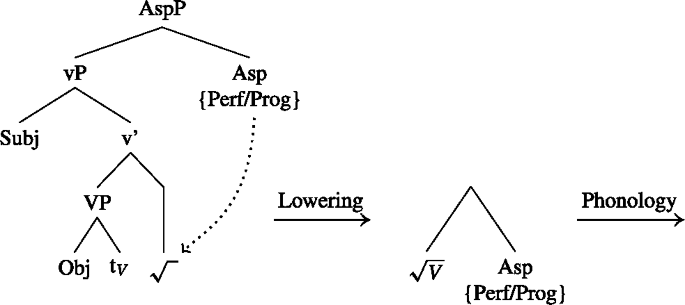
In (63), we see a construction where an aspectual head intervenes between v* and T. Since Asp blocks head-movement,Footnote29 head-movement only applies from V to v* and stops there, and these units (vP and v) are sent to the interfaces, once the higher phase head (C) is merged. This means that the Asp head cannot form a complex head with the verb in the syntax. It is only attached in the postsyntactic module through some later cliticization process.Footnote30 (Cliticization indicated by the dotted arrow). In this configuration, T and C will be expressed by an auxiliary.
- (62).
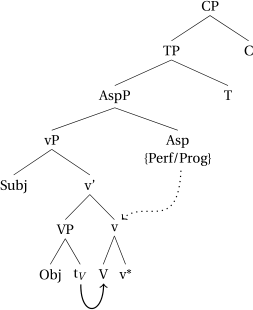
- (63)
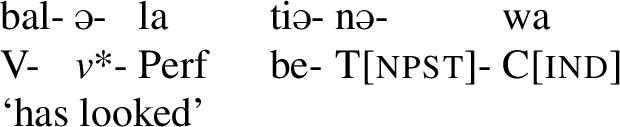
The derivation in (62) will thus result in a different locality configuration from simple tenses. Since heads like Perf or Prog are not allowed to be targeted by head-movement, the resulting domains look as follows. In (64a), the aspectual head is not part of the innermost domain. The innermost domain only contains the verb and v*, which is spelled out on an earlier cycle. If there is an additional Voice head in between, head-movement will target that Voice-head but stop there. The result are locality domains as in (64b). Note that the representations are about the locality domains, and do not represent full derivations. See Sect. 4.5 for full derivations, where the inner domain is already phonologized, at the point where Asp clitizes.
- (64)
As for the informal imperative, we assume a similar structure as for the aspect configurations. Clearly, a more detailed investigation of the structures of the different types of imperatives in Sinhala is required, but for now we assume that imperatives attach directly to a vP or a VoiceP, but disallow head-movement of v* in very much the same way as the aspectual heads prog and perf do (see (65)). The result is a locality configuration as in (66), where the informal imperative head is outside of the innermost locality domain.Footnote31
- (65).
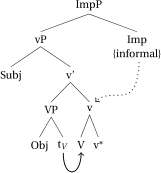
- (66)
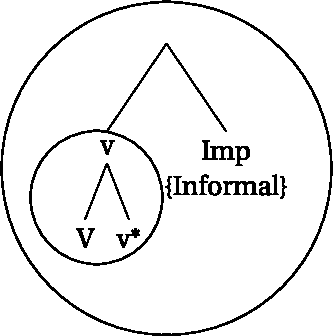
To sum up, we assume that the difference between the two classes of morphemes (i.e., strong vs weak triggers) is due to a difference in word-formation. Strong triggers will allow head-movement of v, whereas weak triggers will not. They will attach to the verb at a later point in the derivation. These differences in the respective word-internal locality configurations will allow us to derive why some umlaut-triggers (i.e., pass, pst) will always be able to trigger umlaut and others do not.
However, as we have seen, the differences between the two classes of morphemes also extends to the word-external domain. We thus follow (den Dikken 2007; Gallego and Uriagereka 2007; Bobaljik and Wurmbrand 2013; Bošković 2014; Fenger 2020, a.o.) in assuming that phases can be contextual, which we model through head-movement. What this means is that head-movement of the phase-head v* up to T (or even higher) extends the phasal domains up to the final landing site of the head-movement. In essence, this means that configurations involving head-movement up to C will contain only one phase per clause, whereas configurations where head-movement stops at v* will contain two phases per clause. The former is shown in (67) with an exemplary structure for a regular analytic verb form. The latter is shown for a perfect clause, but similar configurations are found with progressive or informal imperative structures.
- (67)
- (68)
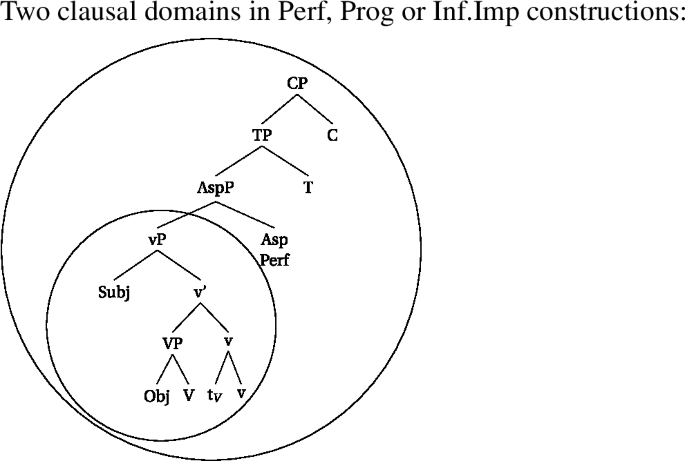
This difference in locality domains in the clausal syntax will help us to derive why only the structures in (68) are compatible with no-negation.
4.2.2 The matching of domains from morphology to phonology
So far, we have devised a system where the syntax creates locality domains depending on the concrete syntactic configuration. Some heads, such as voice (caus or pass) or tense (npst or pst) allow for head-movement and will thus always be inside the innermost domain of the verb. As a result, these heads will, if they are umlaut triggers, always be able to trigger the umlaut process. Since head-movement extends the locality domains in the syntax, we see the effects of the extension of domains in the syntax, the morphology, and the phonology.
Other heads, such as the aspectual heads (prog or perf), as well as the informal imperative, do not allow head-movement and will thus be located outside of the innermost domain of the verb stem. This is, however, not yet the result that we want, because, given a simple implementation of the umlaut process as such, it would predict that these heads should never be able to trigger umlaut since they are not in the same domain. However, as we have seen, these heads can trigger umlaut in a specific configuration, namely when they are adjacent to the verb stem, as no class marker or causative affix intervenes. Since we assume the class marker in class 1 to be a realization of v*, this raises the question of what happens in class 2, where we argued in detail in Sect. 2.4 that no class marker is present in the morphological structure. In other words, we have evidence that class 2 has no v* in the morphological structure, but we do not know whether it does so in the syntax. So, we could either say that both classes have a uniform underlying syntax, and that they differ only morphologically, or we could say that the two verb classes differ substantially in the syntax already, in the sense that class 2 verbs, unlike class 1 verbs, do not have a v* (see, e.g., Borer 2014). At this point, we take this to be largely an analytical choice, as our toolbox unfortunately lacks a syntactic diagnostic to find out whether there is actually a v* in class 2. For now, we decide that, in absence of evidence that the two verb classes behave different in the syntax, we will assume that they are the same. In other words, we will assume that the difference is purely morphological. The reader is referred to Sect. 5.2, where we discuss the implementations and the implications of the syntax-based alternative in detail.
We thus model the difference between the presence of a class marker in class 1 and the absence of a class marker in class 2 by application of an obliteration operation (Arregi and Nevins 2007; Calabrese 2010; Pescarini 2010; Arregi and Nevins 2012). As defined in Arregi and Nevins (2012), obliteration deletes the entire terminal node from the structure in response to a markedness requirement.Footnote32 For the purposes at hand, we assume that obliteration deletes the v-head if it does not contain any additional marked features. The representation of verb class in Sinhala we adopt is given in (69). In the case of class 3, these features have some morphosemantic content, as this class only includes intransitive verbs and has some non-active semantics (see Beavers and Zubair (2012)). In class 1, however, we are forced to assume that the marked feature is a purely morphological one (CL).
- (69)

- (70).[ v* ] ⟶ ∅
The result of this obliteration rule will be that, in class 2, the entire v-head will be deleted early on in the postsyntax. In what follows, we will elaborate on how this plays out. First, consider a derivation where a verb from class 2 is combined with a causative head. We assume further that this configuration is embedded under an Asp-projection. In this case, as discussed in the previous section, a complex head is built, including the root, v*, and Caus, by means of head-movement. But since Asp does not participate in head-movement, the complex of the root, v*, and Caus is the whole complex that is shipped to the interfaces. At this point, morphological operations apply. Since we are dealing with a verb from class 2, v∗ has no marked features and is thus obliterated (71). This is not a problem. Since Caus is part of the extended projection of the verb, the phonology knows that we are dealing with a verbal structure and can proceed as usual. This means that the whole complex can be phonologized. The result will be a simple root of class 2 with a causativized morpheme to which, on a later cycle, the aspectual morpheme will be added.
- (71)
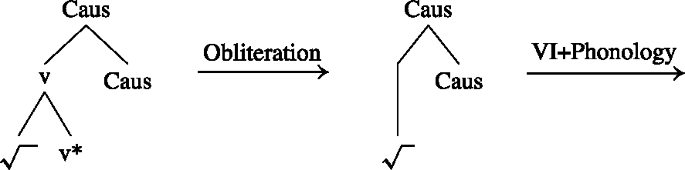
The important question now is what happens when obliteration deletes the v∗-head, but there are no other heads like the causative that attach to the root. On the first cycle in the syntax, the complex head with the root and v* is built, and in the CP phase there is no further head movement, which means that the v*P phase is shipped to the interfaces. Thus only the complex head with the root and v* will undergo further operations. Since v* is unmarked, it will be obliterated, as indicated in (72).
- (72)

However, the crucial assumption here is that, in this case, the derivation cannot proceed, because the postsyntactic derivation and the cyclic phonology requires information about the basic category that the root belongs to.Footnote33 It is a standard assumption in DM that categorizers like v or n are required to include roots in the structure (Marantz 1997; Harley 2005; Embick and Marantz 2008). Following the logic in Embick (2021), we assume that the reason for this is interface-related. PF and LF need to know the category of a root to interpret it. As we are concerned with PF, we will thus assume the following corollary to hold:Footnote34
- (73). Uncategorized roots cannot be phonologized
What this means for us is that phonology cannot deal with just a bare root, and thus, when the categorizer is obliterated, the PF-derivation will not proceed. In the case at hand, the category information is provided upon the second cycle when Asp lowers onto the root since Asp is, like the causative above, part of the extended projection of the verb.
- (74)
Crucially this is the only configuration where there is exceptional integration of a head from an outer phase into the inner phase. Only when the bare root is what is left in a spell-out domain is the PF-derivation halted. Then, the VI and cyclic phonology is postponed until an element from a higher domain attaches and disambiguates the categorical properties. In other words, the only configuration when an outer affix can attach to a root which has not undergone VI and cyclic phonology is when that affix attaches to the root directly, without intervening affixes.
This assumption derives the ambivalent behavior of weak umlaut triggers, such as the perfect, the informal imperative, and the progressive. In Sect. 2.6, we already likened their behavior to the notion of dual-level affixes. These affixes are usually thought to be outside of the stem-level domain, but can exceptionally be integrated into the inner domain in specific configurations. This is exactly the intuition that we modeled with the steps above. Weak triggers are usually outside of the innermost domain, but can exceptionally be integrated into the domain if they are root-adjacent. If they appear next to a class 1 verb, then no obliteration of v* will take place, and they will appear outside of the innermost domain, thus unable to trigger umlaut. That demonstrates why weak triggers never trigger umlaut with class 1 verbs. Similarly, if they appear with class 2 verbs but with an intervening causative, then they will similarly not be able to trigger umlaut, because the presence of the causative will be enough to have the morphophonology proceed as usual. This explains why weak triggers will not be able to trigger umlaut across a causative. Only when they are root-adjacent, will they get a chance to trigger umlaut.
Let us briefly recap what the discussion above means for the resulting domains in the respective modules. We start out with two lexically specified phases in the language, which are triggers for spell-out, and, specifically for the case at hand, also for word formation and for the terminal nodes to receive phonological information. The two heads are v* and C*, and a priori this will, in the default case, lead to vPs and CPs being the respective locality domains in all modules. As we have seen, however, two processes can—practically speaking—have an impact on the locality domains: First, there is head-movement, which can extend the domain in the syntax already. If the verb moves all the way to C*, then the result will be that the CP as well as the complex head in C will be the respective locality domains. The other process is obliteration. If v* is obliterated, then it might be that, in some cases, an element of an outer cycle (Perf, Prog, Inf.Imp) can exceptionally be integrated into the inner cycle, because the phonology cannot apply to bare roots. Head-movement extends the locality domains in the syntax already, and these domains are mapped to the subsequent modules. The domains then are isomorphic among syntax, morphology, and phonology. Obliteration, on the other hand, can potentially lead to cases of non-isomorphism, because the application of the purely morphological operation will leave syntactic domains unaffected, but will change the domains for morphology and phonology. In a configuration where there is no head-movement of v*, obliteration will lead to a situation where the aspect phrase is part of the higher domain for syntactic purposes, but integrated into the lower domain for morphological and phonological purposes.
Thus, the system here follows other work in that there is, in the basic case, isomorphism between syntax and phonology, but there are independent operations in the language that can change this at various stages. Having established the formation of domains across modules, we now have the tools to provide a comprehensive analysis for the data we observed in Sects. 2 and 3. Before we show the concrete derivations, we need to introduce some preliminary assumptions about how to model umlaut, as well as on how to derive the behavior of negation. This is done in the next two subsections.
4.3 The analysis of umlaut
In Sect. 2.5, we have already taken a closer look at the operation that is umlaut, and we concluded that it is substantially different from morphological operations for a number of reasons: (i) Umlaut is exceptionless inasmuch as it applies to every verb in the language. (ii) It triggers a completely predictable phonological change in all of these verbs, and (iii) it obeys different locality domains than purely morphological processes, such as suppletion: While suppletion requires immediate adjacency, umlaut does not, but umlaut does require being in the same locality domain.
We concluded from these facts that umlaut is a phonological process. Accordingly, we model it as such, and we follow most of the literature on umlaut in German(ic) by Lodge (1989), Yu (1992), Lieber (1992), Wiese (1996), Trommer (2021), and the treatment of umlaut in Sinhala in Parawahera (1990). We treat it as a floating feature that determines the quality of an underspecified vowel on the stem.
To be precise, we adopt the following assumptions: First, vowels in Sinhala are either positionally specified for [–back] or underspecified. Leaving the schwa aside for now, we thus arrive at the following specifications of the six vowels in Sinhala:
- (75)

The vowels /u/, /o/, and /a/ are underspecified for the feature [±back]. In what follows, we will represent underspecified vowels in upper case. When they remain underspecified until the end of the given phonological cycle, then the vowel is fixed as the default back vowel. This is shown in (76). Here we see a class 1 verb 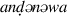 (‘cry’) that bears the respective class marker, the non-past marker and the indicative marker. Underlyingly, we assume that the vowel of the verb is underspecified for backness (hence capital A). Since none of the affixes in this configuration is an umlaut trigger, the vowel will be specified as [+back] by default, yielding the correct surface form.
(‘cry’) that bears the respective class marker, the non-past marker and the indicative marker. Underlyingly, we assume that the vowel of the verb is underspecified for backness (hence capital A). Since none of the affixes in this configuration is an umlaut trigger, the vowel will be specified as [+back] by default, yielding the correct surface form.
- (76)
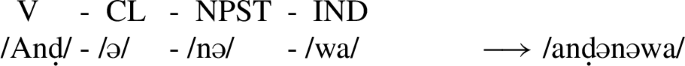
The second crucial assumption is that some suffixes bear a floating umlaut feature, which we will represent as a superscript [–back]. This feature will associate with all underspecified vowels to its left in a given domain and cause them to be realized as [–back]. In (77), we have a minimally different configuration from (76) above. The only difference here is that we have a past tense marker, which introduces the floating umlaut feature. This feature will associate with the underspecified vowel and result in a fronted vowel on the stem.Footnote35
- (77)
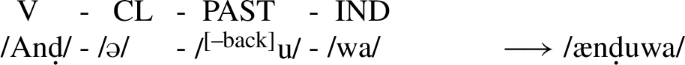
We want to emphasize here that the association of a floating feature with an underspecified vowel is constrained by the locality domains we set up in the preceding sections. If a stem with an underspecified vowel is located in a domain that does not contain a floating feature, its vowel quality will be fixed to default back. Potential floating [–back]-features in subsequent cycles will not be able to change that anymore.
4.4 The analysis of negation
In this section, we briefly introduce our necessary assumptions about the analysis of negation in Sinhala. We will focus only on the use of the negation prefix no-, as the compatibility with the no-prefix was the crucial factor distinguishing between the two types of constructions. We will therefore leave a discussion of the verbal auxiliary negation nææ for future research.
In Sect. 3, we ended up with the following generalization about the distribution of no-:
- (78). The verbal prefix no- is used to negate embedded domains.
As we have seen, the prefix no- can negate finite and non-finite subordinate clauses, infinitival clauses, and complements of modal auxiliaries. It is also compatible with constructions in the perfect, the progressive, and the informal imperative. We thus take it that it can (at least) attach to extended vPs and CPs. In addition, we assume that, unlike the verbal particle nææ, which has many auxiliary-like properties, no- is adjoined to the category it attaches to.Footnote36 This explains, for example, why no- does not change the verbal morphology of the lexical verb, whereas nææ does (see Georgieva et al. (2021) for similar argumentation for the adjunct-status of constituent negation in the Finno-Ugric language Mari).
To account for the fact that no- is a bound morpheme, we assume that it lowers onto the head of its verbal complement. Given what we have said about domains in the preceding sections, this predicts that just like a perfect morpheme, for example, no- is outside of the innermost stem domain, an assumption that is supported by the fact that no- does not undergo umlaut when it is followed by a strong umlaut-trigger. Even though no- contains a back vowel that could possibly front in umlaut contexts, it does not. Despite the fact that we have a past verb form, the form of the negation does not front and change to *ne-. This suggests that negation is in an outside domain or at least too high to be affected by umlaut induced by the past-tense marker.Footnote37
- (79)

We thus assume that the structures for no-negation are like the following: In (80), we see a structural configuration where negation is adjoined to a CP. Similar to the aspectual heads, it lowers onto the head of its complement, creating a complex head as in (81). Unlike aspect and the informal imperative, negation is exceptionally specified to be a proclitic rather than an enclitic.Footnote38
- (80)
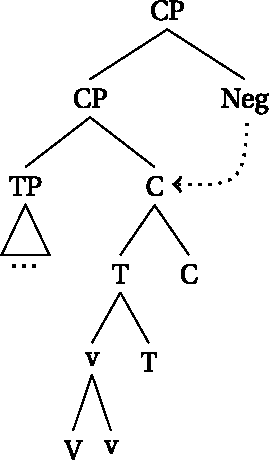
- (81).
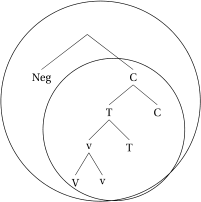
However, it is not just category selection that matters for the negation choice, since we saw that no is incompatible with main clauses with an analytic past or non-past tense verb:
- (82)
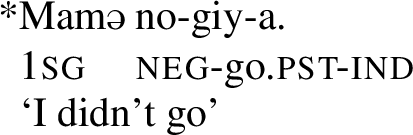
In order to derive this distribution, we make the additional assumption that negation probes for the root clause feature and no- is only licensed in [–R]-contexts. If it finds a C-head that is non-finite, it will be valued for [–R]. Crucially, if it cannot find a [±R]-feature, the probe will remain unvalued. In that case, the feature will default to [–R].Footnote39
- (83). [Neg, –R] ↔ /no-/
Consider briefly the two configurations, (86) and (87). In (84), on the left-hand side, we see a regular synthetic verb form in the past. Here, there is only one clausal domain spanning all the way up to C. If that C is the head of a root clause, it bears the feature [+R], and thus values the probe on the negation with [+R], and the no-negation is not possible. If it is an embedded C, it will value the probe negatively, and no- is possible. In (85), we see the negation attaching to a lower domain (a vP by assumption). In this case, the probe on Neg will not find the [±R] feature, as it is contained in another domain, and it will thus remain unvalued. Since the unvalued probe will thus default to [–R], no- can be inserted. The result is that no- is always possible with two domains in the clause, as it can then attach to the lower one where its probe will be unable to see the root feature on C.
- (84)
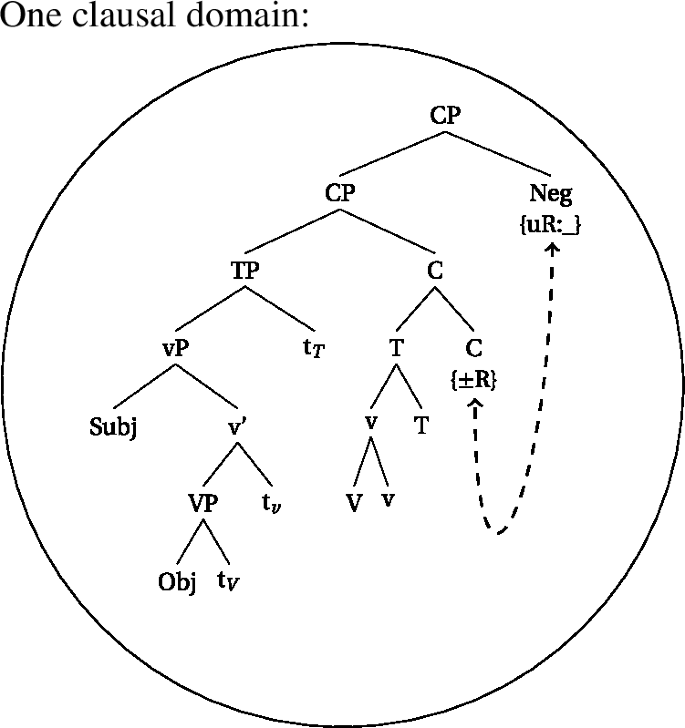
- (85)
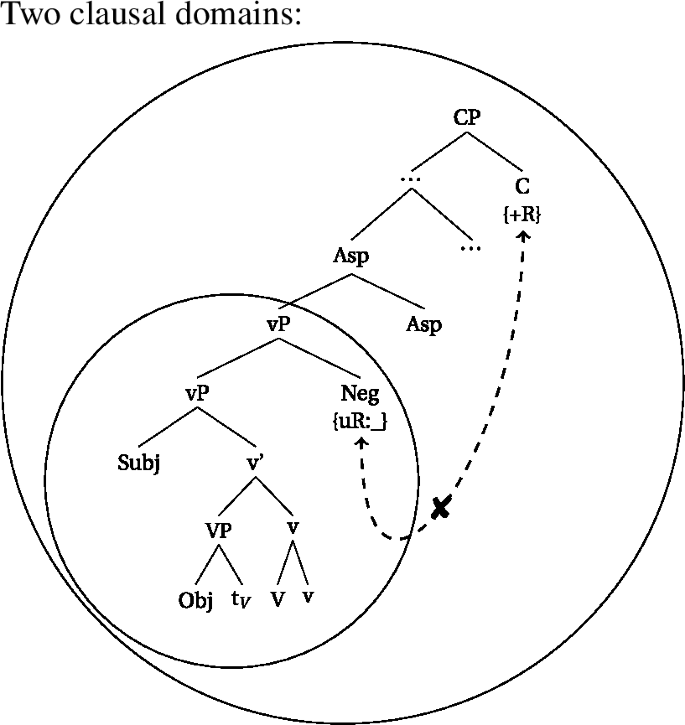
We now have all ingredients in place to derive the data patterns observed in Sects. 2 and 3. In the next section, we will illustrate some selected derivations to show how the system works and that the formation of domains makes the right predictions for the crucial configurations.
4.5 The derivations
In the previous sections, we have given all necessary pieces required to explain the data observed in Sects. 2 and 3. Moreover, we have sketched a model that offers a principled explanation for the correlations that we have seen. On the one hand, we had the correlation between word-internal domains and word-external domains, and on the other hand, we had the correlation between the syntax and the phonology. The former correlation was derived by building on the established mechanism of phase-extension: the domains in the clausal syntax mirror the word-internal domains. The latter correlation was derived by assuming a model of grammar where domains are inherited from the syntax into the morphology and the phonology.
In what follows, we go through some selected derivations to sketch how the individual puzzle pieces fit together. To be precise, we will focus on derivations of class 2 verbs, as this is the class where the crucial interactions between domain formation and obliteration happen. Class 1 verbs can nonetheless be derived straightforwardly. Section 4.5.1 begins with simple mono-domainal tense forms, where both the clausal syntax and the word-internal structure consist of only one domain. Section 4.5.2 then moves on to the more complicated cases, where we have two domains, word-internally as well as word-externally.
4.5.1 Mono-domainal structures
In order to introduce the system, as well as the notation we are using for the domains, we start with a simple synthetic verb form of a class 2 verb, such as the one in (86):
- (86)

As in all simple tenses, we assume head-movement of the verb all the way to C, which has the consequence that there will be only one domain both word-internally and word-externally. As a result, the sentence in (86) cannot be negated using no-. Even if the negation-head was adjoined to vP, it would be able to agree with the [+R]-feature on C, as there is only one domain. The one domain is then shipped off to the postsyntax, where v is obliterated since the verb is a class 2 verb and v remains unexponed in class 2. Since C/CP is the only domain in this case, obliteration of v has no effect on the domain formation. Then Vocabulary Insertion (VI) applies. We assume that VI applies bottom-up, starting with the most deeply embedded node.Footnote40 Similarly, we assume that some cyclic phonological rules apply after every step of VI, but postcyclic rules apply after all VIs in a given domain are inserted. Of particular interest for our discussion here are the postcyclic rules in the table below, (89). The first one, here called cluster resolution, inserts the epenthetic /i/ after consonant-final stems. The second rule, here called default to [+back], assigns all underspecified vowels to their default feature [+back].Footnote41
Let us begin to look at the derivations with a simple synthetic verb form of class 2, such as the one in (86).
- (87)
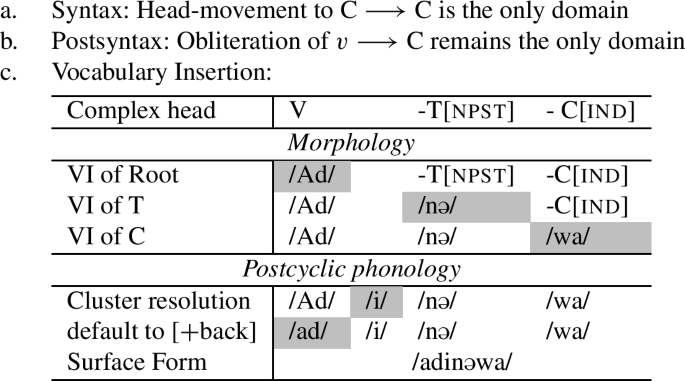
A few words on the notation of the table in (87c). We give the hierarchical input structure in the first line, and then every line indicates one step of VI. The shaded cells on each line indicate the respective changes. First, we insert the root, which at this point contains an underspecified vowel /A/. Then, we insert the non-past morpheme /nə/ and finally, the indicative mood morpheme on C. In the postcyclic phonology, the epenthetic vowel /i/ is inserted to avoid the consonant cluster, and the underspecified vowel defaults to [+back] since it has not associated with a floating [–back]-feature at that point.
Let us move on to the next derivation, which also depicts an analytic verb form of the same class 2 verb. This time, we include a causative voice head and a past tense morpheme instead of a non-past morpheme.
- (88)
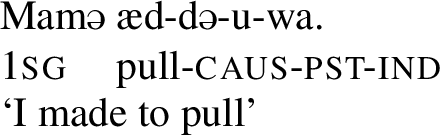
Again, we have head-movement all the way up to C, which yields only one domain, which in turn predicts correctly that no-negation is not possible in these cases. Since we are dealing with a class 2 verb, obliteration of v applies, but again, has no effect on the formation of domains.
- (89)
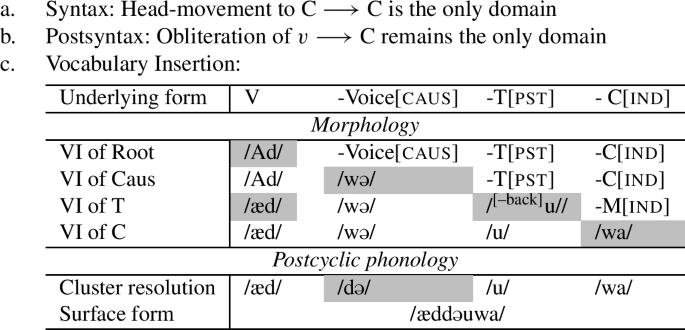
First, we insert a stem with an underspecified vowel /A/. Then, we insert the causative voice morpheme. Then, we insert the past tense morpheme /u[–back]/. The floating feature immediately associates with the underspecified vowel in the root, leading to fronting of that vowel. Finally, we insert the indicative mood morpheme. In the postcyclic phonology, we again employ a rule to avoid the consonant cluster. However, this time, the effect of the rule is one of gemination (due to the respective qualities of the underlying consonants in the cluster). Since there are no underspecified vowels in this derivation anymore, the default to [+back]-rule does not apply (or applies vacuously).
Derivations of simple tenses always involve head-movement to C, resulting in only one domain (both in the word-internal and the word-external structure). As a result, no-negation is (in matrix contexts) disallowed, and a floating feature on any of the affixes inside the verbal complex will always be able to associate with an underspecified stem vowel.
4.5.2 Bi-domainal structures
In this subsection, we will discuss two derivations that involve two perfect configurations, resulting in two domains. We begin with a causative perfect construction, as in (90).
- (90)

We have a syntactic derivation where the verb moves up to v, and both move up to the causative Voice-head. But since Asp blocks head-movement, we get two clausal domains, one being VoiceP, and one being CP. As a result, no-negation is possible since we can negate the lower domain. The lower domain is shipped to the postsyntax, where v is obliterated, but since we have had head-movement to Voice, the phasal domain is already on VoiceP anyway. As a result, the aspectual head is outside of the domain. The two tables below illustrate the cyclic derivation.
- (91)
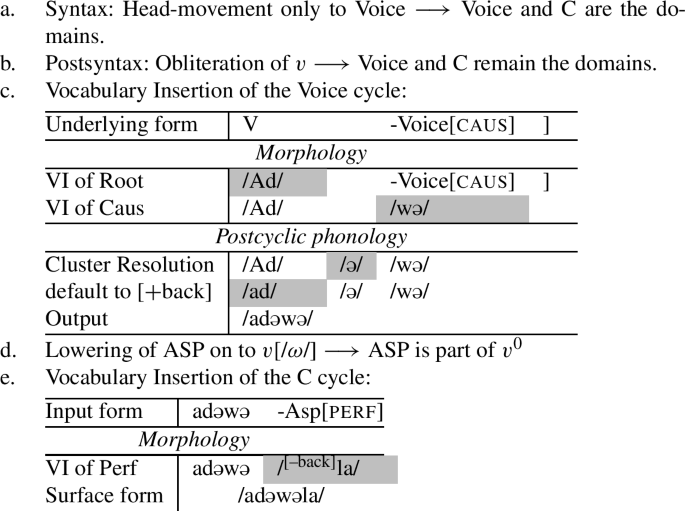
Vocabulary Insertion starts bottom up in the inner domain (i.e., the domain delimited by Voice). We first insert the root, and then the causative voice head. In the postcyclic phonology, we insert an epenthetic vowel,Footnote42 and, crucially, the underspecified vowel on the stem is now assigned the default value [+back] since none of the exponents in this cycle came with a floating [–back]-feature. The output of the first cycle is then used as the input to the second cycle, and the aspect head can at this point lower onto the phonologically formed verb, and on this cycle, then, only the aspect head is inserted.Footnote43 The exponent for the perfect head does have a floating [–back]-feature, but since there are no underspecified vowels here, it will not be able to associate. The result is that perfect cannot trigger fronting across a causative. None of the crucial postcyclic phonological rules apply in the second cycle and the surface form is /adəwəla/.
Let us come then to the final derivation that we want to talk about, namely the crucial derivation where the perfect can actually trigger umlaut on a verb stem. We again take a class 2 verb, but this time there is also no causative voice head in the derivation.
- (92)

In this derivation, we have head-movement of the verb to v, but since the next head higher up (Asp) does not allow it, the verb ends in v. The syntactically generated domains are vP and CP, which correctly predicts that no-negation should be possible. At this point, obliteration of v applies, and since there is no other head available, the root cannot be interpreted and the derivation is halted. On the second cycle, Asp then moves to the verbal complex. This results in the exceptional configuration that Asp can now be spelled out together with the root.
- (93)
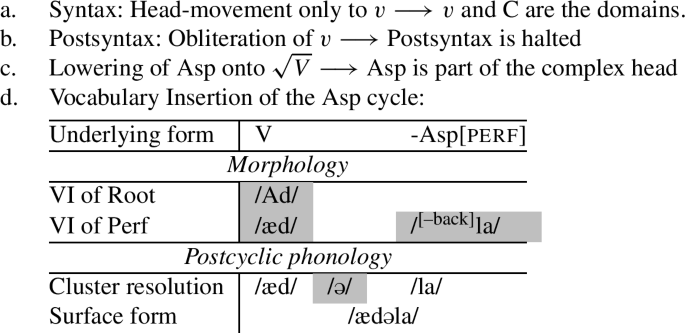
These derivations conclude the analysis section, in which we have shown the derivations for all crucial verb structures involving class 2 verbs. Derivations in class 1 will not involve obliteration, and, as a result, the phonological cycles match up perfectly with the ones generated in the syntax. In the derivations above, we have shown how the interplay between the syntactic domain formation, the morphological obliteration rule, and our assumptions about the concrete analysis of umlaut as well as no-negation derive the data we have seen in Sects. 2 and 3 in a systematic way. The section that follows takes a step back and offers a discussion of our core points from a more general perspective.
5 Discussion
5.1 Locating our proposal against the background of the literature
Recent years have seen a heightened interest in the way locality domains match or mismatch across grammatical domains. The literature on the syntax-phonology mapping is generally taken to fall into two camps, which are typically distinguished on the basis of whether they subscribe to the assumption that the categories of the prosodic hierarchy (Nespor and Vogel 1986) are to be seen as primitives of the theory or whether they are not. So-called indirect mapping approaches assume that syntactic categories and constituency are mapped onto purely phonological categories, such as phonological words or phrases, which phonological and prosodic rules can then refer to.Footnote44 So-called direct mapping approaches deny the existence of categories like phonological words or phrases and assume that the syntax (plus potentially some postsyntactic operations) will directly produce the locality domains that phonological and prosodic operations need to refer to. In such a theory, phonological rules can, for example, be sensitive to whether the trigger and the target of a rule are part of the same phase.Footnote45 However, as also noted by Elordieta (2008), Bennett and Elfner (2019), the clear dichotomy between direct and indirect mapping approaches is too simplistic, and several mixed models have been proposed by now. Kratzer and Selkirk (2007), for example, advocate for an indirect mapping approach that is crucially based on the notion of the syntactic phase, whereas Pak (2008) argues for a direct mapping approach that nonetheless includes so-called holding bins, where prosodic material can be stored to account for cases where prosodic phrases required to model speech rate effects seem substantially bigger than syntactic phases. Thus, Bennett and Elfner (2019) conclude that the space between direct and indirect mapping approaches might be better classified as a continuum (see also Wagner 2010) measured by how close the prosodic structure tracks the underlying syntax.
Against the background of this discussion, our stance is that it strikes us as methodologically the best option to assume, as a null hypothesis, that locality domains across different modules match, and that we only posit mismatches whenever the empirical evidence forces us to. In that sense, we follow the tradition of direct mapping approach cited above. We further follow this tradition in assuming that locality domains are inherited from the syntax to the morphology and the phonology. As we pointed out throughout our analysis section, we also take over quite a number of basic mechanisms from this literature, such as the fact that syntactic verb-movement can lead to mono-domainal structures (den Dikken 2007; Gallego and Uriagereka 2007; Fenger 2020) and postsyntactic processes like lowering, creating ontologically slightly different (i.e. looser) constituents (see especially Embick and Noyer 2001; Newell 2008; Fenger 2020; Georgieva et al. 2021). So, in a sense, you could see our case study, as well as the theoretical implementation, as providing a nice piece of supporting evidence in favor of that particular line of research. And while this is certainly true, we would like to claim that we go beyond the above-cited works in various respects.
First, on the empirical side, we would like to claim that we provide what we believe to be the most comprehensive investigation of crossmodular mapping of locality domains to date. Unlike most of the literature in this area, we look at three consecutive modules to make claims about the existence or non-existence of a given locality domain for that module. Many of the existing works merely investigate locality domains in one module and compare them to the locality domains standardly assumed in other modules. This line of argumentation is, however, significantly less convincing than finding concrete pieces of evidence that locality domains are referred to by different modules in the very same configuration.
Further, a large part of the existing work compares locality domains in different modules but restricts itself to one minimal pair (as in D’Alessandro and Scheer 2015). In contrast to these works, we investigate a substantial part of the verbal paradigm of Sinhala in three grammatical modules and provide evidence for the existence or non-existence of a locality domain for each module in each configuration. Only in doing so, can we map out exactly where the domains match and where they mismatch (and if so, between which module).
Secondly, a particularly interesting contribution of our paper that we want to emphasize here is that our model is one of the first ones to discuss and explain correlations between word-internal phases and word-external phases. The literature on the syntax-prosody mapping has largely focused on (a) the matches and mismatches between prosodic phrasing within a clause and the syntactic constituency of that clause (see amongst many others Kratzer and Selkirk 2007; Wagner 2010; Selkirk 2011; Elfner 2012; Cheng and Downing 2016), or (b) the question of whether assumed word-internal morphosyntactic phases can inform our understanding of the phonological processes within these words (see, e.g., Arad 2003; Newell 2008; Embick 2010; Newell and Piggott 2014; Fenger 2020). Crucially, however, since the word-internal phases are hard or even impossible to diagnose from a syntactic point of view (see discussion about applying standard syntactic phasehood tests to word-internal phases in Newell 2008, p16ff), a full investigation of the mapping across modules often remains incomplete. In our case, however, it does not.Footnote46 We argued that there is a strong correlation between the locality domains used for the word-internal application of umlaut and the locality domains used for the word-external (i.e., clausal) derivation responsible for the choice of negation. We are not aware of any other sources that provide a similar claim, and the prospect of finding more correlations of word-internal and word-external locality domains across modules strikes us as a fascinating area of research for the future.
Note that our findings can also be taken as a strong argument against recent attempts in the literature to do away with locality domains in the syntax alltogether and explain locality effects as intervention effects (see Keine and Zeijlstra 2025; Bešlin 2025). Under such an approach, the correlation between the syntactic choice of negation and the locality of umlaut would remain a complete coincidence. Note, however, that these approaches are concerned with syntactic locality domains diagnosed by their effects on movement paths while we look at the licensing of syntactic elements, which we model as an agreement relation. Crucially, this phenomenon does not lend itself to an approach in terms of intervention to begin with, as there is no plausible intervener that would tell us when embedded negation is licensed and when it is not. It is thus still an open question how accounts of this sort would deal with locality effects outside of movement paths.
Overall, our model explains the correlation between word-external and word-internal locality domains by bringing two previously independent strands of research together. We combine the above-mentioned research of the inheritance of locality domains across modules with the growing body of literature that claims that the syntactic notion of a phase is better understood as dynamic, in the sense that some syntactic processes can extend phases in the course of the derivation. In our case, we assume that the syntactic process of head-movement creates bigger locality domains, and, crucially, it does so not only for word-internal but also for phrasal locality domains.
5.2 Alternatives to deriving the verb class alternation
One of the analytical challenges we discussed above was the different behavior of the two verb classes in terms of whether they have a verbal class marker or not. Based on the discussion of umlaut, gemination, and diachronic evidence, we concluded with Geiger (1938), Letterman (1997) that class 1 has a class marker but class 2 does not. In Sect. 4.2.1, we then encountered the choice as to how to model the presence or absence of a verb class marker in the morphophonology. The solution we pursued was to have the syntax of both classes be identical, that is, both verb classes are syntactically identical in that they have a v-head, and only in the postsyntax does an obliteration rule cause them to be different for the purposes of the morphophonology.
The alternative, which was proposed by an anonymous reviewer, is to assume that the difference in morphophonological behavior stems from an underlying difference in the syntax. In other words, we could assume that class 2 is already syntactically less complex than class 1. Such analyses of morphophonological reflexes of noun or verb classes have been proposed in the recent literature as well. Most notably, Borer (2014) argues in detail that the majority of monomorphemic nouns and verbs in English actually do not require a categorizer to be able to appear in a syntactic structure. In a somewhat similar way, and building on the suggestion of the reviewer, we could say that verbs of class one require a v*-head to be integrated into the syntactic structure, but verbs of class 2 do not need to. Following Borer (2014), class 2 verbs will instead be categorized by whatever verbal affixes are heading them. Importantly, then, the property of a head as to whether it is a domain-delimiter (i.e., phase head) or not cannot follow from its category or the lexicon, but rather from the syntactic context. In such an approach, Asp would be a domain delimiter if it attaches to a bare root, but in other configurations it would not be.
The upside of this approach is that it allows us to treat the mapping of syntactic to phonological structure as uniformly isomorphic. Since, in such an approach, the aspectual projection will be part of the inner domain in the syntax already, it would not be surprising that it also is part of the inner domain for purposes of suppletion and umlaut.
The downside, at least from our perspective, is that (a) the absence of a categorizing head is at odds with the basic assumptions of the framework we adopt and (b), arguably more importantly, that we posit a syntactic difference between the verb classes that we, at this point, have no evidence for. Under such an approach, we would potentially expect extraction asymmetries between class 1 and class 2, or differences in what heads (like Caus or Pass) they can combine with. We have not found any such differences at this point, and therefore opted to treat them as syntactically identical and only morphologically different.
Nonetheless, we think that the purely syntactic approach to the verb class alternation would be feasible as well, and other than the absence of evidence in its favor, we have no arguments against it. Ultimately, we take this question to be a purely empirical one. The two solutions make different predictions as to whether we should be able to find genuine syntactic asymmetries between the two different verb classes. As noted above, we have not found any differences in extraction or syntactic compatibility, but maybe a more promising place to look would be in the relevant scope of certain affixes, including negation and causatives or perfect.Footnote47 In Sect. 4.4, we assumed that no-negation can attach to extended vPs. That could hypothetically entail a difference between the relevant position of no- with respect to other affixes, in the sense that the presence of v* allows for a lower adjunction site of no- than v*’s absence. This would become particularly relevant in combination with other scope-taking affixes, such as the causative, as it then might result in different readings with different verb classes. So, as illustrated below, class 1 could hypothetically allow for two adjunction sites for Neg, while in absence of v*, the one where Neg scopes below the causative should be absent.
- (94)
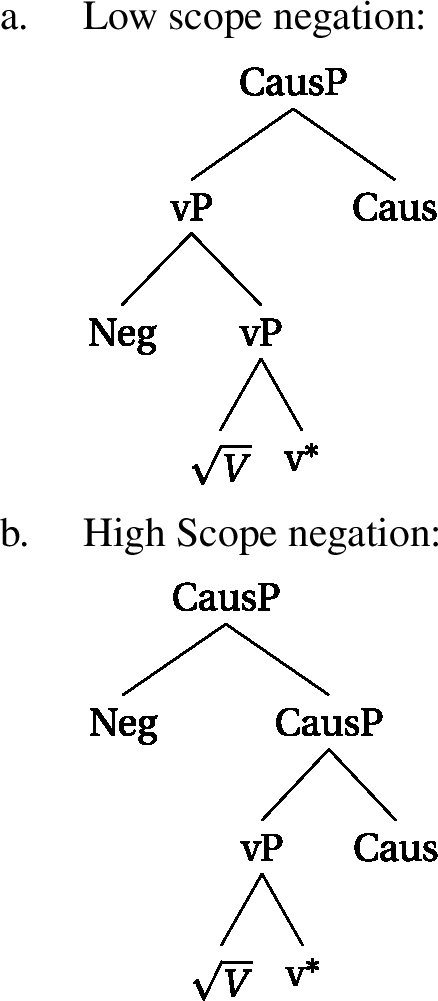
Thus, in principle we expect class 1 verbs to allow for two readings, ‘cause to not X’ and ‘not cause to X’, whereas class 2 verbs only allow for the latter, but this does not seem to be borne out. We have not found any differences in possible and impossible readings that would relate to verb class. De Abrew (1981) gives several examples indicating that high scope of no- is possible with verbs of both classes, but none that would indicate low scope. From the limited elicitations that we were able to do, it seems to us that high scope readings of negation (i.e., ‘not cause to X’) are preferred throughout, but we admit that these configurations should be tested further. In addition, we want to note that the whole issue could be obscured by whether the causative head has neg-raising properties or not.
In any case, if any genuine syntactic asymmetries between different verb classes could be found, then this would show quite clearly that the approach we pursue in Sect. 4.2.2, in terms of a morphological obliteration rule, is on the wrong track. This is, in our view, a fascinating research question for the future. But for the time being, we have decided, in the absence of evidence hinting at a tangible syntactic difference between the two verb classes, to go with a morphological solution.
6 Conclusion
In this paper, we offered an in-depth study of two seemingly unrelated phenomena in the insular Indo-Aryan language Sinhala. Both verbal stem umlaut in the language (and in particular, the underapplication of umlaut in certain contexts) as well as the use of embedded negation (and in particular, the overapplication of using embedded negation in certain matrix contexts) have puzzled researchers of Sinhala for quite a while. We offered two solutions to these long-standing problems, both of which made use of the concept of locality domains.
The crucial contribution of this paper does not lie, however, in the concrete implementation of these two phenomena, but rather in the observation that the locality domains in both domains are essentially isomorphic. Certain morphemes lose their ability to trigger umlaut when they are not root-adjacent, and it is exactly the same set of morphemes that allows for the use of embedded negation in matrix contexts. Thus, the respective locality domains extend across two logically independent dimensions: (i) On the one hand, we observe a correlation between locality domains in syntax and phonology, but (ii) on the other hand, there is also a correlation between word-internal processes and word-external processes. We argued that this was not a coincidence, and that we need a model of grammar that allows us to derive if and when locality domains across different areas of grammar are systematically related in the way we observed for Sinhala.
The model we proposed rests on two basic assumptions that we deduced out of the observations above. First, in order to derive the isomorphism between the locality domains between syntax and the phonology, we assume—in line with a fair amount of recent research couched in both the syntax-phonology interface and with work in Distributed Morphology—that the morphology and phonology inherit locality domains from the syntax. Secondly, in order to derive the correlation between word-internal and word-external domains, we followed the literature on phase-extension (see, e.g., den Dikken 2007 and others) in assuming that syntactic locality domains (i.e., phases) cannot be reduced to simple uniform category labels (such as vP and CP), but rather that the formation of phases is subject to syntactic operations. In particular, we made use of the idea that head-movement (a word formation process) also extends clausal phases. This allowed us to derive that locality domains relevant to the word-external phenomenon of negation mirrored those relevant for the word-internal phenomenon of umlaut.
As we hope to have shown in detail throughout this paper, we do not simply make the claim that locality domains across modules must be the same for conceptual reasons. We still do allow for a limited amount of mismatches between locality domains across modules. The one type of mismatch we discussed in detail was the fact that the absence of a class marker in one of the verb classes in Sinhala leads to slightly bigger locality domains as opposed to the other. In this spirit, we hope to help pave the way towards a model of the syntax-morphophonology mapping that is not simply black and white. Rather than saying that there are no mismatches or that mismatches are everywhere, we need a typology of possible and impossible mismatches in order to propose a coherent model.
We thus take the model we propose to be a very restrictive one. The hypotheses we eliminate can largely be grouped into two classes: First, we argue that there is an implicational relation between domains in different modules. We start our with lexically specified domains, and both the syntax and the morphology have limited power to increase these domains in certain ways. Importantly, once one module has increased the domain, all modules that follow will have to live with it. To give an example, we predict that if the verb has undergone head-movement all the way to C, thereby extending the domain, we do not expect to see smaller domains in the morphology or prosody. The opposite also holds: If we do not observe head-movement to a higher domain, we expect intermediate locality domains in the morphology and prosody. Secondly, we argue that there is a correlation between word-internal and word-external domains. This means that in the situation where the verb has undergone head-movement all the way to C, we do not expect to see any domain-effects inside of words in that configuration. In other words, if both are targeted by head-movement, T cannot behave like a level 1-affix, whereas C is a level 2 affix. We are aware that predictions of this sort are somewhat abstract and do require a fair amount of in-depth study of how certain elements behave in different modules, but we take this to be the only promising way forward if we want to understand better how different modules of grammar interact.
And in order to get there, we strongly advocate what one might call the holistic study of grammar. As we have seen, the syntactic choice of negation correlated with the word-internal applicability of a purely phonological process, namely umlaut. One of the main take-aways from this finding can be put as simple as this: Understanding the locality domains governing phonological processes can actually help us determine the workings of syntactic operations and vice versa. However, they can, of course, only do so when we look at all modules of grammar at the same time. If our model of phonological process X makes predictions for the syntax or the morphology (or the other way round), then we should actually go and test these predictions and not leave them unexplored.
Notes
-
Examples of works that follow this line of research are, among others, Marvin (2003), Arad (2003, 2005), Borer (2005), Marantz (2007), Newell (2008), Pak (2008), Ramchand (2008), Embick (2010), Newell and Piggott (2014), D’Alessandro and Scheer (2015), Crippen (2019), Fenger (2020), Sande et al. (2020), Guekguezian (2021). A different, seemingly opposing, approach is that of indirect mapping approaches, where an intermediate level between syntax and phonology is proposed: Kratzer and Selkirk (2007), Selkirk (2011), Cheng and Downing (2016), Bennett et al. (2016) amongst many others. However, following Bennett and Elfner (2019), we think the dichotomy is less clear-cut than generally believed. We elaborate on this in the discussion in Sect. 5.1.
-
We are aware that there is wide variation among vowel harmony systems, and, ultimately, it might be the case that some of them have the properties of the process we are describing here. Since the main focus of this paper is the domains of application of the process and not its concrete technical implementation, we remain agnostic as to whether umlaut and vowel harmony can, on some level of abstraction, be unified.
-
In the representations throughout this paper, we try to stay as close to the surface forms as possible, but we want to note that, of course, there are a lot of phonological processes going on that we cannot discuss in complete detail in the paper. One important process that needs mentioning is that short vowels in non-stressed, open syllables are frequently reduced to schwa (see Letterman 1997). The causative morpheme, for example, surfaces as /-wə-/ in (3), because it occurs in an open syllable, and all examples below, but underlyingly it is -wa- (Parawahera 1990; Letterman 1997). Similarly, the class marker often reduces to schwa in (3). For the discussion about the phonology of the class markers, the reader is also referred to Sect. 2.4.
-
We take the label progressive from Chandralal (2010), but we want to note that we sometimes find reduplication of verbs, including the perfect morpheme, which suggests that reduplication does not only express progressive actions but also repetetive events.
-
There is also a derogatory imperative in the language, which Chandralal (2010) translates as something like ‘Pull, you donkey!’ and which according to Chandralal (2010) behaves like the informal imperative with respect to its morphophonological properties, but our consultant was not comfortable using these forms in our presence, so we cannot make any claims about them.
-
Perfect and progressive are both expressed by means of auxiliary constructions, where tense and mood are realized on the copula.
-
As noted above in footnote 5, the underlying forms of some of these morphemes are notably more abstract. We believe the schwas in the causative, non-past, and the imperative to be underlyingly /a/. Letterman (1997) also argues at length that the allomorphy in the past tense can be attributed to a more abstract representation of the past tense affix, which she claims to be merely an empty mora. We would like to stay agnostic as to whether this is the correct analysis at this point.
-
Historically, at least the strong umlaut-triggers (see next subsection) seemed to contain an /i/. See the discussion in Geiger (1938) as well as Fritz (2002) for the closely related language Dhivehi. However, these authors also note that, synchronically, this generalization cannot be maintained.
-
An anonymous reviewer asks whether the causatives discussed here in this paper have properties of lexical causatives or not. This turns out to be a tricky question. The wa-causative alternates with a periphrastic causative construction using an auxiliary. However, the affixal wa-causative is not your typical lexical causative either, as it is extremely productive and can virtually attach to all verbs. Further, many of the typical properties associated with lexical causatives are usually accomplished with a change of verb class from class 1/2 to class 3, which we have put aside (see footnote 14 and the discussion in Beavers and Zubair 2012).
- (i)

- (i)
-
In what follows, we will just concentrate on the lexical verb and leave out the auxiliary in the perfect and the progressive.
-
What is usually referred to as the third class is a class that contains only intransitive verbs (including many verbs that also appear in classes 1 or 2 in a transitive version). The marker of this so-called class 3 is an /e/ and obligatorily triggers umlaut, which is why verbs of class 3 always come with a front vowel, and are therefore uninformative for our purposes. We want to note that the exponent of the so-called class marker in class 3 (/e/) is also the exponent of a passive marker, which we assume to not be a coincidence given that the class only contains intransitive verbs (see Beavers and Zubair (2012) for discussion).
-
Letterman discusses various forms of hiatus resolution in the language, and shows that in both the nominal and verbal domain there is a high vowel that can be epenthesized. Note that it is not uncommon to have high epenthetic vowels in Indo-Aryan languages (so-called svarabhakti-vowels) (see, e.g., Masica 1991; Jena 2006).
-
Maybe it is a bit unusual to assume that the empty mora will be realized as a vowel when it is next to a vowel, as this creates a marked phonotactic structure. We have the impression that the /u/ that is usually taken as the exponent of past tense in class 1 often also has more glide-like properties, as it then appears in between the class marker vowel and the verb-final indicative marker /a/. In that sense, what is transcribed as the past tense marker /u/ is a combination of the class marker schwa plus a back vowel glide. We leave this for future research.
-
Geiger calls the /i/ in class 2 a svarabhakti vowel, noting that (i) it was not present in older stages of the language, and (ii) given its vowel quality and its position in the verb, it would be expected to trigger umlaut at the stage when umlaut was still triggered by the phonological properties of the affix itself.
-
There are a number of verbs that only supplete for one of these features (either past tense or perfect), and of course, with some verbs it is also not entirely clear where productive and semi-productive phonological processes end and where suppletion begins. We will thus restrict ourselves to the two verbs here, as they strike us as uncontroversial examples of morphologically conditioned stem suppletion.
-
Cf the analysis of different umlaut patterns in Germanic in Embick and Shwayder (2017).
-
For overviews of and arguments for level-based or stratal accounts, including the discussion of dual-level affixes, see Giegerich (1999), Steriade (1999), Raffelsiefen (2004), Kiparsky (2005), Bermúdez-Otero (2018).
-
See, for example, the discussion in Marvin (2003), Newell (2008), Embick (2010), Newell and Piggott (2014), D’Alessandro and Scheer (2015), Fenger (2020), Harðarson (2021), Kalin and Weisser (2025).
-
Given the treatment of nææ as an auxiliary, it might be surprising that it does not show any verbal affixes, but we want to remark that there is a whole class of high auxiliaries, such as the modals puluwan ‘can’ or oonæ ‘should,’ which cannot be inflected at all. This class of uninflected high auxiliaries in Sinhala is sometimes also referred to as quasi-verbs (see, e.g., Gair 2003).
-
Our informant notes that examples of this sort are sometimes not perceived as ungrammatical, because they can be forced to receive an embedded interpretation with the matrix verb elided. So, according to our consultant, (49) can possibly receive an interpretation like ‘I think I didn’t go.’. We take this as additional evidence that the distribution of no- is really governed by embeddedness.
-
The contrast between bi-domainal structures for marked aspect configurations but mono-domainal structures for unmarked aspect configurations is not uncommon crosslinguistically. It has been argued for quite a number of languages that specific aspect configurations, such as perfect or progressive, involve traces of biclausality (see, e.g., Comrie 1978; Bybee et al. 1994; Laka 2006; Coon 2010).
-
According to our consultant, the negated forms with no- in (56a) and (56b) are perceived as a bit archaic, but there is still a clear contrast to ungrammatical examples, where a past or a non-past matrix verb is negated with no-.
-
It is not hard to imagine syntactic domain effects correlating with clausal prosody but not word-internal prosody. Similarly, it is not hard to imagine a word-internal process (such as affix order) correlating with a word-external process (such as binding, etc.).
-
In her treatment of simple clauses of Turkish, Newell (2008) uses head-movement for roots to be able to escape the spell-out domain. In this account, head-movement does not, per se, have the ability to extend the domains, but it may allow elements to escape the lower phase, leading to similar results word-internally. Crucially, in Newell’s account, we do not expect a correlation between clausal and word-internal locality domains like the one we have argued we observe in Sinhala.
-
The specific implementation is not important, but what is important is that (part of) the second domain is already present when the first domain is shipped off. An alternative implementation to the PIC2 would be to assume that once a head of a different domain is merged, the lower domain is closed off (Grohmann 2003; Wurmbrand 2017).
-
Of course, whether or not head movement precedes spell-out is debated, but there seems to be variation across languages; provided are arguments for spell-out before movement, or movement at a later stage, and whether languages can differ (Chomsky 2001; Schoorlemmer and Temmerman 2012; Platzack 2013; Kilbourn-Ceron et al. 2016; Harizanov and Gribanova 2019; Fenger 2020, a.o.).
-
See Manetta (2019) on Hindi, a related language, and Rosmin (2015) on Malayalam, a close relative of the immediate neighboring language Tamil, for an argument that the verb moves up all the way to C in this head-final language.
-
We specifically assume that if there is a phase head in a complex head, the material can be interpreted in the phonology. In cases where head movement applies before spell-out (in cases of simple tenses, for example), there will be only one phase word internally and externally. If this phase head is not present (see Sect. 4.2 and 4.3), the derivation for the word is halted, and higher material can potentially attach, creating syntax-morphology mismatches. Note that we do not assume that phase-heads send their complements to the interfaces, but we assume that the phase head is shipped off as well (Holmberg 1999; Fox and Pesetsky 2003; Marvin 2003; Svenonius 2004; Bošković 2014, a.o., and see also the distinction between complement-interpretation and total-interpretation phases in Newell (2008)).
-
An anonymous reviewer asks about our assumptions concerning the trigger for head-movement. Our impression is that virtually every theory involving head-movement needs to make some diacritic to determine which heads participate in head-movement and which ones do not. Most theories encode this as a feature referring to the status as a bound or a free morpheme (see, e.g., Rizzi and Roberts (1989), Brody (2000), Roberts (2010), Harizanov and Gribanova (2019)).
-
We assume this instance of cliticization happens before the head is spelled out, as an instance of morphological merger (Marantz 1988; Embick and Noyer 2001; Newell 2008; Georgieva et al. 2021). Depending on what is present in the lower domain, the complex head can already be phonologized, but, crucially, the category of the highest head remains (Shwayder 2015; Fenger 2020). See also the discussion in Sect. 4.5.2.
-
The analysis for Sinhala is in line with observations regarding the structure of imperatives in other languages. On the one hand, it has been argued that for some languages the verb stays low, on the basis of affixation and negation (see for example discussion on English or Italian, Rivero and Terzi 1995; Lasnik 1995; Kayne 2000; Zeijlstra 2006, a.o.). On the other hand, it has been argued that there might be a phasal boundary in imperatives, on the basis of the interaction of aspect, negation, and imperatives (Despić 2020).
-
It should be noted that the use of obliteration in order to remove unmarked heads for morphological purposes differs—to a certain extent—from the ones in Arregi and Nevins (2007, 2012), who use it for markedness-targeted or markedness-triggered deletion effects (see also Weisser (2024a) for discussion). Effects similar to the one here have also been discussed, under the notion of pruning (Embick 2010, see also the applications of pruning in Calabrese (2012, 2015), who applies it to deletion of Italian theme vowels in a way that bears some resemblance to the case at hand). Note, however, that unlike in our account, pruning applies subsequent to Vocabulary Insertion to heads that are phonologically zero (Embick 2010). We depart from this assumption mainly for the reason that the Embickian system is unequipped to deal with instances of morphosyntactically conditioned root suppletion. In Embick (2010), for example, root suppletion of a lexical verb root for morphosyntactic features is specifically excluded and alleged counterexamples (such as go-went-alternations) are assumed to be light verb constructions without a lexical verb. We, however, are convinced that the recent investigations of root suppletion have unearthed many unambiguous cases of root suppletion (Bobaljik 2012; Harley 2014; Bobaljik and Harley 2017; Choi and Harley 2019) that cannot plausibly be reduced to being instantiations of functional heads, and, accordingly, we have used morphosyntactically conditioned root suppletion as a morphological diagnostic in Sect. 2.5. Therefore, we resort to having the deletion rule refer to morphological markedness instead (similar to the operation in Fenger (2020)). We are aware of the fact that morphological markedness is also a somewhat controversial concept, and we hope that future work on markedness, especially in reference to categorizing heads and theme vowels, can shed some light onto the issue. We want to note, however, that a system like Embick’s (2010), which only refers to phonological overtness rather than morphological markedness, also needs to make additional stipulations: some heads that are phonologically zero need to remain in the structure and as Embick (2010) notes, it is so far unclear what ultimately conditions the (non-)application of pruning.
-
For a similar interpretation, see Fenger (2020), where it is assumed that when unmarked phase heads are removed in the complex head, there is exceptional integration of a head from a higher cycle.
-
This fits quite well with the observation that, in Sinhala, as in many other languages, phonology seems to be sensitive to whether a certain construction is a noun or a verb. This is shown in Letterman (1997), who argues at length that processes like epenthesis and umlaut have different properties depending on the category of the element in question. Other references making the same points include Myers (1997), Bobaljik (1997), Smith (1997), Letterman (1997), Smith (2001). See also Weisser (2024b), where it is also argued that, for the purposes of phonologically determined clitic placement in Sinhala and other languages, basic categorical distinctions (like noun vs verb) need to be accessible in the phonology.
-
Note that the class marker schwa in (77) is deleted to avoid vowel hiatus. Note also that we are not representing the /a/ in the indicative as underspecified here, which is a slight simplification. As will become clear in the derivations in Sect. 4.5, we assume that association of the [–back] with the /a/ in the indicative is counterfed by the late insertion of the indicative exponent. The indicative simply comes too late to be associated with the floating feature.
-
One might think that the correlation between the weak umlaut triggers and the choice for no- is a purely morphological one; as the correlation might look like no-, affixal negation, is used with weak-umlaut triggers and not strong triggers. Note, first of all, that strong triggers can take no-, but only when they occur in embedded environments. Secondly, what is important is not the status as affix or free standing element, but the syntactic environment in which the elements appear. We take it as a coincidence of the vocabulary item, since the language has multiple forms of negation, and it just happens to be no- in some cases. That is, the choice for no- must come from the syntax, as it is determined by the specific syntactic configuration.
-
As an anonymous reviewer observes, no- is not only outside of the scope of umlaut in examples like (78), but also does not intervene for suppletion in examples like (52a). And as the reviewer further observes, this might be due to the status of no as an adjunct. On the one hand, its status as an adjunct might mean that it has undergone cyclic phonology, and thus received a default [+back]-feature. On the other hand, its status as an adjunct may mean that it does not intervene for suppletion. Bobaljik (2012) provides the case study of Basque adjectival stem suppletion, where an adjoined morpheme (the diminutive –xe) does not block stem suppletion by an outer comparative head (see also the treatment of bracketing paradoxes in Newell 2008, 2021).
-
At this point, we simply take this to be a morpheme-specific linearization constraint. It is noticeable though that negation consistently shows up as a prefix, even in almost exclusively suffixing, head-final languages, such as Sinhala, or Mari (Georgieva et al. 2021), or even in English. Ultimately, this is probably to be connected to Horn’s (1989) Neg-first-principle, which is intended as a meta-principle of languages that is behind several syntactic and morphological phenomena, such as neg-raising or negative inversion.
-
We adopt this implementation of the requirement of no- to appear in non-root domains for the sake of explicitness, but we want to note that there are probably more elegant ways to capture the distinction between root domains and non-root domains (see a.o. Emonds 1970, 1976; Heycock 2006 as well as Aelbrecht et al. 2012 and papers therein). The literature contains a fair amount of discussion as to how root-contexts are featurally or structurally different and how that translates into the various phenomena restricted to root clauses/domains. We could probably adopt most of these approaches, as long as they allow us to negatively specify that no- can occur in non-root clauses.
-
See, amongst many others Bobaljik (2000), Paster (2006), Starke (2009), Embick (2010), Myler (2017), Kalin (2022), Weisser (2024b), Kalin and Weisser (2025).
-
Note that in the representations below we will abstract away from some of the phonological processes we discussed in Sect. 2, as they do not bear on deriving the generalization. The first process we do not discuss is reduction of short vowels in open syllables (e.g., /wa/ reduces to /wə/). We also abstract away from the representation of past tense, and whether it is in fact a more abstract underlying form, as discussed in Sect. 2.4.
-
We assume that the epenthetic vowel here is /i/ as well, but that another postcyclic rule of vowel reduction to schwa also applies in this case. We have abstracted away from this in this depiction.
-
We remain agnostic as to whether Asp is spelled out before it attaches, since there are also proposals that argue that this head can attach to phonological material, and there is some amount of interleaving of phonology and morphology (Shwayder 2015). Specifically in light of Asp being able to attach to a non-spelled out root, it is likely that Perf is not spelled out as well. What is crucial for the proposal here is that Perf does not have affix status, like tense has for example, and can therefore remain ‘stranded’ (i.e., does not require to attach to a non-spelled out root). The reason Perf can attach is because of the requirements of the root (see also fn. 33).
-
Some of the standard references for this kind of approach are provided (Kratzer and Selkirk 2007; Selkirk 2011; Elfner 2012; Cheng and Downing 2016; Bennett et al. 2016, a.o.).
-
References for this kind of approach include Arad (2003, 2005), Newell (2008), Pak (2008), Embick (2010), Newell and Piggott (2014), D’Alessandro and Scheer (2015).
-
Very recent approaches following the same line of argumentation include Fenger (2020), who compares the relation between phrasal domains and word-internal ones in Turkish and Japanese, and Borise and Georgieva (2023), who compare the locality domains of negated verbs in Udmurt with the morphosyntactic investigation of the same configurations in Georgieva et al. (2021). For a very recent contribution pursuing a very similar approach to the one at hand, see van Urk (2023), who compares the crossmodular locality domains of verbs and verbal constructions in Dinka.
-
We thank an anonymous reviewer for bringing up this question.
References
-
Abhayasinghe, A. A. 1973. A morphological study of Sinhalese, PhD thesis, University of York.
-
Aelbrecht, L., L. Haegeman, and R. Nye. 2012. Main clause phenomena and the privilege of the root 1–20. Amsterdam: Benjamins.
-
Arad, M. 2003. Locality conditions on the interpretation of roots. Natural Language & Linguistic Theory 21:737–787. https://doi.org/10.1023/A:1025533719905.
-
Arad, M. 2005. Roots and patterns: Hebrew morphosyntax. Berlin: Springer.
-
Aronoff, M. 1976. Word-formation in generative grammar. Linguistic inquiry monographs 1. Cambridge: MIT Press.
-
Arregi, K., and A. Nevins. 2007. Obliteration vs. impoverishment in the Basque g-/z- constraint. In Proceedings of the 26th Penn Linguistics Colloquium, eds. T. Scheffler, J. Tauberer, A. Eilam, and L. Mayol. Vol. 13.1, 1–14. Philadelphia: Penn Linguistics Club.
-
Arregi, K., and A. Nevins. 2012. Morphotactics. Basque auxiliaries and the structure of spellout. Berlin: Springer.
-
Beavers, J., and C. Zubair. 2012. Anticausatives in Sinhala: Involitivity and causer suppression. Natural Language and Linguistic Theory 31:1–46. https://doi.org/10.1007/s11049-012-9182-4.
-
Bennett, R., and E. Elfner. 2019. The syntax-prosody interface. Annual Review of Linguistics 5:151–171. https://doi.org/10.1146/annurev-linguistics-011718-012503.
-
Bennett, R., E. Elfner, and J. McCloskey. 2016. Lightest to the right: An apparently anomalous displacement in Irish. Linguistic Inquiry 47(2):169–234. https://doi.org/10.1162/LING_a_00209.
-
Bermúdez-Otero, R. 2018. Stratal phonology. In The Routledge handbook of phonological theory, eds. S. Hannahs and A. Bosch. https://doi.org/10.4324/9781315675428-5. Routledge.
-
Bešlin, M. 2025. Lexical Categories, (Re)categorization, and Locality in Morphosyntax. Doctoral diss., University of Maryland.
-
Bobaljik, J. 1997. Mostly predictable: Cyclicity and the distribution of schwa in Itelmen. In Proceedings of WECOL 1996, UC, Santa Cruz.
-
Bobaljik, J. D. 2000. The ins and outs of contextual allomorphy. In UMD working papers in linguistics, eds. K. K. Grohmann and C. Struijke. Vol. 10, 35–71. Maryland University.
-
Bobaljik, J. 2012. Universals in comparative morphology. Cambridge: MIT Press.
-
Bobaljik, J., and H. Harley. 2017. Suppletion is local: Evidence from Hiaki, the structure of words at the interfaces 141–159. London: Oxford University Press. https://doi.org/10.1093/oso/9780198778264.003.0007.
-
Bobaljik, J. D., and S. Wurmbrand. 2013. Suspension across domains. In Distributed Morphology Today: Morphemes for Morris Halle, eds. O. Matushansky and A. Marantz, 185–198. Cambridge: MIT Press.
-
Borer, H. 2005. Structuring sense. Oxford: Oxford University Press.
-
Borer, H. 2014. The category of roots. In The syntax of roots and the roots of syntax, eds. A. Alexiadou, H. Borer, and F. Schäfer, 112–148. London: Oxford University Press.
-
Borise, L., and E. Georgieva. 2023. The role of lowering and non-cyclic heads in Udmurt stress placement. In NELS 53: Proceedings of the fifty-third annual meeting of the North East linguistic society, eds. S. Y. Lam and S. Ozaki. Vol. 1, 105–118. Amherst: Graduate Linguistics Student Association.
-
Bošković, Željko. 2014. Now I’m a phase, now I’m not a phase. Linguistic Inquiry 45(1):27–89. https://doi.org/10.1162/LING_a_00148.
-
Brody, M. 2000. Mirror theory: Syntactic representation in perfect syntax. Linguistic Inquiry 31(1):29–56. https://doi.org/10.1162/002438900554280.
-
Bybee, J., R. Perkins, and W. Pagliuca. 1994. The evolution of grammar: Tense, aspect, and modality in the languages of the world. Chicago: University of Chicago Press.
-
Caha, P. 2009. The nanosyntax of case, PhD thesis, University of Tromso.
-
Calabrese, A. 2010. Investigations on markedness, syncretism and zero exponence in morphology. Morphology 21:283–325. https://doi.org/10.1007/s11525-010-9169-y.
-
Calabrese, A. 2012. Allomorphy in the Italian passato remoto: A Distributed Morphology analysis. Language and Information Society 18:1–75.
-
Calabrese, A. 2015. Irregular morphology and athematic verbs in Italo-Romance. Isogloss 1(3):69–102.
-
Chandralal, D. 2010. Sinhala. Vol. 15 of London oriental and African language library. Amsterdam: Benjamins.
-
Cheng, L. L. S., and L. J. Downing. 2016. Phasal syntax = cyclic phonology? Syntax 19(2):156–191. https://doi.org/10.1111/synt.12120.
-
Choi, J., and H. Harley. 2019. Locality domains and morphological rules: Phases, heads, node-sprouting and suppletion in Korean honorification. Natural Language and Linguistic Theory 37(4):1319–1365. https://doi.org/10.1007/s11049-018-09438-3.
-
Chomsky, N. 2001. Derivation by phase. In Ken Hale: A life in language, ed. M. Kenstowicz, 1–52. Cambridge: MIT Press. https://doi.org/10.7551/mitpress/4056.003.0004.
-
Chomsky, N. 2008. On phases. In Foundational issues in linguistic theory: Essays in honor of Jean-Roger Vergnaud, eds. R. Freidin, D. Michaels, C. P. Otero, and M. L. Zubizaretta, 133–166. Cambridge: MIT Press.
-
Comrie, B. 1978. Ergativity. In Syntactic typology: Studies in the phenomenology of language, ed. W. Lehmann, 329–394. Austin: University of Texas Press.
-
Coon, J. 2010. Complementation in Chol (Mayan): A theory of split ergativity, PhD thesis, MIT diss.
-
Crippen, J. 2019. The syntax in Tlingit verbs, PhD thesis, University of British Columbia.
-
D’Alessandro, R., and T. Scheer. 2015. Modular PIC. Linguistic Inquiry 46(4):593–624. https://doi.org/10.1162/LING_a_00195.
-
De Abrew, K. K. 1981. The Syntax and Semantics of Negation in Sinhala, PhD thesis, Cornell University.
-
de Silva, M. 1960. Verbal categories in spoken Sinhalese. University of Ceylon Review 18(1–2):96–112.
-
den Dikken, M. 2007. Phase extension: Contours of a theory of the role of head movement in phrasal extraction. Theoretical Morphology 33(1):1–41. https://doi.org/10.1515/TL.2007.001.
-
Despić, M. 2020. Negative imperatives and aspect: A phase-based approach. In Current developments in Slavic linguistics. Twenty years after, eds. P. Kosta and T. Radeva-Bork, 173–185. Potsdam Linguistic Investigations.
-
Elfner, E. 2012. Syntax-prosody interactions in Irish, PhD thesis, Unversity of Massachuesetts Amherst.
-
Elordieta, G. 2008. An overview of theories of the syntax-phonology interface. International Journal of Basque Linguistics and Philology 42:209–286.
-
Embick, D. 2010. Localism versus globalism in morphology and phonology. Cambridge: MIT Press.
-
Embick, D. 2021. The motivation for roots in Distributed Morphology. Annual Review of Linguistics 7:69–88. https://doi.org/10.1146/annurev-linguistics-040620-061341.
-
Embick, D., and A. Marantz. 2008. Architecture and blocking. Linguistic Inquiry 39(1):1–53. https://doi.org/10.1162/ling.2008.39.1.1.
-
Embick, D., and R. Noyer. 2001. Movement operations after syntax. Linguistic Inquiry 32:555–595. https://doi.org/10.1162/002438901753373005.
-
Embick, D., and K. Shwayder. 2017. Deriving morphophonological (mis)applications. In From sounds to structures: Beyond the Veil of Maya, eds. R. Petrosino, P. Cerrone, and H. V. D. Hulst. Berlin: de Gruyter.
-
Emonds, J. 1970. Root and Structure-preserving Transformations, PhD thesis, MIT.
-
Emonds, J. 1976. A transformational approach to English syntax. New York: Academic Press.
-
Fenger, P. 2020. Words within Words: The internal syntax of verbs, PhD thesis, University of Connecticut.
-
Foley, C., and J. W. Gair. 1993. The distribution of no- in Sinahala. Presentation at SALA, June 1993. Ms, Cornell University.
-
Fox, D., and D. Pesetsky. 2003. Cyclic linearisation and the typology of movement. Ms. MIT.
-
Fritz, S. 2002. The Dhivehi language. A descriptive and historical grammar of maldivian and its dialects. Würzburg: Ergon Verlag.
-
Gair, J. W. 1970. Colloquial Sinhalese clause structures. Berlin: de Gruyter.
-
Gair, J. W. 2003. Sinhala. In The Indo-Aryan languages, eds. G. Cardona and D. Jain. London: Routledge.
-
Gallego, A. J., and J. Uriagereka. 2007. Subextraction from subjects: A phase theory account. In Romance Linguistics 2006: Selected papers from the 26th Linguistic Symposium on Romance Languages (LSRL), eds. J. Camacho, N. Flores-Ferrán, L. Sánches, V. Deprez, and M. J. Cabrera, 155–168. Amsterdam: Benjamins.
-
Garland, J. 2005. Morphological typology and the complexity of nominal morphology. In Proceedings from the workshop on Sinhala linguistics, volume 17 of Santa Barbara papers in linguistics, eds. R. Englebretson and C. Genetti, 1–19.
-
Geiger, W. 1938. A Grammar of the Sinhalese Language. UK: Asian Educational Services, The Royal Asiatic Society.
-
Georgieva, E., M. Salzmann, and P. Weisser. 2021. Negative verb clusters in Mari and Udmurt and why they require postsyntactic top-down word-formation. Natural Language & Linguistic Theory 39(2):457–503. https://doi.org/10.1007/s11049-020-09484-w.
-
Giegerich, H. 1999. Lexical strata in English: Morphological causes, phonological effects. London: Oxford University Press.
-
Grohmann, K. K. 2003. Prolific domains: On the anti-locality of movement dependencies Linguistik aktuell. Amsterdam: Benjamins.
-
Guekguezian, P. A. 2021. Aspectual phase heads in Muskogee verbs. Natural Language and Linguistic Theory 39:1129–1172. https://doi.org/10.1007/s11049-020-09495-7.
-
Halle, M., and A. Marantz. 1993. Distributed Morphology and the pieces of inflection. In The view from building 20, eds. K. Hale and S. J. Keyser, 111–176. Cambridge: MIT Press.
-
Halpert, C. 2016. Argument licensing and agreement. Oxford: Oxford University Press.
-
Harðarson, G. R. 2021. On the domains of allomorphy, allosemy and morphophonology in compounds. Natural Language and Linguistic Theory 39:1173–1193. https://doi.org/10.1007/s11049-020-09499-3.
-
Harizanov, B., and V. Gribanova. 2019. Whither head movement? Natural Language and Linguistic Theory 37(2):461–522. https://doi.org/10.1007/s11049-018-9420-5.
-
Harley, H. 2005. How do verbs get their names? Denominal verbs, manner incorporation, and the ontology of verb roots in English. In The syntax of aspect, eds. N. Erteschik-Shir and T. R. Rappaport, 42–64. Oxford: Oxford University Press.
-
Harley, H. 2014. On the identity of roots. Theoretical Linguistics 40(3–4):225–276. https://doi.org/10.1515/tl-2014-0010.
-
Harley, H., and R. Noyer. 1999. Distributed Morphology: State-of-the-article. Glot International 4(4):3–9. https://doi.org/10.1515/9783110890952.463.
-
Heycock, C. 2006. Embedded root phenomena. In Blackwell companion to syntax II, eds. M. Everaert and H. van Riemsdijk. Oxford: Blackwell. https://doi.org/10.1002/9780470996591.ch23.
-
Holmberg, A. 1999. Yes and No in Finnish: Ellipsis and cyclic spell-out. MIT Working Papers in Linguistics 33.
-
Horn, L. R. 1989. A natural history of negation. Chicago: University of Chicago Press.
-
Jena, N. 2006. Svarabhakti. Bulletin of the Deccan College Post-Graduate Research Institute 66/67:403–408.
-
Kalin, L. 2022. Infixes really are (underlyingly) prefixes/suffixes: Evidence from allomorphy on the fine timing of infixation. Language 98(4):641–682.
-
Kalin, L., and P. Weisser. 2025. Minimalism and morphology. In Cambridge handbook of Minimalism, eds. K. Grohmann and E. Leivada. Cambridge: Cambridge University Press.
-
Kayne, R. 2000. Italian negative infinitival imperatives and clitic climbing. In Hommages à Nicolas Ruwet, eds. L. Tasmowski and A. Zribi-Hertz, Communication & cognition, 300–312.
-
Keine, S., and H. Zeijlstra. 2025. Clause-internal successive cyclicity: Phasality or dp intervention? Natural Language and Linguistic Theory https://doi.org/10.1007/s11049-024-09627-3.
-
Kilbourn-Ceron, O., H. Newell, M. Noonan, and L. Travis. 2016. Phase domains at PF. In Morphological metatheory, eds. D. Siddiqi and H. Harley, 121–161. Amsterdam: Benjamins. https://doi.org/10.1075/la.229.05kil.
-
Kiparsky, P. 2005. Paradigm Uniformity Constraints. Ms. Stanford University.
-
Kratzer, A., and E. Selkirk. 2007. Phase theory and prosodic spellout: The case of verbs. The Linguistic Review 24:93–135. https://doi.org/10.1515/TLR.2007.005.
-
Laka, I. 2006. Deriving split ergativity in the progressive: The case of Basque. In Ergativity: Emerging issues, eds. A. Johns, D. Massam, and J. Ndayiragije. Dordrecht: Springer.
-
Lasnik, H. 1995. Verbal morphology: Syntactic structures meets the minimalist program. In Evolution and revolution in linguistic theory: Essays in honor of Carlos Otero, eds. H. Campos and P. Kempchinsky, 251–275. Georgetown University Press.
-
Letterman, R. S. 1997. The effects of word-internal prosody in Sinhala: A constraint-based analysis, PhD thesis, Cornell University.
-
Lieber, R. 1992. Deconstructing morphology. Chigago. Chigago: University of Chigago Press.
-
Lodge, K. 1989. A nonsegmental account of German umlaut: Diachronic and synchronic perspectives. Linguistische Berichte 124:470–491.
-
Manetta, E. 2019. Verb phrase ellipsis and complex predicates in Hindi-Urdu. Natural Language and Linguistic Theory 37:915–953. https://doi.org/10.1007/s11049-018-9429-9.
-
Marantz, A. 1988. Clitics, morphological merger, and the mapping to phonological structure. In Theoretical morphology, eds. M. T. Hammond and M. P. Noonan, 253–270. San Diego: Academic Press.
-
Marantz, A. 1997. No escape from syntax: Don’t try morphological analysis in the privacy of your own lexicon. In University of Pennsylvania working papers in linguistics, eds. A. Dimitriadis, L. Siegel, C. Surek-Clark, and A. Williams. Vol. 4, 201–225.
-
Marantz, A. 2013. Locality domains for contextual allomorphy across the interfaces. In Distributed Morphology today, eds. O. Matushansky and A. Marantz, 95–117. Cambridge: MIT Press. https://doi.org/10.7551/mitpress/9780262019675.003.0006.
-
Marantz, A. 2007. Phases and words. In Phases in the theory of grammar, eds. S. H. Choe, et al.. Seoul: Dong-in Publishing Co.
-
Marvin, T. 2003. Topics in the Stress and Syntax of Words, PhD thesis, Massachusetts Institute of Technology.
-
Masica, C. 1991. The Indo-Aryan languages. Cambridge: Cambridge University Press.
-
Mohanan, K. 1986. The theory of lexical phonology, Dordrecht, Foris.
-
Myers, S. 1997. OCP effects in optimality theory. Natural Language & Linguistic Theory 15(4):847–892. https://doi.org/10.1002/9780470756171.ch13.
-
Myler, N. 2017. Exceptions to the mirror principle and morphophonological ‘action at a distance’. In The structure of words at the interfaces, eds. H. Newell, M. Noonan, G. Piggott, and L. d. Travis, 100–125. Oxford: Oxford University Press. https://doi.org/10.1093/oso/9780198778264.003.0005.
-
Nespor, I., and I. Vogel. 1986. Prosodic phonology, Dordrecht, Foris.
-
Newell, H. 2008. Aspects of the morphology and phonology of phases, PhD thesis, McGill University.
-
Newell, H. 2021. Bracketing paradoxes resolved. The Linguistic Review 38(3):443–482. https://doi.org/10.1515/tlr-2021-2072.
-
Newell, H., and G. Piggott. 2014. Interactions at the syntax-phonology interface: Evidence from Ojibwe. Lingua 150(332–362):332–362. https://doi.org/10.1016/j.lingua.2014.07.020.
-
Pak, M. 2008. The postsyntactic derivation and its phonological reflexes, PhD thesis, University of Pennsylvania, Philadelphia.
-
Parawahera, N. P. 1990. Phonology and Morphology of Modern Sinhala, PhD thesis, University of Victoria.
-
Paster, M. 2006. Phonological conditions on affixation, PhD thesis, University of California, Berkeley.
-
Pescarini, D. 2010. Elsewhere in romance: Evidence from clitic clusters. Linguistic Inquiry 41:427–444.
-
Platzack, C. 2013. Head movement as a phonological operation. In Diagnosing syntax, eds. L. L. S. Cheng and N. Corver, 21–43. London: Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199602490.003.0002.
-
Rackowski, A., and N. Richards. 2005. Phase edge and extraction: A Tagalog case study. Linguistic Inquiry 36:565–599. https://doi.org/10.1162/002438905774464368.
-
Raffelsiefen, R. 2004. Absolute ill-formedness and other morphophonological effects. Phonology 21:91–142. https://doi.org/10.1017/s0952675704000144.
-
Ramchand, G. 2008. Verb meaning and the lexicon: A first phase syntax. Cambridge: Cambridge University Press.
-
Rivero, M. L., and A. Terzi. 1995. Imperatives, V-movement, and logical mood. Journal of Linguistics 31:301–332. https://doi.org/10.1017/s0022226700015620.
-
Rizzi, L., and I. Roberts. 1989. Complex inversion in French. Probus 1:1–30. https://doi.org/10.4324/9781315310572-9.
-
Roberts, I. 2010. Agreement and head movement. Clitics, incorporation, and defective goals. Number 59 in linguistic inquiry monographs. Cambridge: MIT Press.
-
Rosmin, M. 2015. Head movement in syntax. Amsterdam: Benjamins.
-
Sande, H., P. Jenks, and S. Inkelas. 2020. Cophonologies by ph(r)ase. Natural Language and Linguistic Theory 38:1211–1261. https://doi.org/10.1007/s11049-020-09467-x.
-
Schoorlemmer, E., and T. Temmerman. 2012. Head movement as a PF-phenomenon: Evidence from identity under ellipsis. In West coast conference on formal linguistics 29, eds. J. Choi, E. A. Hogue, J. Punsky, D. Tat, J. Schertz, and A. Trueman, 232–240. Somerville: Cascadilla Press.
-
Selkirk, E. 1982. The syntax of words. Vol. 7 of Linguistic inquiry monographs. Cambridge: MIT Press.
-
Selkirk, E. 2011. The syntax-phonology interface, 2nd edn. In The handbook of phonological theory, eds. J. Goldsmith, J. Riggle, and A. Yu, 435–484. Oxford: Blackwell. https://doi.org/10.1002/9781444343069.
-
Shwayder, K. 2015. Words and Subwords: Phonology in a Piece-Based Syntactic Morphology, PhD thesis, University of Pennsylvania.
-
Slomanson, P. 2008. The perfect construction and complexity drift in Sri Lankan Malay. Lingua 18:1640–1655. https://doi.org/10.1016/j.lingua.2007.08.009.
-
Smith, J. 1997. Noun faithfulness: On the privileged behavior of nouns in phonology. Ms. University of North Carolina.
-
Smith, J. 2001. Lexical category and phonological contrast. In PETL 6: Proceedings of the workshop on the lexicon in phonetics and phonology, eds. R. Kirchner, J. Pater, and W. Wikely. Edmonton: University of Alberta.
-
Starke, M. 2009. Nanosyntax: A short primer to a new approach to language. Nordlyd 36:1–6.
-
Steriade, D. 1999. Lexical conservatism in French adjectival liaison. In Formal perspectives on Romance linguistics, eds. J. M. Authier, B. E. Bullock, and L. Reid, 243–270. Amsterdam: Benjamins.
-
Svenonius, P. 2004. On the edge. In Syntactic edges and their effects, eds. D. Adger, C. de Cat, and G. Tsoulas, 261–287. Dordrecht: Kluwer Academic. https://doi.org/10.1007/1-4020-1910-6_11.
-
Trommer, J. 2021. The subsegmental structure of German plural allomorphy. Natural Language and Linguistic Theory 39:601–656. https://doi.org/10.1007/s11049-020-09479-7.
-
van Urk, C. 2023. The nonconcatenative domain in western nilotic verbs. Presentation at the workshop on verbal domains, June 2023. Newcastle, UK.
-
van Urk, C., and N. Richards. 2015. Two components of long-distance extraction: Successive cyclicity in dinka. Linguistic Inquiry 46:113–155. https://doi.org/10.1162/LING_a_00177.
-
Wagner, M. 2010. Prosody and recursion in coordinate structures and beyond. Natural Language and Linguistic Theory 28:183–237. https://doi.org/10.1007/s11049-009-9086-0.
-
Weisser, P. 2024a. Markedness. In The Cambridge handbook of Distributed Morphology, eds. A. Marantz, I. Oltra-Massuet, R. Kramer, and A. Alexiadou. Cambridge: Cambridge University Press.
-
Weisser, P. 2024b. A Typolog of Shifting Coordinators and what they can tell us about clitics and their formal modelling, Habilitation thesis, University of Leipzig, Leipzig.
-
Wiese, R. 1996. Phonological vs. morphological rules: On German umlaut and ablaut. Journal of Linguistics 32:113–135. https://doi.org/10.1017/s0022226700000785.
-
Wurmbrand, S. 2017. Stripping and topless complements. Linguistic Inquiry 48(2):341–366. https://doi.org/10.1162/LING_a_00245.
-
Yu, S. T. 1992. Unterspezifikation in der Phonologie des Deutschen, Tübingen: Niemeyer.
-
Zeijlstra, H. 2006. The ban on true negative imperatives. Empirical Issues in Formal Syntax and Semantics 6:405–425.
Acknowledgements
First and foremost, we want to thank Dilini Kolombage for sharing her language, her judgments, and her patience when questioned about countless minimally different examples. We thank our handling editor Vera Gribanova for taking up the hard task of guiding our paper to publication as well as five anonymous reviewers for their constructive comments. We also want to thank the audiences of GLOW 45 (Queen Mary University, London), (F)ASAL 12 (University of Utah), NELS 53 (University of Göttingen), LingLunch (University of Connecticut, Fall 2021), Frankfurt Syntax Colloquium (Spring 2022), FoRiM (Harvard University, Fall 2023), as well as Jonathan Bobaljik, Andrea Calabrese, Penelope Daniel, Laura Kalin, Nik Rolle, Jochen Trommer and Coppe van Urk for helpful questions, comments, and discussions. This research was funded in part by the DFG grant WE 6913/1-1 (PI: Philipp Weisser).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Ethics declarations
Competing Interests
The authors declare no competing interests
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and permissions
About this article
Cite this article
Fenger, P., Weisser, P. Matching domains: The syntax, morphology, and phonology of the verb in Sinhala. Nat Lang Linguist Theory (2025). https://doi.org/10.1007/s11049-025-09667-3
- Received
- Accepted
- Published
- DOI https://doi.org/10.1007/s11049-025-09667-3
Keywords
- Locality domains
- Verbs
- Syntax-morphophonology interface
- Umlaut
- Negation
- Sinhala