Article Content
Abstract
This paper builds a spatial model of trade with supply-chain links to examine the effect of economic links and anti-COVID policies on the spread of the COVID-19 pandemic during the first wave across NUTS2 regions of the European Union (EU) and the UK. We find that the effort to reduce infection rates was more successful in the UK than in the EU, and that the deaths due to the trade vector were 10% on average across Europe. Our results imply that without the policy response in Europe, the number of deaths during the first wave would have been about 4,520,000 higher in the EU and around 1,240,000 greater in the UK, with significant variations across regions. Oberbayern in Germany and South Yorkshire in the UK appear as the most effective in reducing the death burden of COVID-19 at different points during the first wave. Moreover, 42% and 37% of the total deaths in the UK and the EU, respectively, could have been prevented if the policy implemented in these two regions had prevailed throughout Europe.
Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.
- Economic Geography
- European Politics
- European Economic Law
- European Economics
- Regional Geography
- European Economic Integration
1 Introduction
The COVID-19 pandemic ended 4.55 million lives (as of October 1, 2021), forced quarantines all over the world, stopped global value chains for a significant amount of time, and created one of the largest global recessions in recent years. However, as with the spread of other infectious diseases, its impact in terms of lives and economic activity varied greatly across regions and industries (see, e.g., Villani et al. (2020) and de Vet et al. (2021)). In this paper, we build on the idea that diffusion of infectious diseases depends on human interactions (e.g., see Fogli and Veldkamp (2021)), and in particular, on how dense is the economic network of a given area. We consider endogenously determined economic interactions and analyze the effect of the policies adopted to fight the first wave of the pandemic across different regions in the United Kingdom (UK) and the European Union (EU). More specifically, the paper asks the following questions. What is the contribution of economic linkages to the expansion of the disease? How many lives have the polices implemented saved?
The model we develop embeds a spatial economic model in the spirit of Allen and Arkolakis (2014), Caliendo and Parro (2015), and Caliendo et al. (2017) into the canonical susceptible, infected, and recovered (SIR) model by Kermack et al. (1927). The purpose of the proposed framework is to analyze the two-way causation between the spatial dynamics of an epidemic and the spatial distribution of economic activity. More specifically, the setup incorporates Ricardian trade á la Eaton and Kortum (2002), and extends the SIR model in two ways. First, similar to Fernández-Villaverde and Jones (2022), we consider five population groups composed of susceptible, vaccinated, infected, resolving, and recovered individuals, and also account for deaths. Second, we allow for spatial connections that are endogenously determined by the structure of our economic geography model. The assumption is that when regions trade, people enter in contact with one another so they put themselves at risk of getting infected or that the virus is itself transported through the imported goods. As a result of the economic geography model, denser regions will experience more rapid increase in infections for two reasons. First, within the region, there are more interactions across individuals and thus, a higher probability of transmission. Second, the larger a region is, the more it will trade with other regions, and thus, the higher the probability of transmitting the disease across regions.
In our framework, the economy is composed of a set of locations that produce goods in different sectors. Each sector produces three goods: a final product, an intermediate good, and a composite intermediate or material. The first two can be traded but trade is costly. The third one is only sold domestically within the region. In addition, following Caliendo and Parro (2015), whereas the domestic movement of materials is inter-industry, cross-regional trade of intermediate goods is purely intra-industry.Footnote1 This feature captures that the latter type of trade represents the largest component of the trade flows of intermediates. For example, World Bank (2009) finds that, from 1962 to 2006, worldwide intra-industry trade in intermediate goods increased approximately from to of total trade. This share equals in our European Union 28-country group (EU28) dataset, which include the current European Union plus the UK for the year 2013. What is most important is that these inter- and intra-industry links across sectors mean that policies and changes that affect a given industry can potentially affect all other sectors and regions. Our main contribution is to assess how the heterogeneity in production structures and regional connections affect the spread of the disease and its economic impact.
The model proceeds in two phases. For the population composition in a given day, the first phase obtains the distribution of economic activity and bilateral trade shares. In the second phase, we take as given the bilateral trade shares and the spatial distribution of economic activity along with the disease ecology to determine how the population composition changes from one day to the next. This creates a loop in which disease dynamics and economic activity affect each other. In particular, disease prevalence can reduce the labor force in a region through either mortality, morbidity or policy actions. These shocks affect the level of economic activity and reduce international trade. The modification of the trade patterns, in turn, has an impact on the spread of the disease by decreasing the amount of infection “exported” to other regions. These general equilibrium forces resemble a behavioral response in which agents protect themselves from the infection.
The explicit modeling of the geography is important to understand the disease dynamics.Footnote2 In general, those regions that are more isolated will receive and transmit less the infection. As an example, take the evolution of the pandemic in Spain versus Italy and the UK. The spread of the infection in Spain was faster in Madrid (a region in the center of the country) and then expanded throughout the nation. In Italy, the infection started in the north and then moved slowly toward the south. In the UK, in turn, the disease was more concentrated in the south but, at the same time, more widespread than in other parts of Europe. Our model addresses these singularities through the explicit modeling of the geography of trade in Europe.
We calibrate the model to match the distribution of workers and wages across 230 regions from 28 countries in Europe for 10 sectors of production comprising the whole economy and use our framework to assess through a set of counterfactuals, how policies adopted during the coronavirus pandemic, which include social distancing and regional lockdowns, have affected the impact of the disease. We focus on the first wave that goes from February 25 to July 15, 2020. For each of these regions, we use data on fatalities by COVID-19 to back out an estimate of the infection rate using the structure of the model. Essentially, this estimated infection rate is a residual that makes sure the model can track the evolution of the disease for each region, which is the same approach as the one followed by Fernández-Villaverde and Jones (2022) at a country level. We interpret changes in this infection rate as policies against COVID-19 and validate this interpretation in Sect. 6.1 by relating our recovered infection rate on several indices that track government responses against COVID-19. We find a strong relationship with containment and health-related policies, and for the government response index. These results suggest that our recovered infection rate in fact reflects anti-COVID policy responses.
The data indicates that despite a higher incidence of the disease in the UK compared to the European Union, the fight to reduce the infection rates was more successful in the UK than in the European Union. Our assessment reveals that the trade vector contributed to of the fatalities caused by COVID-19. We also conduct policy counterfactuals, where policy interventions are captured by a residual-like parameter. We simulate two types of scenarios. In the first one, policy responses are shut down over time in different geographical areas. In the second type, we allow all regions to enjoy the disease-transmission probabilities of the most successful areas regarding COVID-19 containment.
The results imply that without the policy reaction in Europe, the number of deaths during the first wave of the pandemic would have been about 4,520,000 larger in the European Union and about 1,240,000 higher in the UK, with significant variation across regions. Comparing the effects of the policies implemented in the EU27 and in the UK, we estimate that in the absence of European Union’s anti-COVID measures, the number of deaths in the UK would have been an 83% higher, equivalent to an additional 36 deaths per 100,000 inhabitants. Conversely, the UK’s anti-COVID measures saved 51,706 lives in the European Union and about 1,200,188 lives in the UK.
Our calculations indicate that the policies implemented by the region of Oberbayern in Germany were the most effective in reducing the death burden of COVID-19 across Europe during the first two months (or 61 days) after the onset of the disease. Subsequently, South Yorkshire in the UK was the area that managed to maintain control over the infection more effectively. Utilizing the daily decrease in transmission probabilities implied by the combination of these two areas, we find that 12,752 and 38,883 lives, amounting to 42% and 37% of the total deaths, could have been saved in the UK and the European Union, respectively, if the disease ecology and policy implemented in the two aforementioned regions had prevailed throughout Europe.
The paper proceeds as follows. Section 2 describes the related literature. Section 3 provides evidence in support of the mechanisms highlighted by our model. Section 4 introduces the model. The calibration of its exogenous variables and parameters is discussed in Sect. 5. Section 6 presents the results. Section 7 concludes.
2 Related literature
Our paper contributes to a large and growing literature on the link between economic activity and infectious diseases.Footnote3 We contribute by constructing and calibrating a model that features a set of European regions at different stages of development and assesses the importance of trade on the spread of the COVID-19 pandemic. In this model, trade serves as a vector of disease transmission through the transportation of goods and people.
It is well documented that goods transportation across regions can help spread infectious diseases.Footnote4 In the context of the HIV infection in Africa, Oster (2012) shows that the movement of truckers engaged in exports leads to a significant increase in new infections. Specifically, she estimates that doubling exports increases HIV infections by 10–70% through truckers. In a similar vein, Bajunirwe et al. (2020) analyze the spread of COVID-19 in Uganda through trucks drivers. They find that the very first cases arrived through international arrivals from Asia and Europe. However, by 29 April, out of the total amount of travellers with a tested confirmed case, were long-distance trucks drivers, while only were international arrivals. Furthermore, the majority of community cases were associated with contact with truck drivers. Similarly, Martini et al. (2022) find that the infection was significantly common among truck drivers in Uganda, Kenya, Rwanda, and South Sudan.
In a Latin American context, Calatayud et al. (2022) focus on the spread of COVID-19 in Colombia through the trucking network. They demonstrate that the number of confirmed COVID-19 cases in a municipality is positively linked to its level of trucking network centrality. Bernardes-Souza et al. (2021) perform a household survey and a case–control study in two towns in Brazil between May and June 2020, and find that logistics workers were the main source of COVID-19 contagion among households.
In Asia and Europe, similar patterns emerge. For example, Lan et al. (2020) study the progression of COVID-19 in Hong Kong, Japan, Singapore, Taiwan, Thailand, and Vietnam during the first 40 days after the initial locally transmitted case. They discard all imported cases to identify the occupation groups with most work-related cases. They find healthcare workers and driver and transport workers to be the two main occupations affected by work-related cases. Adda (2016) provides evidence, based on microdata, that the expansion of transportation networks and inter-regional trade had a significant impact on virus spreading in France. Focusing on France, Italy, and Spain, Bontempi et al. (2021) find that there is a strong statistical relationship between international trade intensity and severity of the COVID-19 pandemic across their regions.
Human mobility, in general, and tourism, in particular, emerge as significant vectors of COVID-19 transmission. Iacus et al. (2020) use variation in mobility restrictions across countries of the European Union and find that Human mobility alone explains of France and Italy initial spread of COVID-19. Farzanegan et al. (2021) analyze the relationship between the COVID-19 spread and international tourism across countries. They find that, up until April 30, 2020, those countries receiving larger inflows of international tourists experienced a higher level of confirmed COVID-19 cases and deaths even when normalizing these COVID-19 outcomes by the country’s population. Domestic tourism acted as well as a vector of the COVID-19 virus spread. For instance, Robin Nunkoo and Gholipour (2022) find that countries with a higher level of domestic travel related to tourism experienced higher levels of cases and deaths during the first six months of the pandemic.
Based on the empirical evidence above and the one we provide in Sect. 3, we argue that trade and tourism, when people mobility was not restricted, are important vectors of COVID-19 transmission. Therefore, our paper offers an alternative, complementary channel to the business travel one proposed by Antràs et al. (2023). Antràs et al. (2023) construct a two-country framework of human interactions through business travel, combining a gravity equation structure and an epidemiological model of disease evolution. In their model, the disease spreads as agents travel between countries. We depart from them by building a multi-country and multi-sector setup with an input–output structure rich enough to capture the transmission of the disease through bilateral trade across all network nodes. Furthermore, a crucial ingredient in our model is that it incorporates a time-variant local infection rate that tracks local policies against COVID-19. Then, our simulations are able to compare the effectiveness of regional policies at the NUTS2 level against COVID in the UK and the EU.
We are not the first in introducing spatial connections in epidemiological models. Lloyd and May (1996) and Keeling (1999) are early examples of spatial models of epidemics. Paeng and Lee (2017) extend the canonical SIR model by including spatial infections assuming that the infection can be spread in a given radius. In the epidemiological literature, the connection between trade and the spread of infectious diseases is also known, and Mayer (2000) notes that vectors of transmission of dengue fever or cholera were introduced in the USA through imported tires and through dumping bilge water into the ocean. We depart from this literature by endogenizing the spatial connections within a quantitative economic geography model, instead of assuming a given radius of infection or stochastic encounters.
Spatial frameworks in which the spread of the disease can occur through the movement of goods and people are also considered by Cuñat and Zymek (2022) and Giannone et al. (2022). Cuñat and Zymek (2022) combine a simple epidemiological framework with a dynamic model of individual location choice to study the impact of quarantines and other mobility restrictions on the spread of COVID-19 in the UK. In turn, Giannone et al. (2022) studies optimal containment policies in an economy with connected regions focusing on the USA. Unlike them, we consider a richer model of Ricardian trade and take advantage of a data set on sectoral bilateral trade flows between European Regions, the Rhomolo-MRIO Tables for 2013 published by the European commission (Thiessen 2020).
Other recent papers have studied the role of specific policies. For example, focusing on optimal lockdown policies, Acemoglu et al. (2021) emphasize differences across population groups, Alvarez et al. (2021) discuss the intensity and duration of the policy, and Glover et al. (2023) analyze the distributional consequences of policies that shut down sectors. More closely to our context, Fajgelbaum et al. (2021) find that regional-specific lockdowns result in better outcomes than uniform lockdowns. We depart from them by analyzing the policy effects at a higher regional level. We also depart from them by considering a compounded policy measure that captures broader policies against COVID-19.Footnote5
Our article also talks to another branch of recent papers focused on consumer behavior and output responses when faced with an infectious disease. Reductions in production during COVID have been explained with lockdowns (Bonadio et al. 2021; Sforza and Steininger 2020), supply shocks (Eppinger et al. 2021; Guerrieri et al. 2022; Kejžar et al. 2022), short-term demand reductions (Krueger et al. 2022; Eichenbaum et al. 2021; Liu et al. 2022), or risk aversion of forward-looking producers (Baker et al. 2020), to mention a few. Crucially, we depart from them by looking at the effects on the spread of COVID-19 within a multiple-region setting and a rich input–output structure.
Finally, Çakmaklı et al. (2021) study how demand and supply shocks affect global vaccinations and how vaccinations of other countries can potentially benefit home countries. They do not include, however, endogenous links for the spread of the infection. We also extend the methodology by Fernández-Villaverde and Jones (2022) to recover infection rates based on future deaths and use it to calibrate our model with endogenous links in the disease.
3 Empirical motivation
Trade, as a vector of COVID-19 transmission through the transportation of goods and tourism, is a key mechanism in our paper. While the movement of people was restricted in many countries during the first wave of the pandemic, freight transportation was never entirely halted. In contrast, tourism was among the most affected sectors, facing severe disruptions due to travel restrictions, lockdowns, and public health protocols. However, these restrictions were not implemented uniformly across time or nations, a factor our analysis will consider. For example, United Kingdom did not impose restrictions to international traveling until June 8, and Latvia never imposed restrictions to the internal movement of people. Consequently, both freight transportation and tourism may have contributed to the spread of COVID-19 in different ways, depending on the specific circumstances in each location and period.
To provide additional empirical support for this mechanism, we assess whether there is a relationship between deaths by COVID-19 and past tourist visits. In particular, we use variation across the regions in our analysis (see Table 1) to explore this relationship. We use data on arrivals at tourist accommodation establishments by NUTS2 regions from Eurostat and the compiled data on deaths by COVID-19 from different sources (see Table 5).
Specifically, we regress the log of cumulative deaths by COVID-19 up to July 15, 2020, on the log of tourist arrivals in 2020 controlling for the log of population density, that is, we estimate
where is the cumulative number of deaths by COVID-19 in region g of country c, is the population density in region g of country c, is the number of tourists in region g of country c (total, domestic, or foreign), is a country fixed effect, and is the error term.
We estimate Eq. (1) by OLS and find that tourist arrivals are positively associated with more deaths by COVID-19 (i.e., ), and this relationship is statistically significant. Panel A in Table 2 presents these results. Although this is purely correlational suggestion, it could be the case that there could be a negative reverse causality bias (i.e., more deaths in a region reduce the number of visits). To mitigate that we estimate the same regression (1) instrumenting by the log of number of tourists in 2018 and 2019. The estimated coefficients for the three tourism variables are positive and economically and statistically significant, thus reinforcing our proposed mechanism. Panel B of Table 2 presents the IV estimates. These are slightly larger than the OLS estimates suggesting that the negative reverse causality bias was there.
To further explore this mechanism, we also regress the log of cumulative deaths on a dummy variable that takes value equal to 1 if the region is in the upper quartile (75th percentile) of the arrivals distribution in the years 2020, 2019, and 2018, and we also distinguish between domestic, foreign, and total arrivals. The results are provided in Table 3. As before, the coefficients are positive and statistically significant reinforcing the evidence of this mechanism.
4 The model
We assume the economy is composed of a set of G geographical locations or regions that belong to different countries and J sectors or industries. Regions are denoted by g, i and h and sectors by j and k. In each industry, there is production of a composite intermediate or material, an array of different varieties of intermediate goods, and a set of different types of final consumption goods. Households provide labor to the production process. Labor is mobile across sectors and immobile across locations. All markets are perfectly competitive.
The model offers a rich supply-chain structure. Local materials from different sectors are employed along with the labor input to produce intermediate goods. In the next stage, intermediate goods produced by the same industry possibly in different locations are combined to generate final consumption products and a composite intermediate or material. These connections among the different stages of the production chain can provide amplification effects of trade disruptions.
We assume that the intermediate goods and final products can be tradable or not, whereas materials are not tradable. We consider that final consumption products can cross-regional borders, because some of them, like tourism, can be important for the propagation of the virus and are tradable. Trade in intermediate goods is intra-industry, which represents the largest component of the world trade flows of intermediates.
Let us now move to describing the model demographics. For simplicity, we omit time subscripts. The size of the population in region g equals . This population is composed of five groups: susceptible vaccinated and susceptible non-vaccinated people—denoted by and , respectively—who are not infected but can develop the disease; infected individuals, ; resolving cases who can pass away with probability or recover with probability Footnote6; and recovered, who can potentially get reinfected. Hence, it must be satisfied that
We will consider the possibility that recovered and vaccinated individuals may rejoin the susceptible non-vaccinated population once the partial immunity acquired by being exposed to the virus or the vaccine is lost.
Only a fraction from each group H can supply labor services. This fraction will be taken as exogenous, given by morbidity and policy considerations. Then, the available labor force equals:
With these ingredients, the model is numerically solved through a loop that consists of two phases, with each period corresponding to one day. In the first phase, for the population composition in a given day, we obtain the spatial distribution of economic activity. The second phase takes as given the spatial distribution delivered by the first phase, along with the disease ecology to determine how the population composition changes from one day to the next. We consider that the infection can spread within and across locations because of people contact. Finally, the new population composition feeds again the first phase, and this loop continues until predictions for the desired number of days are generated.
4.1 Phase 1: economic allocations across space
The first phase of the model determines the underlying economic geography through which the virus and the economic consequences of policies will potentially spread.
4.1.1 Households
Welfare-maximizing consumers in each location have identical preferences given byFootnote7:
where
the parameter represents the share of sector-j products in total consumption expenditure in location g, that is, ; the variable denotes the units consumed in location g of variety from sector-j ( is one among a mass of size one of different varieties); and the parameter gives the elasticity of substitution between different varieties of sector-j consumption products.
In each location, the population size is divided between workers and non-workers . Each of the two consumer types has, in principle, a distinct budget constraint, because income may differ depending on whether they work or not. However, we assume that workers pay lump-sum unemployment insurance () at the location where they provide labor services, and these taxes are fully redistributed as unemployment benefits () to the non-working individuals at the local level, that is, . Furthermore, this redistribution is such that their incomes are equalized, , where is the wage rate, which implies that , and thus, . That is, if there are more individuals unemployed, income per capita falls, and the opposite occurs if more people work. We also consider that consumers may pay lump-sum taxes that are directed to provide subsidies to firms. Therefore, letting be the fraction of workers in region g (i.e., ), the budget constraint—which is the same for all consumers—can be written as:
where is the price of variety from sector-j consumed in g. The government of region g can also collect revenues from tariffs () that are redistributed to the whole local population. The term represents the regional trade deficit. Financing a trade deficit requires the inflow of resources from other locations, and this is why appears in the consumer’s budget constrain. Notice as well that this variable can be used in the experiments as a fiscal policy tool.
Given these preferences, the optimality conditions imply that the share of variety in consumption expenditure on the goods produced by industry j is a function of relative prices and the elasticity of substitution. In particular,
where represents the ideal price index of the sector-j final products, which equals
These preferences also imply that consumption expenditure on sector j products in a location g is a constant fraction of total income given by .
Since income is fully spent in consumption goods, as shown by the budget constraint (6), we can express welfare from Eq. (4) through an indirect utility function as:
where is income per capita in region g given by
and provides the ideal consumption price index that households face in location g,
Note that welfare depends on the fraction of workers , on the per capita trade deficit and tariff revenue. Thus, shocks to a sector affect welfare through the trade deficit, the tariff revenues and the price index. Furthermore, constraining the share of working individuals in a region has ceteris paribus first-order effects on welfare.Footnote8
4.1.2 Firms
In each location g, a firm that operates in sector j produces either an intermediate good variety (, ), a final product variety (, ), or a composite intermediate or material (). The production of intermediate goods uses labor and materials from other industries, whereas the production process of final goods and materials demand intra-industry intermediates. Intermediate good manufacturers and final good and material producers in sector j may benefit from subsidization rates and , respectively, which reduce the costs of the different production inputs in the same proportion. All markets are perfectly competitive and firms maximize profits. We next describe in more detail each of the different stages of the production chain.
4.1.3 Intermediate goods
A firm in sector j produces a variety of intermediate goods using labor () and composite intermediates from every other sector k () according to the production function:
where is sector j’s fundamental productivity in intermediate goods manufacturing by region g; is a random sector-variety-specific productivity shock; and denotes the share of value added on gross output. The term affected by the product operator provides the use of materials from all other sectors, with representing the expenditure share of the material from sector k employed in the input composite of the intermediate good produced by industry j. We assume that . Production functions, then, exhibit constant returns to scale.
Because markets are perfectly competitive and firms are profit maximizers, intermediate good prices must equal marginal costs, , where gives the cost of a unitary input bundle once subsidies are taken into account. The cost is common to all varieties and given by
where the constant equals
is the price of the composite intermediate produced by sector k in region g; and denotes the wage rate in location g. Equation (13) says that the subsidy will translate into lower prices because it complements market revenues at paying for the inputs. Notice that the term can be written as a common factor because of constant returns to scale and because production subsidies reduce all input costs by the same proportion.
4.1.4 Final products
In each sector region (j, g) pair, a set of final goods indexed by are produced under perfect competition using intermediate goods from the same sector following a Dixit–Stiglitz aggregator with a constant elasticity of substitution :
where is the sector region fundamental productivity in final goods production; represents the demand in region g for intermediate good from the lowest-cost supplier, which can belong to any of the regions.
Profit maximization implies the following demand function for each or the varieties:
where is the price of intermediate good in location g, and gives the cost of the input bundle with subsidies already embedded as
Equation (15) implies that the demand of intermediate per unit of final output depends on the price of relative to the price of the other varieties of intermediates. Consequently, as a response to the subsidy, the amount for intermediate products demanded can increase, not because of a change in the price that firms perceived , but because of the decrease in the price of the final output (given by the marginal cost), which can cause an increase in .
4.1.5 Composite intermediate goods
Production of materials in sector j uses a very similar technology to the one of final goods. In particular,
That is, it also combines varieties of intermediate goods coming from the same sector. The difference with Eq. (14) is that productivity in the case of the production of the composite intermediate is fully deterministic. The demand for intermediate inputs is analogous to the one delivered by final goods; in particular,
Because composite intermediate goods do not engage in inter-regional trade, the price paid for them by intermediate goods manufacturers is directly given by the marginal cost of production in the same location. This implies that
which is the ratio between the cost of the input bundle accounting for subsidies divided by the productivity of the composite intermediate goods producers.
4.1.6 Inter-regional trade and destination prices
Intermediate goods and final products can travel across locations. Inter-regional trade is costly. Trade costs combine tariffs and iceberg transportations costs. We consider that tariff may be different for intermediate and final goods. More specifically, a sector-j intermediate imported by region g from location i involves a trade cost equal to
where is the imposed ad valorem tariff on intermediate goods from sector j. The transportation cost implies that the arrival of one unit of an intermediate product to g coming from i requires sending units produced of that product. For the case of final goods, trade costs equal
Now, represents the tariff on final goods from industry j, and the iceberg costs related to trade in final goods. Because we will use changes in iceberg costs as proxies to study the effect of supply-chain disruptions, it is only assumed that for all g and i. For the same reason, the usual triangular inequality and may not hold for all g, i and h.
Taking into account these trade costs, the prices at destination of the traded products from the lowest-cost supplier are given by:
and
Equations (22) and (23) imply that the price at destination will be given by the minimum across locations of the product between the marginal cost and the trade cost. A more expensive input bundle or higher trade costs will push the price up, whereas a larger productivity will push it down.
Following Eaton and Kortum (2002), trade in the model obeys a Ricardian motive generated by a random allocation of productivities across sectors and regions. In particular, the realizations of the productivity variables and for varieties and follow Fréchet distributions with location parameter equal to 1 and sector-specific shape parameters and , respectively. A smaller value of the shape parameter implies a larger dispersion of the distribution. We assume that the random productivity variables are independently distributed across goods, industries, and regions. Furthermore, we impose that and . Following Caliendo and Parro (2015), under these assumptions for the distributions of productivities, we can rewrite Eqs. (16) and (8) as
where is the gamma function.
In the case that a sector is not tradable, which implies that all the varieties of intermediate goods and consumption products from that sector are bought from domestic producers, Caliendo and Parro (2015) also show that the relevant price indices amount to imposing that for all in Eqs. (24) and (25). Then, we can express and as
and
4.1.7 Expenditure shares
Let and be region g’s total expenditures on intermediate goods and final products from sector j, respectively. They are obtained at destination prices, and therefore, include tariff payments. Define and as the expenditures in location g on sector-j intermediate goods and sector-j final products, respectively, imported by location g from location i. Finally, let and be region g’s total expenditure shares of intermediate goods and final products from sector j exported by location i to location g, respectively, that is, and . Following Caliendo and Parro (2015), it can be shown that
Bilateral trade shares contain important information. First, they are declining on transport costs and increasing in the productivity of the producer (since this productivity reduces the marginal cost directly). Second, they include information on the input–output structure of the whole economy through the prices paid for intermediate inputs. Furthermore, this input–output structure is also affected by the economic geography, since intermediate inputs can be imported from abroad. In terms of the effects of policies regarding the control of COVID-19, this gravity equation is potentially informative for several reasons. It can potentially capture the fact that some sectors might be more affected by social distancing policies, since sectors can differ in their labor input intensities. Dingel and Neiman (2020) estimate that, in the USA, the share of jobs that can be done from home significantly varies across cities and industries and also show that this share is decreasing in the level of development of the countries. Our model could plausibly capture this. Our model could also show the effects of how shutting down a certain sector or region would affect the rest of sectors and locations through the input–output structure. Furthermore, in the second phase of the model, infections can be spread through economic linkages; since some sectors are more interconnected than others, those regions that are more intensive in certain inputs can show significantly faster infection rates.
4.1.8 Market clearing and government and regional deficits
Local labor markets require that the sum of labor employed in the different industries equals the total amount of labor available in the region. Formally,
Furthermore, because in equilibrium labor costs must equal a constant fraction of the value of the intermediate goods production, the following condition must hold:
Notice that the right-hand side of Eq. (29) adds the expenditures across sectors and regions on intermediate goods manufactured in location g that go to pay the labor input. It also implies that payments to labor are in part satisfied using the subsidies, in an amount equivalent to a fraction of the revenues from sales. We divide by the tariff to convert each expenditure amount into the value of production.
In the same manner, the total value of the production of composite intermediates from sector j in a location g has to be equal to a subsidy-weighted fraction (determined by all ) of the expenditure on region g’s intermediate goods across sectors and locations. In particular,
Notice that market clearing conditions (29) and (30) imply as well that the intermediate goods market clears.
Employing again a production expenditure equality, market clearing in the location g’s final goods market requires that the value of the sector-j final goods produced in g equals the consumption expenditure across regions on final products from that location. Taking into account that the revenues from the production activity of the final product sector fully goes to pay for the intermediate goods used as inputs, we can write the market clearing condition as:
The left-hand side of Eq. (31) subtracts the value of materials to provide just the amount of expenditure in intermediate goods satisfied by final goods producers. The subsidy is in the equation because the expenditure on inputs, , equals the market revenues—given by the terms affected by the sum operator—plus the subsidies received by the industry.
Note that consumers’ expenditure on sector-j products in region-i is a fixed fraction of their income. Hence,
where income per capita , given by Eq. (10), is a function of tariff revenues. We can now express tariff revenues, , using the notation introduced previously as:
Moving next to the determination of the trade balance, we consider that the regional trade deficit is given by the sum of the sectoral deficits, . The sectoral deficit equals the value of the region g’s imports of industry-j goods from all other locations minus the value of exports of sector-j products from location g to all other locations. This is equivalent to imposing that the deficit is given by the difference between total expenditure by region g on sector-j intermediate and final products net of tariffs and the total value of production of industry-j intermediate and final goods in location g. More specifically,
The second parenthesis gives the value of production by adding across locations the amount spent on products from the sector region pair (j, g) net of tariffs.
Therefore, trade balance in location g implies the sum of the sectoral trade deficits must equal the regional one, which implies
It can be shown that the trade balance condition, equation (35), implies that the labor market clears, that is, equation (29).
Finally, we allow for the possibility that the regional budget deficit, denoted by , is not zero. Therefore, the following condition must hold:
That is, if the expenditure in subsidies is larger than the taxes collected to finance them, there will be a positive budget deficit.
4.1.9 Equilibrium system in relative changes
As in Caliendo and Parro (2015), we solve the model in changes.Footnote9 Let us denote a proportional change in a variable with a hat (  ) and the value of the variable next period with a prime (). Then, for example, . The exogenous shocks that we will consider correspond to new tariffs, and , new subsidies to firms, and , supply-chain disruptions proxied by changes in the trade costs, and for , local production restrictions proxied by and , and confinement policies captured by new stocks of available labor in the region, .
) and the value of the variable next period with a prime (). Then, for example, . The exogenous shocks that we will consider correspond to new tariffs, and , new subsidies to firms, and , supply-chain disruptions proxied by changes in the trade costs, and for , local production restrictions proxied by and , and confinement policies captured by new stocks of available labor in the region, .
Equations (13) and (19) imply that the gross growth rate in the cost of the intermediate goods input bundle equals
In turn, combining expressions (24) and (26) obtains the change in the cost of the final goods input bundle and the export shares of intermediate products as
and
respectively, where .The gross growth rate in the sectoral price index and the final good export shares are obtained from Eqs. (25) and (27) as
and
respectively, where .
Market clearing conditions can be employed to obtain the future values of the expenditure variables as a function of the above changes. In particular, market clearing for final goods, equations (30) and (31), implies that region g’s next-period expenditure in intermediate goods from sector j is given by:
Notice that and can be written as and , respectively.
From Eqs. (10), (30), (32), (33), and (36), next-period’s expenditure in final goods from sector j is given by
where
Again, we can write as so that it becomes a function of the changes determined by previous equations in the system.
The system formed by Eqs. (37)–(44) is underdetermined because the number of unknowns is equal to the number of equations plus one. In order to solve it, Caliendo and Parro (2015) assume that the economy’s trade deficit in each location g is exogenous. We, on the other hand, allow for the trade deficit to be determined by the model and, instead, required that the wage rate does not vary. This looks to us more appropriate for the problem that we analyze.
Equations (37)–(44) imply that we do not need to calibrate fundamental productivities and trade costs to solve the system. We simply start from a baseline scenario that consists of initial data on regional wages, labor, and trade and budget deficits , pairwise regional expenditure shares and tariffs in every sector , and the assumption of no subsidies for firms, . We also need to assign values to the labor share in gross output (), the share of intermediate goods from sector k employed in the production of sector j (), the share of consumption expenditure on sector-j goods (), and the shape parameters and of the Fréchet distributions. With that information on our hands, we consider shocks on the values , , , , , and/or , and solve the system going through the following steps.
- 1.Assume for all g.
- 2.From Eqs. (37) and (38), obtain .
- 3.Once we know the cost of the unitary input bundles, we can recover from Eqs. (40)–(41) the values of .
- 4.Obtain using (42) and (43).
The above implies that in this economy, an equilibrium in relative changes can be defined as follows. Given the new value of the regional labor supply , regional deficits , and pairwise regional government tariffs on intermediate goods and on final goods , a competitive equilibrium is a set of changes in intermediate good and final product price indices in for each sector location pair , and pairwise regional expenditure shares in every sector , in addition to new values of the total sector location expenditure volumes , such that the optimizing conditions for households, intermediate product manufacturers, final good firms and material producers—which are reflected in Eqs. (13), (19), (24) to (27), and (32)—hold, and market clearing in all markets is achieved through conditions (30), (31) and (34).
4.2 Phase 2: infection dynamics
The infection dynamics take place at the local level but we allow for possible contagions across locations depending on effective distance. Typically, epidemiology models characterize the transitions from one state to another with exogenously given probabilities that refer to the characteristics of the particular infection. Here, instead, we assume that transition probabilities depend on two factors, one exogenous that captures the characteristics of the infection, and an endogenous geographic component that captures how more economically active locations can be more prone to infections since they have more connections with the rest of locations.
People that work face-to-face, people that work telematically, and people that do not work have different probabilities of catching the disease due to their different number of encounters with other people. Additionally, individuals that have recovered from the disease or have been vaccinated can have a lower probability of becoming infected. We assume that all the infected, regardless of whether they are in hospital or not, are able to pass the disease to workers.
We consider two scenarios where people can become infected. Firstly, infection transmission can occur locally, between residents of a given region, through non-work-related social interactions, (e.g., visiting relatives, walking in public spaces, or when final consumers purchase goods). Secondly, the virus can be transmitted through work-related activities, which we refer to as the geographic component. This includes interactions such as workers in a factory producing output, interactions between workers from different firms or locations, and interactions between workers and final consumers. Within this second component, consistent with the evidence reviewed in Sect. 2, the movement of goods and services within and between regions represents an important vector for the transmission of the disease because some degree of human interaction always occurs during those transactions. For example, this can happen when infected tourists come into contact with service providers or via infected truck drivers who transport goods.Footnote10
Hence, the dynamics for infected people can be written as:
where the term is given by
the coefficient gives the fraction of infected that become resolving every period; captures the proportion of infections that arise in work-related contexts and is time-invariant. The time-varying probability provides the likelihood that a susceptible individual contract the disease upon encountering an infected person. We allow this parameter to be affected by local policies and local behaviors. Parameter controls for the degree of telematic work in region i, which reduces contact among people at the workplace. Finally, represents the relative level of bilateral transactions between i and g.
We assume that this relative level of bilateral transactions between two regions is given by:
Equation (47) aims to capture the level of market-related human interactions between two economies i and g as a function of bilateral imports and exports when two different locations trade, or as a function of the local expenditure volumes if market activity is fully local.Footnote11
Therefore, according to motion Eq. (45), the number of infected people tomorrow depends on infected people today net of those that become resolving cases. The equation also considers that the susceptible can catch the disease. As expression (46) specifies, this can occur through the social and the geographic components. The strength of the social component in region g depends on the weight of non-work-related interactions , the relative prevalence of the disease , and the contagion probability , all of them referred to region g. However, the strength of the geographic component depends on variables related to the trade partner i. Here, we are assuming that the probability of disease transmission is primarily determined by the policies that affect the infected individual and her habits. Specifically, the strength of the geographic component depends on the proportion of work-related infections, disease prevalence, the contagion probability, the degree of telematic work () in region i, and on the relative level of bilateral transactions between i and g ().Footnote12
The following equations, along with Eq. (45), describe the full epidemiological model:
Parameter provides the fraction of the susceptible that are vaccinated during the period in location g; and are the fractions of the recovered and the vaccinated that fully lose immunity, respectively; the parameter reflects the fraction of cases that resolve in a given period, and therefore, its inverse pins down the average number of periods it takes for a case to resolve; and relates to the average number of days (given by ) a person is infectious.
Equation (48a) says that the size of the susceptible population decreases with the fraction that receives the vaccine and the fraction that gets infected by the COVID-19 virus, but rises with the recovered and vaccinated that lose their immunity. The vaccinated population, equation (48b), increases with the fraction of the susceptible that receive the vaccine and decreases with the vaccinated individuals that lose immunity. In Eq. (48c), in turn, a fraction of infected individuals become resolving, and a fraction of cases is resolved. The number of recovered individuals, as given by Eq. (48d), evolves in a similar way to that of the vaccinated. A fraction loses their immunity and some of the resolving, among the fraction that survive, recover during the period. Regarding the evolution of the stock of fatalities (), according to Eq. (48e), the new deaths come from the fraction of resolving that resolve and die. Finally, the evolution of the region’s population is given by Eq. (48f), which implies that a fraction of the resolving cases die.
5 Calibration
The main source for the calibration of the economic part of the model is Thiessen (2020), which offers the Rhomolo-MRIO Tables for 2013 published by the European commission. The dataset provides input–output tables for a set of 268 regions that include 267 EU28 NUTS2-2010 areas plus the rest of the world (ROW). Nevertheless, due to the lack of sufficiently disaggregated data for the disease variables, we need to aggregate some locations to the NUTS1 and country levels. After doing so, we are left with 230 regions (see Table 1). The numbers are disaggregated into ten main sectors of activity belonging to the NACE Rev2 classification (see Table 4). A summary of the data sources employed for the calibration of both the economic and disease parameters—and in some cases their values—are provided in Table 5.
From Thiessen (2020), we compute , that is, the shares of the different sectors in total consumption expenditure in each location. The same dataset allows deriving estimates of the share of value added on gross output, , and the expenditure share of each material employed in the input composite of the intermediate good produced by other industries, .Footnote13 Table 6 provides a summary of the calibrated parameters.
The sector-specific shape parameters and of the Fréchet distributions related to the productivity variables and , respectively, are obtained as follows. Consider two regions, i and g, and the bilateral trade expenditures between them, , , and . Recall that expenditure shares and are given in equilibrium by Eqs. (26) and (27), respectively. These expressions imply that we can write:
and
Equations (49) and (50) provide gravity equations for intermediate and final products, respectively. They present bilateral trade expenditures as a function of bilateral trade costs. Equations (20) and (21) indicate that trade costs are composed of tariffs and iceberg costs. We assume, only for the purpose of estimating the trade shares, that , where represents symmetric bilateral trade costs like distance (geographical, language, etc.) or belonging to a certain trade agreement; and capture sector-specific fixed effects in the importer and exporter regions, respectively, and is a random disturbance. Substituting those expressions for trade costs into (49) and (50), equalizing tariffs to zero and taking logs, we obtain:
and
where . Hence, all asymmetric components of the iceberg costs (, , and ) have cancelled out. Additionally, we have equalized tariffs to zero because, in the estimation, we use data on export spending for the EU28 in 2013 from Thiessen (2020) but exclude the flows from and to the rest of the world. Since trade among EU members is not subject to tariffs or other trade restrictions, we can get rid of tariffs.
As a proxy for the symmetric component of the bilateral trade costs, we employ distance between regions obtained from Persyn et al. (2020). This dataset gives estimates of different distance measures between EU regions at the NUTS2 level. We choose the distance measure that provides arithmetic averages over the geodesic distance between many centroids for each region pair. Each region has more than one centroid and then . In the estimation, we use data on expenditure variables ( and ) from the original 267 European regions considered in Thiessen (2020) to maximize the amount of information.
To obtain the trade elasticities ( and ), we estimate (51) and (52) for each sector j separately. The results of their OLS estimation are presented in Table 7, which provides the estimated coefficients along with their robust standard errors. We observe similar estimates for intermediate and final products, ranging from 1.99 to 3.09 for intermediate goods and from 1.94 to 3.09 for final products. Although small, the difference between coefficients of different sectors are often statistically significant. The smallest elasticity corresponds to construction (sector C), and the largest to public administration, defense, education, human health and social work activities (sectors O_Q). These estimates are smaller than the ones found by Caliendo and Parro (2015), who obtain values between 0.37 and 51.08, with an aggregate trade elasticity of 4.55.
We now turn to the parameters that govern the disease dynamics. We calibrate using the estimates from Dingel and Neiman (2020). In particular, we estimate the percentage of workers in each sector who can work from home , and then we compute for each region as
which is a weighted average where the weights are sectoral expenditure shares. This takes into account the sectoral composition of each region.
Parameter is obtained from Eichenbaum et al. (2021), where it is estimated that of infections are related to work environments. We take , and from Fernández-Villaverde and Jones (2022). Specifically, the parameter is set to 0.125, implying that an individual is infectious for 8 days. We assign a value of 0.143 so that the average case takes 15 days to fully resolve (8 days infectious plus 7 of resolving). The mortality rate is fixed at .
Next, since we focus on the first wave, we equalize to zero the vaccination rate and the immunization loss for vaccinated, . The evidence on reinfection rates for COVID-19 is still unclear. Regarding reinfection among those not vaccinated, Sheehan et al. (2021) estimate that the protection from getting infected ranges from 81.8–84.5%. Taking into account this evidence, we fix which implies a protection from the infection of .
We recover the time-variant , representing the probability that a susceptible individual contracts the disease.Footnote14 Because some regions lack data on COVID-19 daily deaths (see Table 5 for details), we must divide our sample in two groups. The first group consists of areas that report daily deaths, while the second group comprises regions that only report confirmed cases. In all cases, we eliminate the geographical component by setting to be able to calibrate in isolation. The main reason to do this is that our methodology recovers current based on information from future deaths. However, the start of the pandemic across regions varies substantially in the data. Then, if the geographic component were active in the calibration and, consequently, the were determined jointly, we would many times encounter a large number of zero deaths, which would render the equation system indeterminate.Footnote15 As will be shown later, assuming during calibration leads to an underestimation of the number of daily deaths.
For those regions that report deaths, we extend the approach suggested by Fernández-Villaverde and Jones (2022), which essentially boils down to obtaining as a residual using data on deaths only. Specifically, from the death data and Eq. (48e), we can recover the resolving cases. Subsequently, the evolution of the resolving (Eq. 48c) allows obtaining the infected. Finally, the motion equation for the infected (Eq. 45) delivers . This method is explained in detail in Appendix B.
However, sometimes in a region, we encounter three consecutive days with zero reported deaths and then the method breaks down. When this occurs, we estimate a constant infection rate , and assign it (i.e., ) to the region and periods in which it is not possible to recover it due to the consecutive zeros problem. The method to compute is the following. Once we make , can be obtained in isolation from other regions. Then, we estimate by NLLS so as to minimize the distance of the predicted deaths from the actual death observations.
For the regions that do not report daily deaths, we assign daily values to based on the reported number of daily infections. Initially, using Eqs. (45) and (46), we recover a preliminary for each day and region from the infection data. This preliminary serves to generate the necessary time series of predicted fatalities from the system of Eqs. (45) to (48e). Once we have the estimated deaths, we follow the method described in Appendix B to obtain the final values to be used during the simulations.
To initiate the simulations, we need initial values. Tables 8 and 9 provides some of these initial values for different economic- and disease-related variables, respectively. The population size at the begining of the pandemic in each region comes from the same sources as deaths (see Table 5). However, for consistency with the input–output data, the rest of numbers are extracted from the year 2013. We pick the expenditure shares of intermediate goods () and final products () by sector, origin and destination from Thiessen (2020). The number of workers, , is obtained from different sources. In particular, for the EU28, we take employment by NUTS2 regions from regional labor statistics by Eurostat. For ROW, we extract the number of persons engaged from Penn World Tables, 10.0 (Feenstra et al. 2015). To get a better idea of the differences in population size and employment levels, Figs. 1 and 2 show population density and the employment-to-population ratio, respectively, across the regions considered.
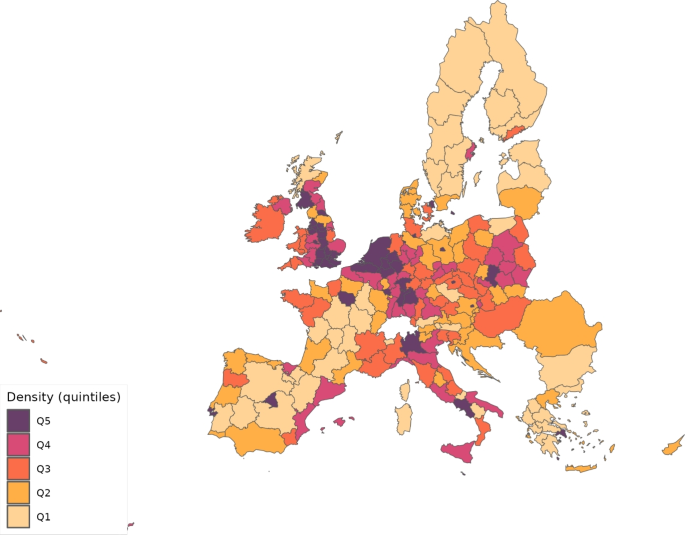
Population density across regions
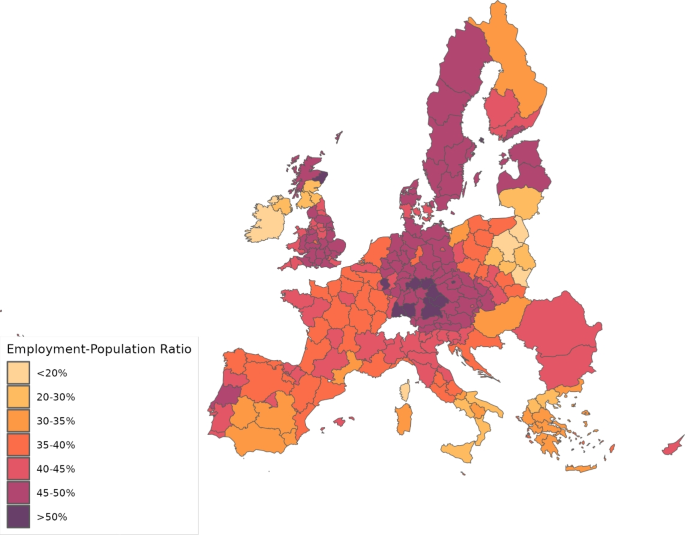
Employment to population ratio
Wages, , are calculated as total compensation of employees divided by the employment figures. Total compensation of employees for the EU27 group (EU28 minus the United Kingdom) comes from the Eurostat regional accounts data, whereas for the UK, we get them from the gross annual pay for all employee jobs reported by Annual Survey of Hours and Earnings. For ROW, compensation of employees are directly taken from Thiessen (2020). Lump-sum taxes are calibrated so as to reproduce the observed total expenditures on final products by region and sector () provided by Thiessen (2020). Figures 3 and 4 show the distribution of wages and the share of non-telematic workers, respectively, across the regions considered.
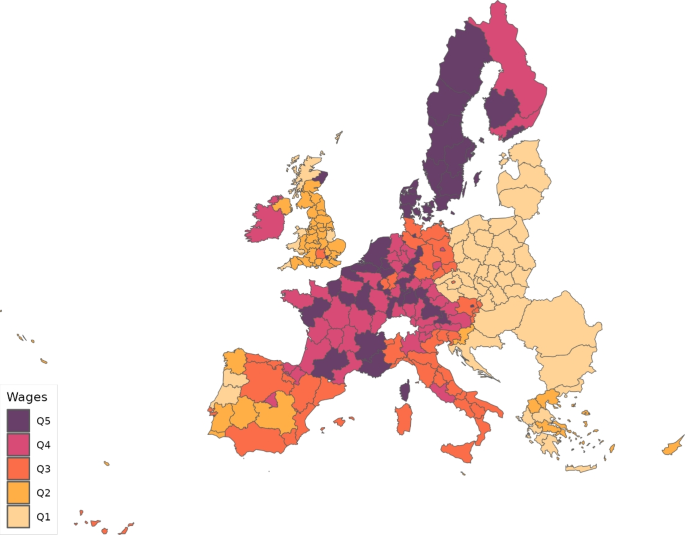
Wages
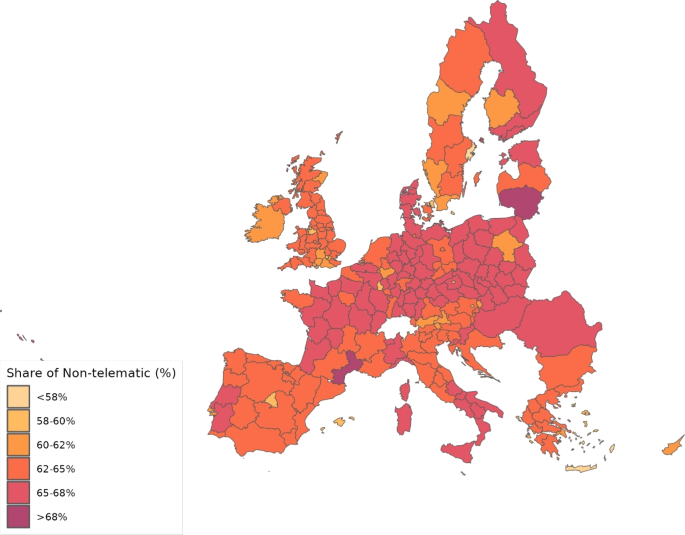
Share of non-telematic workers
Subsidies for intermediate goods () and final good products/materials () are equalized to zero. Bilateral ad valorem tariffs for intermediate and final goods, denoted by and , respectively, are zero among EU members. The only tariffs different from zero are those related to ROW. We assign values to the different industries using information from Eurostat (2017) on average import tariffs imposed by the EU28 to other countries in 2013 and WITS – UNCTAD TRAINS information.
Finally, since the mechanism we emphasize involves trade through the transportation of goods and tourism, it is essential to account for the anti-COVID-19 policies that restricted the movement of people (i.e., mobility restrictions). As we show in Sect. 6.1, the parameter already reflects the impact of anti-COVID policies. However, we calibrate excluding the geographic component. As a result, primarily captures the effect of anti-COVID policies on the social component. To more comprehensively account for the influence of mobility restrictions via the geographic component, we consider their impact on the amount of labor available for production, sectoral consumption expenditure shares, and trade costs.
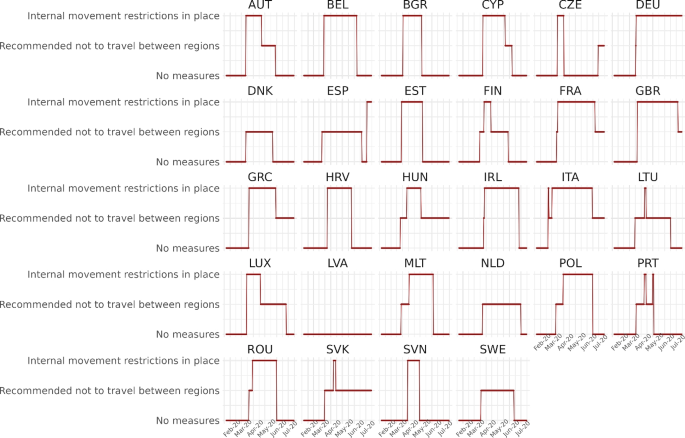
Figures 5 and 6 plot the internal and international restrictions to the movement of people, respectively, imposed by the countries in our sample during the first wave of the COVID-19 pandemic. These data are sourced from Hale et al. (2021)—the Oxford COVID-19 Government Response Tracker (OxCGRT). Hale et al. (2021) classifies the restrictions on internal movement within countries in three categories: (a1) no measures; (a2) recommended not to travel between regions; and (a3) internal movement restrictions in place. In our analysis, we consider internal movement of people to be restricted in a certain location on a particular day if its national government implemented either (a2) or (a3).
Internal movement restrictions
International movement restrictions
Importantly, internal mobility restrictions were closely linked to productive lockdowns because the affected economic activities were those that heavily relied on physical presence and the transportation of goods and people. Consequently, we will use these two terms interchangeably. Moreover, we will assume that when internal mobility restrictions are in place, the sectors impacted by productive lockdown are shut down and cannot sell their products.
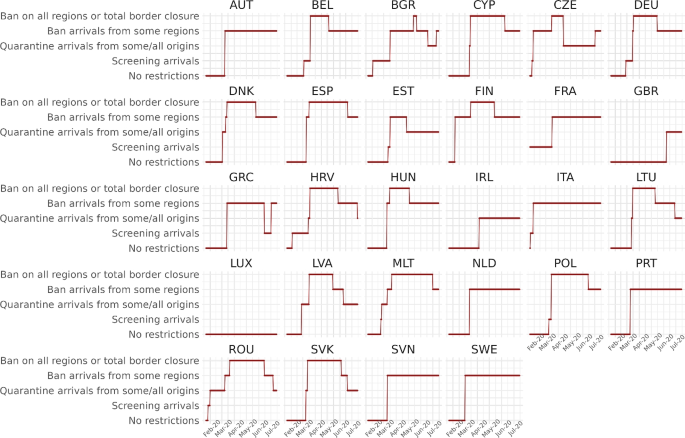
In turn, Hale et al. (2021) classifies restrictions on international movement into five categories: (b1) no restrictions; (b2) screening arrivals; (b3) quarantine arrivals from some/all origins; (b4) ban arrivals from some regions; and (b5) ban on all regions or total border closure. We consider international movement restrictions to be in effect for a country on a particular day when either (b3), (b4) or (b5) is implemented. Under these conditions, consumers and firms from foreign countries are unable to purchase domestic products from sectors disrupted by productive lockdowns.
Figures 5 and 6 indicate that the strength of the restrictions and their duration significantly vary across nations. For example, regarding internal movement, Denmark (DNK), Latvia (LVA), the Netherlands (NLD), and Sweden (SWE) never imposed strong restrictions, while Italy (ITA) imposed severe restrictions most of the time. Likewise, Greece (GRC), the Netherlands, Portugal (PRT), Slovenia (SVN), and Sweden imposed a total border closure during long periods of time, whereas Great Britain (GBR) never imposed any ban on international arrivals.
In several countries, industries that were fully closed for significant portions of the pandemic include hotels, restaurants, and accommodation; estate and travel agencies; and leisure and recreation services. Therefore, given the level of aggregation in our dataset, we consider that, within our industry classification, the sectors most affected by the mobility restrictions correspond to category G_I—wholesale and retail trade, transport, accommodation and food service activities—and category R_U—arts, entertainment and recreation; other service activities; activities of household; and extra-territorial organizations and bodies. These two categories represent sectors 5 and 10, respectively, in our simulations.
While sectors 5 and 10 encompass the industries most impacted by the productive lockdown, they contain as well other sectors that were less severely affected.Footnote16 Nevertheless, the fraction of workers employed by categories G_I and R_U combined ranges from 0.23 to 0.37 in our sample of regions, aligning closely with the lower and upper bounds found by Fana et al. (2020) for the share of workers most affected by lockdown policies—in particular, those employed in mostly non-essential and closed activities—in a set of EU and UK economies. This provides confidence that our approach reasonably captures the proportion of the economy affected by anti-COVID policies.
Consequently, we assume that when the internal movement of people is restricted, labor availability, consumption expenditure shares, and trade costs are impacted. Specifically, we set the consumption expenditure shares of sectors 5 and 10 to zero (i.e., ), reflecting consumers’ inability to purchase goods from these sectors. Simultaneously, we proportionally increase the consumption expenditure shares of other sectors so that continues to hold. In turn, the total labor force available in the region on that day () is reduced by the amount allocated in our model to sectors 5 and 10 based on intermediate goods expenditures derived from the Rhomolo-MRIO Tables for 2013, as these workers are sent home due to the restrictions.
Additionally, the rich trade structure of our model allows us to account for the effect of mobility restrictions by adjusting the bilateral trade cost parameters. When internal movement restrictions are imposed in region g, sales from the affected sectors in region g to all regions are not possible. To model this, we multiply parameters and , for and , by a large factor of relative to their benchmark values to sufficiently reduce trade from these two sectors in region g to every destination i.
Similarly, to incorporate international movement restrictions into the geographic component, we assume that when such restrictions are implemented in location g on a particular day, the iceberg cost parameters and , for and , are multiplied by a factor of relative to their benchmark values. This adjustement sufficiently reduces trade from every origin i to sectors 5 and 10 in region g.
6 Results
We focus on the first wave of the COVID-19 pandemic, and more specifically, in the period that goes from February 25 to July 15, 2020. We start by performing an external validation exercise for the calibrated values of the parameter . Subsequently, we compare the fatalities caused by the pandemic in the UK and the European Union, and assess how well the model reproduces them. Finally, we present results from the policy counterfactual simulations.
6.1 External validity
Parameter is one of the crucial elements for our results. We argue that its variations proxy the evolution of the anti-COVID policy. However, there are aspects that the model does not consider and might also be capturing. To understand better what is capturing, we first correlate the initial value of with a potential determinant such as differences in population density. The first column in Table 10 shows the estimates of regressing the initial with the log of the population density of the regions after controlling for latitude and longitude. We find that the coefficient is positive and statistically significant, which suggests that denser regions tend to have a larger initial . If we control for initial deaths (column (2) in Table 10) and the share of non-telematic workers (column (3)), the coefficient for the log of the density still remains positive, statistically significant, and very similar in magnitude.
Secondly, we need to show whether our calibrated in fact reflects features of anti-COVID policy differences across European regions. To do so, we regress the values of for each region and time period on three different indices that reflect anti-COVID-19 responses. These indices are obtained from the Oxford COVID-19 Government Response Tracker Database (Hale et al. 2021). Since policy decisions were primarily made at the country level, the Oxford COVID-19 Government Response Tracker Database only provides indicators at the national level. Thus, we regress the calibrated for each region over time on each index, adding region, country and date fixed effects. These fixed effects absorb unobserved constant characteristics at the region and country level, and control for common time trends.
The three indices we consider are the containment and health index, the average stringency index, and the government response index. The three of them capture policies that tried to prevent the spread of COVID-19, but each index captures different aspects. The containment and health index measures policies related to containment and closure policies and health system policies. The average stringency index contains all measures related to containment and closure policies as well as public information campaigns. Finally, the government response index is a composite of all aggregates (containment and closure policies, economic policies, health system policies, and vaccination policies).
Table 11 provides the results. The estimated coefficients are negative and statistically significant for the containment and health index, as well as for the government response index. The average stringency index again shows the expected negative coefficient, but it is not statistically significant. This could be because during the first wave of the pandemic, most of the policies implemented were related to containment and closure, which receive less weight in an average index that includes multiple other policies.
Taken together, these results suggest that indeed reflects anti-COVID policy responses across European regions. In the following subsection, we will assess how well the calibrated reproduces the fatality data.
6.2 The COVID-19 fatalities
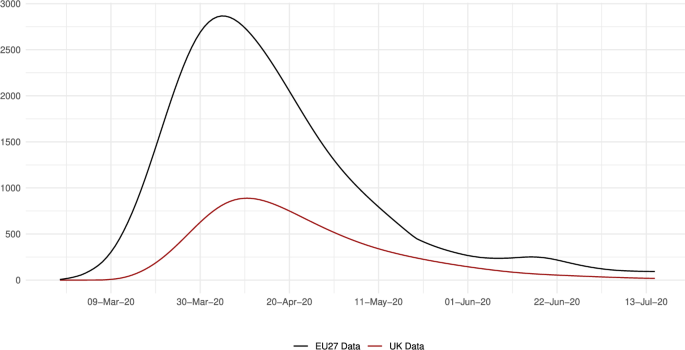
Figure 7 provides the total daily number of deaths in the European Union (EU27) and in the UK. This number, in our smoothed time series, reached a maximum value of 2,867 in the EU27 on April 4, and 887 in the UK on April 11. That is, the pandemic in the UK evolved with a one-week lag compared to the European Union.
Total daily deaths in the EU27 and the UK
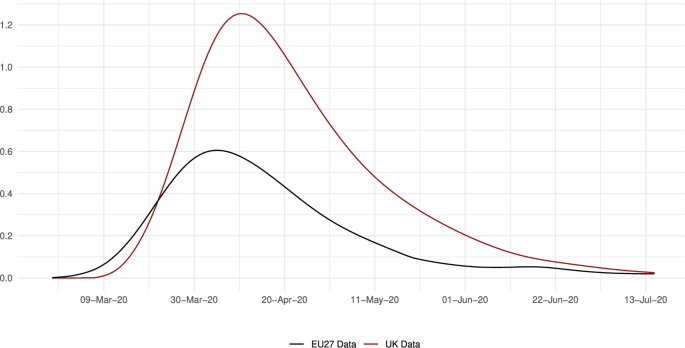
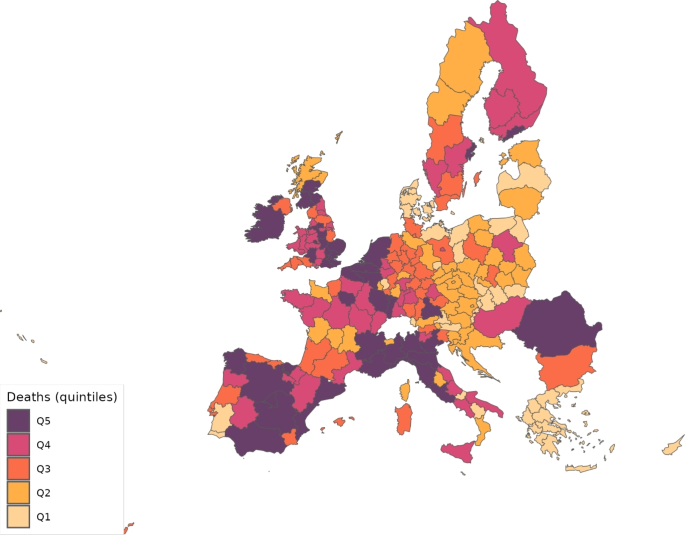
Nevertheless, even if the level of death events were larger in continental Europe, the incidence of the disease was actually larger in the UK. We can observe this fact in Fig. 8, which reports the number of deaths per 100,000 inhabitants. In the UK, this ratio reached 1.25, whereas in the EU27, its maximum was a bit less than half that number; in particular, it was 0.61. The map in Fig. 9 shows the cumulative deaths per 100,000 inhabitants up to July 15 by regions. This map shows that most of the regions in the UK were in the fourth or fifth quintiles of the death distribution, similar to northern Italy, and northern Spain.
Daily deaths per 100,000 inhabitants in the EU27 and the UK
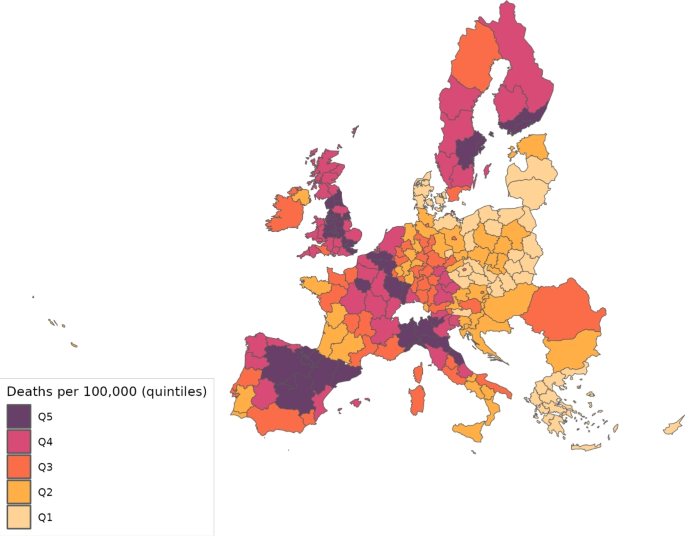
Cumulative deaths per 100,000 inhabitants across regions (July 15, 2020)
Figure 10 presents the average value of the parameter across NUTS2 regions. It is important to remember that this parameter is calibrated as a residual, meaning that its values reflect both the disease ecology and the impact of pandemic-fighting policies. From Fig. 10, we can observe that the probability of infection reached higher values in the UK than in the European Union. The maximum, in particular, was 0.20 on March 21 for the former economy and 0.14 on March 22 for the latter. However, we can also see that the reduction was faster and deeper in the UK than in the EU27. Consequently, policies seem to have been more successful in the UK, maintaining after April 16 a gap in favor of the UK of about 2 percentage points.
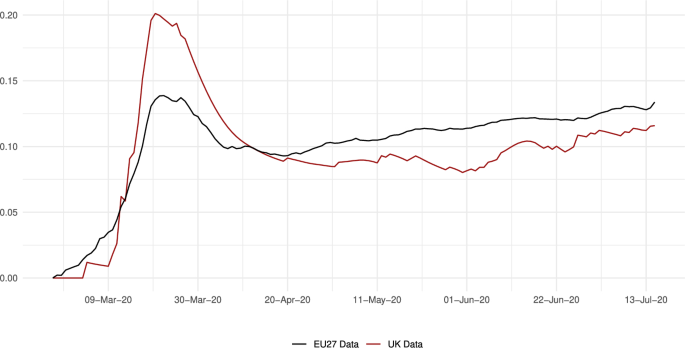
Average daily in the EU27 and the UK
Let us now have a more disaggregated view of the UK death data. Figure 11 plots the number of deaths in each of the 37 NUTS2 regions in the UK. The largest number of daily cases was achieved in Inner London-East (UKI2), Greater Manchester (UKD3) and West Midlands (UKG3) with 118, 64 and 57 deaths in one day, respectively. The lowest daily numbers, on the other hand, took place in North Eastern Scotland (UKM5), Highlands and Islands (UKM6) and Northern Ireland (UKN0) with 3, 3 and 4 cases, respectively.
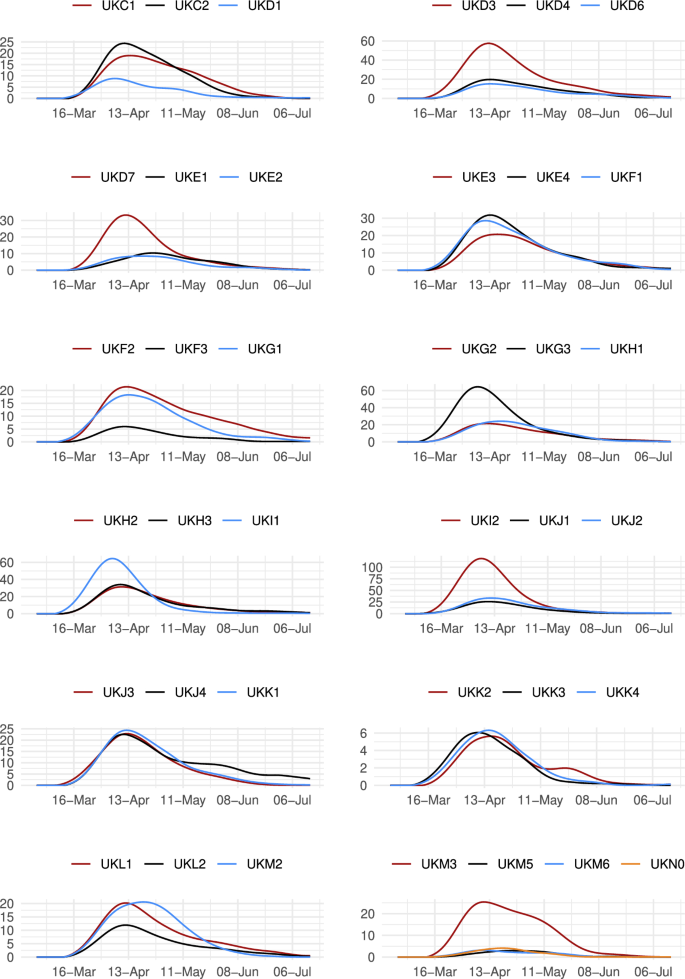
Total daily deaths in the UK NUTS2 regions
Even though the number of deaths and their relative magnitude per 100,000 inhabitants show a high correlation of 0.561, they do not correlate perfectly. In the second column of results in Table 12, we see that the largest volumes of deaths per 100,000 inhabitants are found in Greater Manchester (UKD3), Cheshire (UKD6), Trees Valley and Durham (UKC1) and West Midlands (UKG3), with rates equal to 93, 90, 87 and 87, respectively. Conversely, the lowest rates are observed in Northern Ireland (UKNO), Dorset and Somerset (UKK2) and Devon (UKK4), where these rates were 6, 19 and 22, respectively.
Finally in this subsection, we analyze how well the model matches the fatality data. Figure 12 shows that the model predictions in the benchmark scenario follow well the aggregate trend and its changes in the UK and the European Union. Nevertheless, they tend to underestimate the number of deaths. Comparing columns one and three in Table 12, we can see that this results in an error in the predicted total number of deaths of 20.9% and 23.4% for the European Union and the UK, respectively. This is partly due to the method followed to calibrate the parameter , which does not consider the geographic component of the infection (see Appendix B for details).
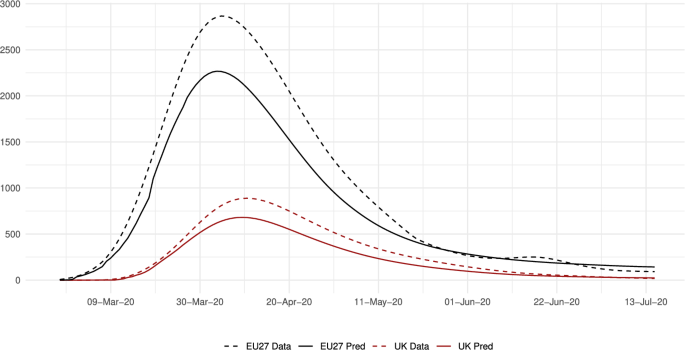
Daily deaths: data versus predictions
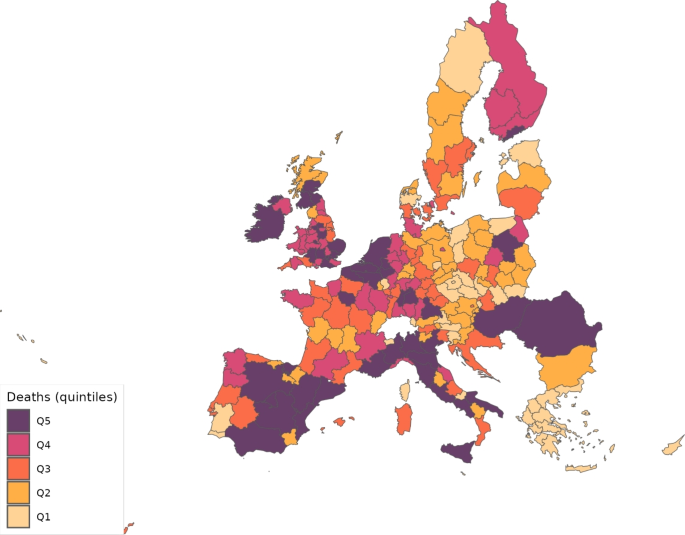
Looking now across regions, Fig. 13 shows the distribution of predicted deaths, which can be compared to the actual distribution shown in Fig. 9. Overall, the model fit is good.
Predicted deaths
6.3 Policy counterfactuals
Our next task is assessing how anti-COVID policy has influenced the number of lives saved. Firstly, we ask: what would have been the cost for the economy in terms of deaths if no policy had been implemented? Secondly, we assess the importance of the geographic component, and the policy cross-effects between the UK and the European Union that it generates. Thirdly, we ask: how many lives could have been saved if all regions had enjoyed the disease ecology and policies implemented in the most successful areas?
6.3.1 No-policy scenario
In our model, the implemented policy measures are represented by the evolution of the parameter and the adjustments to , , and in response to mobility restrictions. Unlike , , and , determining the value of in the absence of policy measures is not immediate. At the regional level, the parameter reaches it largest values at the beginning of the infection in the corresponding area, and then goes down due to the policy actions implemented.Footnote17 However, in general, governments did not react immediately to the first COVID-19 infection cases. The average reaction time varied from a few days to a couple of weeks. Therefore, in order to assess how many additional deaths would have occurred if no policy had been implemented, we keep the parameter constant at its average over the first ten days during which region g reports fatalities. This approach should provide a value of not significantly affected by anti-COVID policy. Additionally, averaging over 10 days reduces concerns about measurement error.
We assess the impact of changes in and the adjustments due to the mobility restrictions through two separate exercises. Table 12 in the columns labeled as “Predicted deaths, no restrictions” presents the results of eliminating the adjustments to , , and , while maintaining the calibrated evolution of . We see that, in this scenario, due to changes in trade patterns, deaths in the EU would have totaled 107,111 instead of the predicted 105,801, and 30,571 instead of 30,571 in the UK, representing an increase of 1.2% and 0.2%, respectively. These figures translate to lives saved of 0.06 and 0.07 per 100,000 inhabitants in the EU27 and the UK, respectively, which are relatively low numbers.
In turn, the columns labeled “Predicted deaths with constant” in Table 12 present the results when remains unchanged, while , , and are adjusted to account for mobility restrictions. Without the policy response of , deaths would have totaled 4,519,392 in the EU and 1,244,497 in the UK, representing an increase of 4,172% and 3,978%, respectively, compared to their benchmark values. In terms of the lives saved per 100,000 inhabitants, the average for the EU27 and the UK equals 202 and 1718, respectively. The impact is now substantial and notably stronger for the UK.
These findings suggest that the primary effect of policy operated through the social component. The impact of mobility restriction on workplace infection, captured by the geographic component, seems to be relatively minor.Footnote18 Therefore, in the remaining policy counterfactuals, we will focus exclusively on the effects of changes in .
Figure 14 shows the distribution of predicted deaths across NUTS2 regions when remains constant, which can be compared to Fig. 13. We see that the effect is not homogeneous across Europe. For example, some regions in southern Italy and near Madrid in Spain move to upper quintiles of the distribution, whereas most regions surrounding Paris and in southern Sweden move to lower quintiles. This highlights that if anti-COVID policies had not been implemented, the distribution of disease incidence across European regions would have been very different.
Predicted deaths with constant
Going back to Table 12, there is a relatively high correlation of 0.667 between the number of deaths in the data and the lives saved by policies across NUTS2 regions. For example, focusing on the UK, the largest effect is found in Berkshire, Buckinghamshire and Oxfordshire (UKJ1) where 2652 lives per 100,000 inhabitants were saved by the policy measures. Other areas where more than 2000 lives per 100,000 inhabitants were saved include Cheshire (UKD6), Derbyshire and Nottinghamshire (UKF1), Greater Manchester (UKD3), Inner London-East (UKI2), West Midlands (UKG3) and Essex (UKH3). The smallest impact, in turn, is found in Lincolnshire (UKF3), North Eastern Scotland (UKM5) and Dorset and Somerset (UKK2), where the lives saved are 836, 845 and 892 per 100,000 inhabitants, respectively.
6.3.2 Trade and policy cross-effects
In this paper, we are particularly interested in measuring the impact of economic links on the pandemic. Let us start by examining the weight of trade with different locations in each of the UK regions. Table 13 indicates that the largest share in trade is UK based, with intra-region and cross-UK-region trade accounting for between and of total trade. The dominance of either intra-region or inter-region trade varies widely across regions. For example, Cheshire (UKD6) shows the largest reliance on domestic trade, with occurring within the region and with flows to other UK areas. In contrast, Lincolnshire (UKF3) relies less on intra-region flows, with only , while its inter-regional trade with the rest of the UK accounts for of total trade.
Trade flows with the European Union also vary significantly across UK regions. Inner London-East and West (UKI1 and UKI2) show the largest shares of and , respectively, while Eastern Scotland (UKM2) has the lowest share at .
These results suggest that trade across regions may have had an important effect on the spread of the disease. A first assessment of this hypothesis is provided by the fourth column of results in Table 12. It gives the percentage contribution of the Geographic component in equation (46) to the generation of infected individuals, and therefore, to the number of fatalities. Recall that the geographic component collects the impact of all economic activity. Its weight in total deaths averages in the European Union and in the UK. Across UK regions, it reaches the highest values of in Inner London-East (UKI2), for Eastern Scotland (UKM2) and for Devon (UKK4). The smallest values are found in Kent (UKJ4) and North Eastern Scotland (UKM5) both with .
The distribution of the geographic component across all regions that compose our sample can be seen in Fig. 15. The regions that seem most affected by the geographic component are in Denmark, northern Germany, southern Italy, and southern Spain. While these areas are not the most heavily affected by the pandemic, it is important to note that the geographic component depends not only on trade flows, but also on the disease-transmission probability in other areas.
Geographic component
One type of effect that runs fully through the geographic component is the impact of a policy implemented in one region on the prevalence of the disease in a different region. In the next set of experiments, we examine the policy cross-effects between the EU27 and the UK. We first consider the impact of maintaining constant in the EU27 but allowing it to vary in the UK. As before, this constant value equals the region-specific average over the first ten days of virus incidence. This will give us an idea of the impact of the applied European Union anti-COVID policies on UK prevalence. The first three columns in Table 14 provide the results of this exercise, and Fig. 16 plots the distribution across regions.
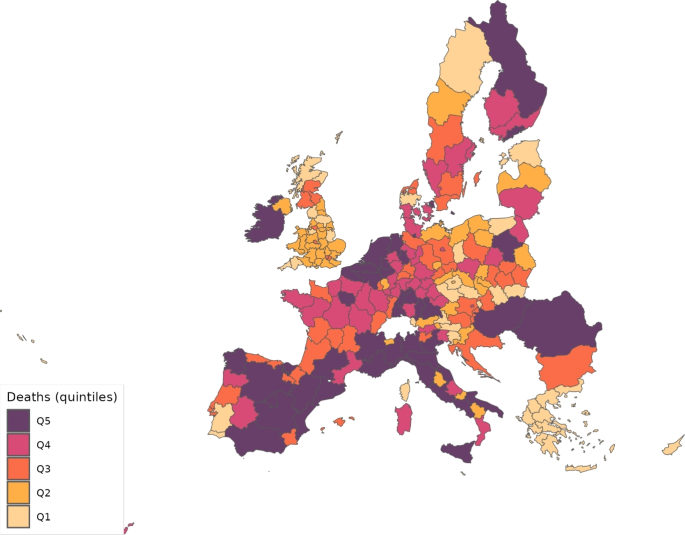
Counterfactual—predicted deaths with constant (EU27)
Without the policies implemented in the EU27, Table 14 indicates that the number of deaths in the UK would have been 83% larger. The lives saved in the UK by these policies amount to 25,398, or 36 per 100,000 inhabitants.
By region, Highlands and Islands (UKM6) benefited the most, with lived saved per 100,000 inhabitants equal to 79. Following closely, Cornwall and Isles of Scilly (UKK3), Cumbria (UKD1), Northern Ireland (UKN0), North Eastern Scotland (UKM5) and Lincolnshire (UKF3) each saved more than 50 lives. The areas that benefited the least were Greater Manchester (UKD3), West Yorkshire (UKE4), Gloucestershire, Wiltshire and Bristol/Bath area (UKK1) and West Midlands (UKG3), where the EU27 policies saved fewer than 25 lives. Nevertheless, as Fig. 16 shows, the UK regions would have suffered much less compared to the EU, since most of the regions would remain in the first or second quintiles of the distribution. However, areas of Inner London would still remain in the third quintile of the distribution.
In our second cross-effects exercise, we focus on the opposite scenario: we assume that changes in EU27 regions but remains constant in UK regions. The last three columns in Table 14 provides the results, and Fig. 17 plots the distribution across regions. They imply that UK anti-COVID measures saved 51,706 lives in the European Union, which represents 2 lives per 100,000 inhabitants. As expected, the disease would have put all regions in the UK in the upper quintiles of the distribution. Note, however, that European capitals and highly connected regions would still fall in the upper quintiles.
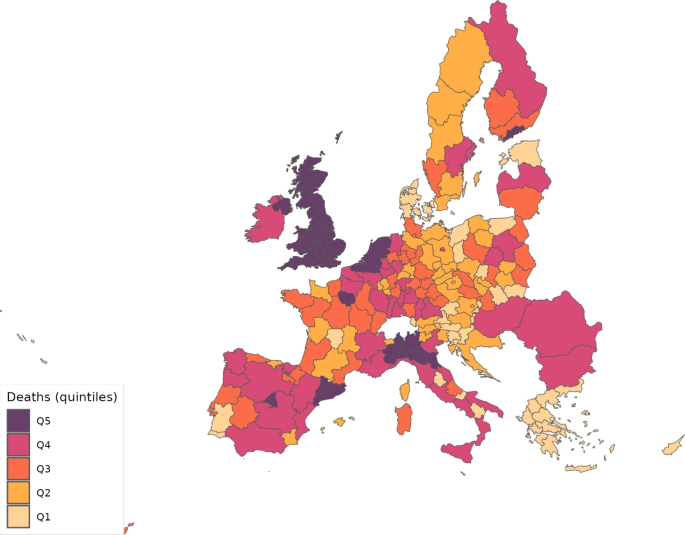
Counterfactual—predicted deaths with constant (UK)
Using predictions from this last exercise, we can also analyze the impact of the UK anti-COVID policy on UK regions. This impact is much larger than for the EU27. Specifically, they saved a total of 1,200,188 lives or 1,694 per 100,000 inhabitants. Berkshire, Buckinghamshire and Oxfordshire (UKJ1) were the most benefitted, with 2,647 lives saved per 100,000 inhabitants. It was followed by Cheshire (UKD6), Greater Manchester (UKD3), Derbyshire and Nottinghamshire (UKF1), Inner London-East (UKI2), West Midlands (UKG3) and Essex (UKH3). All of them with more than 2,000 lives saved by the fight against COVID-19 in the UK during the first wave. At the bottom of this ranking, we have Lincolnshire (UKF3), North Eastern Scotland (UKM5) and Dorset and Somerset (UKK2) with 793, 800 and 850 lives saved per 100,000 inhabitants, respectively.
Interestingly, comparing results from the last two experiments, we find that the correlation across UK regions between the lives saved by EU27 and by UK policies is significantly positive, equal to 0.66. The same correlation across EU27 regions is also substantial, equal to 0.38. These positive correlations underscore the importance of considering trade links for the effective design of infectious disease containment policies.
6.3.3 Best performing regions
In our last counterfactual, we consider how the pandemic might have evolved if all regions had followed the policies of the best performing regions. However, there is no single clear metric for determining the “best performer.” One possibility is the region that most effectively reduces the disease-transmission probability, . Another is the region that achieves the greatest reduction in the number of deaths. We will combine these two metrics to find the best performer and impose the evolution of implied by the best performing region on all European regions. Since anti-COVID policy measures were adjusted based on the reported number of daily deaths, with some places removing restrictions earlier than others, we will identify the best performers in both the first two months of the analyzed period (days 1 to 61) and the second part (days 62 to 142).Footnote19
We start by searching for the areas that most rapidly reduced the disease-transmission probability, , following its first maximum, which typically occurs on the first day with reported deaths. To compute the implied decrease, we use the ratio of the average for the first 5 days of the 2-month period to the average for the last 5 days, in order to decrease potential measurement errors. After that, we simulate the model using the implied daily reductions in from each of the top 10 areas identified by this ratio. We apply the same daily rate of decline in to all regions, starting from their calibrated region-specific value in the day when deaths from COVID-19 were first reported. Thus, the initial levels of remain unchanged, and only the speed of the decrease is altered. Finally, we calculate which reduction in results in the most lives saved.
When we focus on the first two months, Northumberland and Tyne and Wear (UKC2), a fourth-quintile-density UK region (see Fig. 1), ranks first according to this ratio, reducing in 61 days to 11.5% of its initial value. It is followed by the Netherlands (NL), which reduced it to 12.9% of the initial value. Within the ten best performers, we find five UK regions, further emphasizing that the UK was more effective in the fight against COVID that other European countries. However, within the top 10 regions, we find Oberbayern (DE21), a fourth-quintile-density region in Germany. The evolution of in Oberbayern, which decreased to 18.0% of the initial value, is actually the one that results in the most lives saved in Europe in our simulations, thus representing our chosen most effective region in the fight against COVID-19.
When we focus on the period from day 62 to 142, interestingly, the ten areas that performed better in the first 61 days no longer appear among the top 10 performers. Additionally, we find now only three UK regions in this top 10, suggesting that the UK may have lifted restrictions too early. Nevertheless, South Yorkshire (UKE3), a top-quintile-density UK region, is the best performer, with on day 142 at 35.9% of its value on day 62 after its peak. It is followed by Toscana (ITI1) in Italy, with a reduction to 36.1%. South Yorkshire (UKE3) performs the best in terms of the ratio and also the implied prevented deaths.
Therefore, we apply the daily reduction ratio implied by Oberbayern (DE21) from day 1 to day 61 of reported deaths, and the daily reduction ratio implied by South Yorkshire (UKE3) from day 62 to the end of the first wave, to the of each European region in our sample. Results are contained in Table 15 and Fig. 18. Table 15 indicates that the European Union implemented the policies followed by the best performers, and 37% of deaths could have been saved, which amount to a total of 38,883 saved lives.Footnote20 For the UK, the percentage reduction of deaths would have been slightly higher, a 42%, due to the larger incidence of the disease, and the total number of lives saved would equal 12,752.
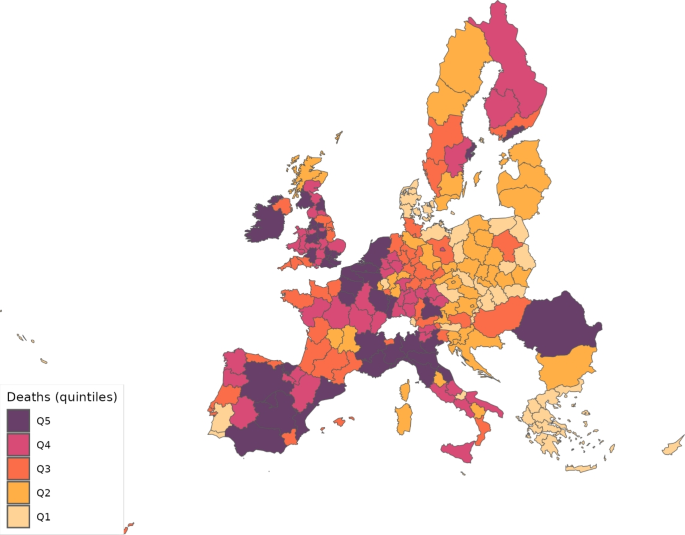
Counterfactual—predicted deaths with best regions
Across UK regions, Northern Ireland (UKN0), East Yorkshire and Northern Lincolnshire (UKE1) and North Eastern Scotland (UKM5) would have experienced the most lives saved, with 63%, 63% and 60% fewer deaths, respectively. In contrast, Northumberland and Tyne and Wear (UKC2), Merseyside (UKD7) and Inner London-East (UKI2), with reductions to 30%, 27% and 27%, respectively, would have experienced the smallest percentage of lives saved.
7 Conclusion
We have built a spatial model of trade with supply-chain links across NUTS2 European regions to try to understand the effect of economic links and policies in the spread of the COVID-19 pandemic during the first wave, which goes from February 25 to July 15, 2020. We have primarily focused on this effect within the UK in comparison with the rest of NUTS2 regions in the EU.
During that period, the incidence of the disease was larger in the UK than in the European Union. However, we find that the efforts to reduce infection rates were more successful in the UK than in the European Union. More importantly, without the policy reaction in Europe, the number of deaths during the first wave of the pandemic would have been about 4,410,000 larger in the European Union and about 1,210,000 higher in the UK.
In terms of the lives saved per 100,000 inhabitants, the average for the EU27 and the UK equals 201 and 1,713, respectively. On average, the largest gains were in areas where the volume of deaths was higher, like Berkshire, Buckinghamshire and Oxfordshire, Cheshire, Greater Manchester, Inner London-East, West Midlands and Essex. However, these regions still remain in the upper quintiles of the distribution of deaths.
Our analysis reveals that, on average, the percentage contribution of the geographic component, which reflects the impact of economic activity, accounts for of COVID-19 fatalities. Hence, while social interaction represents the primary channel through which policy impacted disease transmission, the importance of economic activity on the deaths caused by the pandemic is also significant. This channel is particularly important for regions with substantial economic interactions with other regions, even if they do not have high internal infection rates.
Another interesting finding we report is that the number of deaths in the UK in the absence of anti-COVID-19 measures in the European Union would have been 83% larger; specifically, they saved about 36 lives per 100,000 inhabitants in the UK. In turn, UK anti-COVID-19 measures saved 51,706 lives in the European Union, which represents 2 lives per 100,000 inhabitants. This asymmetric difference is in part due to the asymmetric trade intensity across regions.
Finally, we have identified Oberbayern in Germany as the single most effective region in the fight against COVID-19 during the first two months after deaths due to COVID were reported. However, due to policy adjustments that occurred throughout the pandemic, South Yorkshire in the UK was the most effective region at keeping the disease-transmission probability low and further reducing it after these initial two months. Furthermore, if all European regions had applied the anti-COVID policies implemented by these two best performers, 37% of deaths could have been prevented in the European Union and 42% in the UK, amounting to a total of 51,635 fewer deaths in Europe.
Notes
-
Compared to the sectoral structure presented by Caliendo and Parro (2015), the main difference with ours is that we consider that final consumption products can be cross-regional borders. The reason is that some of them, like tourism, can be important for the propagation of the virus and are tradable.
-
Wilson (2010) surveys the literature on the links between geography and infectious diseases and notes that socioeconomic conditions, public health infrastructure, urban versus rural environments, density and mobility of the population are important factors explaining the types and abundance. In the context of COVID-19 across the USA, Desmet and Wacziarg (2021) document spatial factors such as population density and distance to major airports that can explain the spatial variation in COVID-19 severity.
-
Several papers have highlighted the significance of infectious diseases in developing countries. In one such contribution, Chakraborty et al. (2010) introduce rational disease behavior in a general equilibrium framework, focusing on the effects of the burden of malaria and the HIV infection on economic development. They show that these diseases can create economic growth traps. In developed nations, similar evidence arises. For instance, focusing on European pandemics going back to the 14th century, Jordà et al. (2022) find important long-run economic consequences even after 40 years.
-
In the case of COVID-19, virus transmission through transportation primarily occurs from one human to another, as the main mode of transmission is through respiratory means. However, although limited, there has been some evidence suggesting the potential for COVID-19 transmission from products to humans, particularly from frozen foods. For example, Liu et al. (2020) found COVID-19 particles in imported frozen products close to entering the distribution network in Qingdao, China.
-
Another difference in our model is that deaths represent a labor supply shock. However, its impact is minor given the relatively low proportion of deaths attributed to COVID-19 compared to the total population. Importantly, our main focus is not on how production is directly affected by the pandemic, but rather on understanding the impact of trade links and disease containment policies on the spread of the COVID-19 pandemic. More significant labor supply shocks stemming from the pandemic include lockdowns (which we also consider as a consequence of mobility restrictions) and social distancing policies; see Brodeur et al. (2021), Section 5.1, for a review of the literature.
-
Resolving cases are infected individuals that cannot infect other people. Fernández-Villaverde and Jones (2022) suggest that distinguishing between infection and recovery periods matters for the model to fit the data well with biologically sensible parameters.
-
The assumption of a unitary elasticity of substitution in consumption might seem restrictive at first. However, it is worth pointing out that consumption in our framework denotes consumption of gross output, that is, final consumption expenditure. Herrendorf et al. (2013) estimate an elasticity of substitution in the range of 0.85–0.89, but also show that an elasticity of 1 can fit aggregate consumption shares as good as a CES. As the number of sector increases, our assumption of a unitary elasticity becomes more credible.
-
In order to derive (9), notice that the indirect utiity functions for working () and non-working () individuals are, respectively,
Defining as total welfare in a location, is given by
which, substituting each of the indirect utility functions, and recalling that and that represents the fraction of working individuals in a location g, we get Eq. (9).
-
Costinot and Rodríguez-Clare (2014) named this approach exact hat-algebra.
-
We assume that the geographic component only operates while working. This can be seen as a restrictive assumption, as tourists, for example, can also spread the disease while walking in the streets. For simplicity, we abstract from these considerations. As a result, the contribution of the trade component may be underestimated.
-
It can be shown that the basic reproduction number of the disease, , increases in our setup with the level of trade integration between two regions, represented by ; see Appendix A for the details. The basic reproduction number represents the average number of secondary infections produced by a typical case of infection in a population where everyone is susceptible.
-
To better realize that and serve as weighting factors, notice that if, for example, , and for all i, then Eq. (46) implies that .
-
Due to the large number of observations, these and other parameter and variable values are not reported in the paper. They are available from the authors upon request.
-
For the calibration of the disease parameters and initial values, ROW was assumed to be composed by China, the USA, and Switzerland. This means that for both the EU27 and the UK, we consider at least 70% of the trade volumes with other areas.
-
This problem could be partially solved through singular value decomposition and applying a least-squares method. However, the gap between predicted and actual deaths was always significantly worse when using this alternative procedure.
-
The impact of the productive lockdown during the pandemic varies substantially across industries and locations. As Fana et al. (2020) argues, countries primarily regulated these lockdowns by distinguishing between essential and not essential activities. Activities identified as essential, such as health, food, security, education, and administrative services, generally continued to operate. In contrast, non-essential activities faced varying degrees of closure during lockdown periods.
-
Recall that Fig. 10 depicts average values of the parameter across NUTS2 regions. Its continuous rise over the first month is a consequence of a sequence of additional regions being affected by the pandemic.
-
While its impact on policy seems limited, Sect. 6.3.2 demonstrates that the geographic component made a substantial contribution to the overall spread of the pandemic.
-
142 is the total number of days in our sample.
-
Under the policies implemented by the best performer, the three European regions that would have saved the most lives are all Polish. Lódzkie (PL11), Lubelskie (PL31), and Podlaskie (PL34) would have achieved life-saving rates exceeding 86% of the lives lost to COVID-19. These numbers, however, are not displayed in Table 15.
-
Allowing for different and across regions does not change the result of and are positive. However, the expression for the basic reproduction number is substantially more involved.
-
Notice that the timing convention does not have any important implication for our previous discussion. It would simply mean, for example, that when the susceptible is infected by the virus or vaccinated during period t, it does not develop the disease or gets immunity until period ; and that, since is then the number of workers available at the end of period t, all the economic activity takes place at the end of each period.
References
-
Acemoglu D, Chernozhukov V, Werning I, Whinston MD (2021) Optimal targeted lockdowns in a multigroup SIR model. Am Econ Rev Insights 3:487–502
-
Adda J (2016) Economic activity and the spread of viral diseases: evidence from high frequency data *. Q J Econ 131:891–941
-
Allen T, Arkolakis C (2014) Trade and the topography of the spatial economy. Q J Econ 129:1085–1140
-
Alvarez F, Argente D, Lippi F (2021) A simple planning problem for COVID-19 lock-down. Test Tracing Am Econ Rev Insights 3:367–82
-
Antràs P, Redding SJ, Rossi-Hansberg E (2023) Globalization and pandemics. Am Econ Rev 113:939–81
-
Bajunirwe F, Izudi J, Asiimwe S (2020) Long-distance truck drivers and the increasing risk of COVID-19 spread in Uganda. Int J Infect Dis 98:191–193
-
Baker SR, Bloom N, Davis SJ, Terry SJ (2020) COVID-induced economic uncertainty, working paper 26983. National Bureau of Economic Research
-
Bernardes-Souza B, Júnior SRC, Santos CA, Neto RMDN, Bottega FDC, Godoy DC, Freitas BL, Silva DLG, Brinker TJ, Nascimento RA, Tupinambás U, Reis AB, Coura-Vital W (2021) Logistics workers are a key factor for SARS-CoV-2 spread in Brazilian small towns: case–control study. JMIR Public Health Surveill 7:e30406
-
Bonadio B, Huo Z, Levchenko AA, Pandalai-Nayar N (2021) Global supply chains in the pandemic. J Int Econ 133:103534
-
Bontempi E, Coccia M, Vergalli S, Zanoletti A (2021) Can commercial trade represent the main indicator of the COVID-19 diffusion due to human-to-human interactions? A comparative analysis between Italy, France, and Spain. Environ Res 201:111529
-
Brodeur A, Gray D, Islam A, Bhuiyan S (2021) A literature review of the economics of COVID-19. J Econ Surv 35:1007–1044
-
Calatayud A, Bedoya-Maya F, Sánchez González S, Giraldez F (2022) Containing the spatial spread of COVID-19 through the trucking network. Transp Policy 115:4–13
-
Caliendo L, Parro F (2015) Estimates of the trade and welfare effects of NAFTA. Rev Econ Stud 82:1–44
-
Caliendo L, Parro F, Rossi-Hansberg E, Sarte P-D (2017) The impact of regional and sectoral productivity changes on the U.S. Econ Rev Econ Stud 85:2042–2096
-
Çakmaklı C, Demiralp S, Kalemli-Özcan c, Yeşiltaş S, Yıldırım MA (2021) The economic case for global vaccinations: an epidemiological model with international production networks, working paper 28395. National Bureau of Economic Research
-
Chakraborty S, Papageorgiou C, rez Sebastián FP (2010) Diseases, infection dynamics, and development. J Monet Econ 57:859–872
-
Costinot A, Rodríguez-Clare A (2014) Chapter 4 – trade theory with numbers: quantifying the consequences of globalization, in handbook of international economics. In: Gopinath G, Helpman E, Rogoff K (eds) Volume of 4 of handbook of international economics. Elsevier, Amsterdam, pp 197–261
-
Cuñat A, Zymek R (2022) The (structural) gravity of epidemics. Eur Econ Rev 144:104082
-
de Vet JM, Nigohosyan D, Ferrer JN, Gross A-K, Kuehl S, Flickenschild M (2021) Impacts of the COVID-19 pandemic on EU industries, Publication for the committee on industry, research and energy, policy department for economic, scientific and quality of life policies. European Parliament, Luxembourg
-
Desmet K, Wacziarg R (2021) JUE Insight: understanding spatial variation in COVID-19 across the United States. J Urban Econ 127:103332
-
Dingel JI, Neiman B (2020) How many jobs can be done at home? J Public Econ 189:104235
-
Eaton J, Kortum S (2002) Technology, geography, and trade. Econometrica 70:1741–1779
-
Eichenbaum MS, Rebelo S, Trabandt M (2021) The macroeconomics of epidemics. Rev Financ Stud 34:5149–5187
-
Eppinger P, Felbermayr G, Krebs O, Kukharskyy B (2021) Decoupling global value chains, Tech. Rep. 9079. CESifo Group, Munich
-
Eurostat (2017) Globalisation patterns in EU trade and investment. Publications Office of the European Union, Luxembourg
-
Fajgelbaum PD, Khandelwal A, Kim W, Mantovani C, Schaal E (2021) Optimal lockdown in a commuting network. Am Econ Rev Insights 3:503–22
-
Fana M, Pérez ST, Fernändez-Macías E (2020) Employment impact of Covid-19 crisis: from short term effects to long terms prospects. J Ind Bus Econ 47:391–410
-
Farzanegan MR, Gholipour HF, Feizi M, Nunkoo R, Andargoli AE (2021) International tourism and outbreak of coronavirus (COVID-19): a cross-country analysis. J Travel Res 60:687–692
-
Feenstra RC, Inklaar R, Timmer MP (2015) The next generation of the penn world table. Am Econ Rev 105:3150–82
-
Fernández-Villaverde J, Jones CI (2022) Estimating and simulating a SIRD model of COVID-19 for many countries, states, and cities. J Econ Dyn Control 140:104318
-
Fogli A, Veldkamp L (2021) Germs, social networks, and growth. Rev Econ Stud 88:1074–1100
-
Giannone E, Paixão N, Pang X (2022) JUE insight: the geography of pandemic containment. J Urban Econ 127:103373
-
Glover A, Heathcote J, Krueger D, Ríos-Rull J-V (2023) Health versus wealth: on the distributional effects of controlling a pandemic. J Monet Econ 140:34–59
-
Guerrieri V, Lorenzoni G, Straub L, Werning I (2022) Macroeconomic implications of COVID-19: Can negative supply shocks cause demand shortages? Am Econ Rev 112:1437–74
-
Hale T, Angrist N, Goldszmidt R, Kira B, Petherick A, Phillips T, Webster S, Cameron-Blake E, Hallas L, Majumdar S, Tatlow H (2021) A global panel database of pandemic policies (Oxford COVID-19 Government Response Tracker). Nat Hum Behav 5:529–538
-
Heffernan J, Smith R, Wahl L (2005) Perspectives on the basic reproductive ratio. J R Soc Interface 2:281–293
-
Herrendorf B, Rogerson R, Ák Valentinyi (2013) Two perspectives on preferences and structural transformation. Am Econ Rev 103:2752–89
-
Iacus SM, Santamaria C, Sermi F, Spyratos S, Tarchi D, Vespe M (2020) Human mobility and COVID-19 initial dynamics. Nonlinear Dyn 101:1901–1919
-
Jordà O, Singh SR, Taylor AM (2022) Longer-run economic consequences of pandemics. Rev Econ Stat 104:166–175
-
Keeling MJ (1999) The effects of local spatial structure on epidemiological invasions. Proc R Soc Lond Ser B Biol Sci 266:859–867
-
Kejžar KZ, Velić A, Damijan JP (2022) COVID-19, trade collapse and GVC linkages: European experience. World Econ 45:3475–3506
-
Kermack WO, McKendrick AG, Walker GT (1927) A contribution to the mathematical theory of epidemics. Proc R Soc Lond Ser A Contain Pap Math Phys Character 115:700–721
-
Krueger D, Uhlig H, Xie T (2022) Macroeconomic dynamics and reallocation in an epidemic: evaluating the ‘Swedish solution’. Econ Policy 37:341–398
-
Lan F-Y, Wei C-F, Hsu Y-T, Christiani DC, Kales SN (2020) Work-related COVID-19 transmission in six Asian countries/areas: a follow-up study. PLoS ONE 15:e0233588
-
Liu P, Yang M, Zhao X, Guo Y, Wang L, Zhang J, Lei W, Han W, Jiang F, Liu WJ, Gao GF, Wu G (2020) Cold-chain transportation in the frozen food industry may have caused a recurrence of COVID-19 cases in destination: successful isolation of SARS-CoV-2 virus from the imported frozen cod package surface. Biosaf Health 2:199–201
-
Liu X, Ornelas E, Shi H (2022) The trade impact of the COVID-19 pandemic. World Econ 45:3751–3779
-
Lloyd AL, May RM (1996) Spatial heterogeneity in epidemic models. J Theor Biol 179:1–11
-
Martini M, Sina-Odunsi A, Dache JJ, Wekesa J, Mzozo T (2022) Epidemiological progression of COVID-19 positive cases among transnational truck drivers in the East African Region. Pan Afr Med J 41:3
-
Mayer JD (2000) Geography, ecology and emerging infectious diseases. Soc Sci Med 50:937–952
-
Oster E (2012) Routes of Infection: exports and HIV incidence in Sub-Saharan Africa. J Eur Econ Assoc 10:1025–1058
-
Paeng S-H, Lee J (2017) Continuous and discrete SIR-models with spatial distributions. J Math Biol 74:1709–1727
-
Persyn D, Diaz-Lanchas J, Barbero J, Conte A, Salotti S (2020) A new dataset of distance and time related transport costs for EU regions, Working Paper JRC119412, Territorial Development Insight Series, European Comission
-
Robin Nunkoo HKD, Gholipour HF (2022) Does domestic tourism influence COVID-19 cases and deaths? Curr Issue Tour 25:338–351
-
Sforza A, Steininger M (2020) Globalization in the Time of COVID-19. COVID Econ 19
-
Sheehan MM, Reddy AJ, Rothberg MB (2021) Reinfection rates among patients who previously tested positive for coronavirus disease 2019: a retrospective cohort study. Clin Infect Dis 73:1882–1886
-
Thiessen M (2020) RHOMOLO-IO dset 2013, Tech. rep., European Commission, Joint Research Centre (JRC), [Dataset] PID: http://data.europa.eu/89h/9559442f-a88e-484b-934d-fa4bbd5e6663
-
Thissen M, Ivanova O, Mandras C, Husby T (2019) European NUTS 2 regions: construction of interregional trade-linked Supply and Use tables with consistent transport flows, Tech. Rep. 01/2019. JRC Working Papers on Territorial Modelling and Analysis, Seville, JRC115439
-
Villani L, McKee M, Cascini F, Ricciardi W, Boccia S (2020) Comparison of deaths rates for COVID-19 across Europe during the first wave of the COVID-19 pandemic, Frontiers in Public Health, 8
-
Wilson ME (2010) Chapter 101 – Geography of infectious diseases. In: Cohen J, Opal SM, Powderly WG (eds) Infectious diseases, 3rd edn. Mosby, London, pp 1055–1064
-
World Bank (2009) World development report 2009: reshaping economic geography. The World Bank
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Additional information
Appendices
The basic reproduction number in our SVIRCF model
Following Heffernan et al. (2005), we can write the equation for infected individuals in matrix form as:
where is the identity matrix, is the vector of infections in each location at time , and and are defined as
For the two region case, these matrices are given by
Let us focus on the simplest case of two regions for which the components of do not change over time, neither the parameters regarding the disease ecology. In addition, assume that , and there is no vaccine available. Then, we have that the basic reproduction number is given by the largest eigenvalue of matrix . Matrix is given by
Furthermore, let us assume that and ,Footnote21 then the basic reproduction number is given by
which increases with trade integration, since the partial derivatives are increasing in the trade share with the opposite region.
Parameters for the evolution of the disease
In order to calibrate , we follow the method in Fernández-Villaverde and Jones (2022) and recover the parameter from deaths numbers. In addition, to ameliorate possible mismeasurement problems, like for example underreporting during weekends, we first smooth those daily deaths series using a moving average of seven days and then a Hodrick–Prescott filter with smoothing parameter 850.
This calibration method is applied to our case as follows. Let us add a time index (t) to the different variables for mathematical convenience. Additionally, let us take the convention that provides the value of an arbitrary variable Z at the end of period t, and that .Footnote22 Define also , that is, the (smoothed) number of people that died on day in region g. For the initial waves of the pandemic, in which there was no vaccine available, we assume for all regions.
From Eq. (48e), we can solve for in terms of daily deaths as
which then implies
Combining Eqs. (48c) and (55), we can express infected individuals today as a function of future daily fatalities:
which implies
Using the ratio of (57)–(56), the growth rate of the infected cases can be obtained as:
Next, equation (45), letting denote the geographic component in equation (46), delivers
We can substitute (56) and (58) in previous expression to get
To get an expression for the evolution of the susceptible as a function of the fatalities, we can use (48a), (46), and (56) to obtain the law of motion for this variable as:
Note we also need to include the law of motion for vaccinated and recovered individuals which from (48b) and substituting equation (54) into (48d) yields
Finally, we need initial values for . For the stock of fatalities, recovered and vaccinated, this value is zero, that is, . Knowing the number of fatalities in the next two periods, we then obtain and from (56) and (54); and the number of susceptible is directly obtained from (2) taking for all t from the sources reported in Table 5.
In principle, knowing those numbers, and taking the daily deaths and fraction of vaccinated from the data, we could end up with a system of equations, given by (59) to (62), and unknowns, . However, the large number of zero deaths encountered in many periods make the system indeterminate many times when the geographical component is considered. The solution that we have adopted to solve this problem is assuming in the calibration of that . In this way, the system for each region simplifies and becomes independent of other areas. Hence, for each period and region , we first recover from (59) and then from the other three equations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and permissions
About this article
Cite this article
Pérez-Sebastián, F., Serrano-Quintero, R. The economic linkages of Covid-19 across sectors and regions in Europe. SERIEs (2025). https://doi.org/10.1007/s13209-025-00305-0
- Received
- Accepted
- Published
- DOI https://doi.org/10.1007/s13209-025-00305-0
Keywords
- Spatial economics
- Covid-19
- First wave
- Policy response
- Quantitative models
JEL Classification
- E10
- I10
- R10