Article Content
1 Introduction
Simple random sampling (SRS) is the most common and straightforward method of sampling. Auxiliary information is utilized to enhance the efficiency of estimators at both the selection and estimation stages of sampling methods. Numerous authors have proposed various types of ratio, product, and regression estimators to improve efficiency by incorporating auxiliary variables (Cochran 1940; Murthy 1964; Sahai 1979; Prasad 1989; Kadilar and Cingi 2004; Kadilar et al. 2009; Ozturk 2014; Singh et al. 2016; Kusum 2022). These approaches continue to be relevant and actively employed in current research.
The exponential weighted moving average (EWMA) is a commonly used control chart in quality control to monitor sample means of a process, leveraging both past and current data to enhance estimator efficiency for population parameters. Roberts (1959) introduced the EWMA statistic to incorporate past and current information simultaneously, aiming to improve estimator efficiency. Subsequently, Haq (2013) proposed a hybrid exponentially weighted moving average (HEWMA) as an alternative, building upon the initial EWMA statistic. Noor-ul-Amin (2020) suggested using HEWMA statistics as memory-type estimators for ratio and product estimations in time-based surveys. Extending this work, Aslam et al. (2020, 2021) applied memory-type ratio and product estimators to stratified and ranked-based sampling schemes using EWMA. Noor-ul-Amin (2021) introduced another estimator using HEWMA for time-scaled surveys. Singh et al. (2021) investigated memory-type shrinkage estimators of population means within quality control processes. Chhaparwal and Kumar (2022) focused on enhancing the efficiencies of ratio and product-type estimators by incorporating a coefficient of variation. Qureshi et al. (2024) proposed memory-type ratio and product estimators for population variance utilizing EWMA. Bhushan et al. (2022) evaluated the performance of memory-type logarithmic estimators under SRS. This topic has been the subject of frequent studies, with many recent publications focusing on it. Notably, Shahzad et al. (2022), Alomair et al. (2023), Aslam et al. (2023), Bhushan et al. (2023), Khan et al. (2023), Zahid et al. (2023), Kumar et al. (2024), Pandey et al. (2024), Qureshi et al. (2024), and Yadav et al. (2023) have all contributed to the growing body of literature in this area.
If the sample mean of the same variable obtained from similar or older studies are available, we can include these means in the newly calculated mean to make the prediction more effective. The objective of this study is to demonstrate the utilization of past sample means in improving estimators, by employing HEWMA as a mathematical function. We also present in detail what affects the effectiveness of the new prediction made in this process. We propose novel and more efficient estimators that leverage the HEWMA statistic and assess their performance through simulations using both real and synthetic datasets. This article is structured as follows: Sect. 2 provides an overview of conventional estimators used in simple random sampling (SRS), along with a discussion on existing memory-type estimators found in the literature. In Sect. 3, we introduce the newly developed memory-type exponential ratio estimators, elucidating the procedures for calculating mean squared errors (MSEs) and biases of these proposed estimators. Furthermore, this section presents theoretical comparisons between the proposed estimator and estimators featured in previous research. Sections 4 and 5 entail the computation of relative efficiencies for the estimators, as well as a comparison of these estimators using simulations and real data sets, respectively. Finally, Sect. 6 concludes the article and suggests areas for future study.
2 Estimators in literature
Let A: (A1,A2,…,AN) be a finite population of size of N and let y and x be a study and an auxiliary variable, respectively. The literature presents several conventional estimators that rely on the current sample data. We present as estimators of the population mean that use a current sample, and shows estimators of the population mean which use current and past samples. These estimators are given respectively as SRS simple mean, SRS ratio, SRS exponential ratio, and SRS regression estimators as follows:
where n is the sample size, is the sample mean of x taken with SRS, is the population mean of x, and is the regression coefficient- slope which can be estimated on sample too, is population covariance between x and y, is the population variances of x.
Noor-ul Amin (2020) and Chhaparwal and Kumar (2022) have proposed memory type estimators that incorporate past sample means alongside the current sample as follows (in order):
where Hyt and Hxt are the control chart statistics that are calculated with y and x. The mean squared error (MSE) equations for all the estimators mentioned above are as follows:
where ρ is the correlation coefficient between x and y, and are coefficient of variations of the y and x, , and .
3 Proposed estimators
The proposed estimators utilize the HEWMA statistics for the study variable and the auxiliary variable. Specifically, the HEWMA statistic for the study variable can be represented by the following formulas:
The time parameter, denoted as t, represents the specific point in time at which the HEWMA statistic is calculated. When t = 1, it corresponds to the current observation, reflecting the most recent data. The weight parameters, ω1, and ω2, are associated with the EWMA and HEWMA statistics, respectively. These parameters control the weighting of the current and the past mean. It is important to note that both ω1, and ω2 should be within the range of 0 < ω1, ω2 ≤ 1 and the initial values of E and H should be the oldest sample mean. These values determine the relative influence of the current observation and the past statistic in the calculation of the respective statistics.
The algorithm steps of the calculation of the HEWMA are shown in Fig. 1.
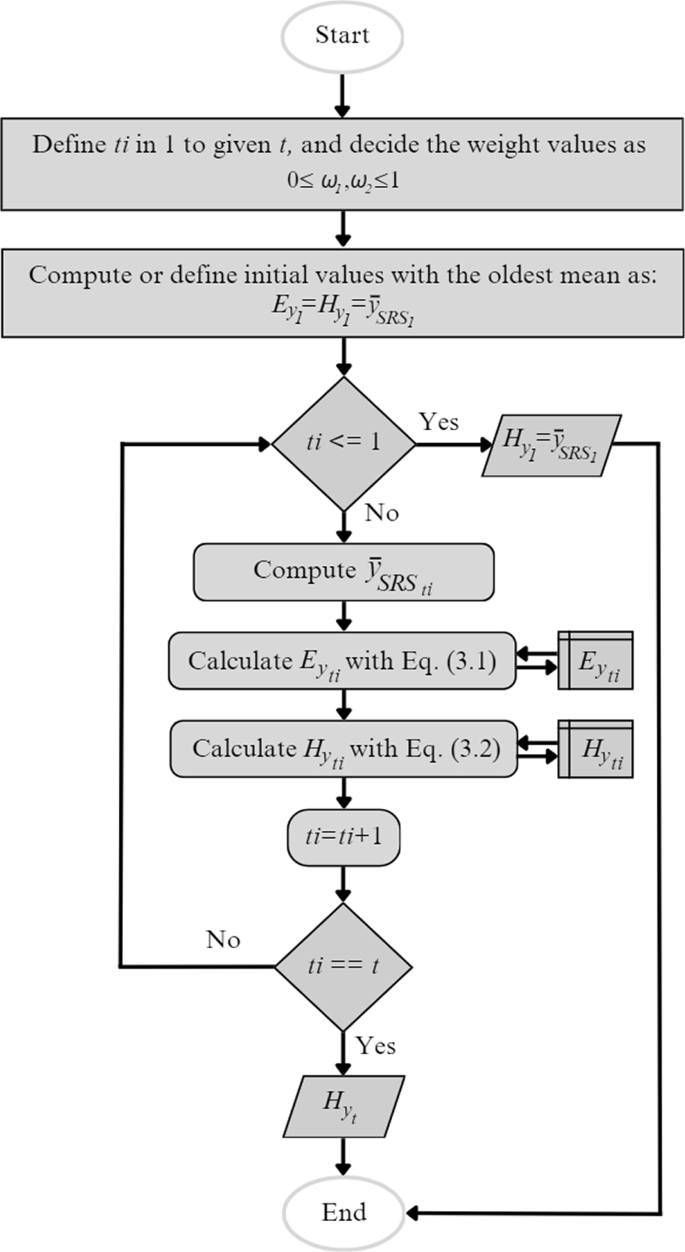
Flowchart of HEWMA on Y variable
Motivated by the effectiveness of memory-type estimators and building upon the work of Bahl and Tuteja (1991), we introduce two novel estimators that incorporate memory-type approaches to improve population mean estimation. Firstly, we present the memory-type exponential ratio estimator, which draws inspiration from the concept of exponential ratio estimation and extends it by incorporating past sample means. This estimator is formulated as follows:
In this formulation, we leverage the exponential ratio estimation technique, which has demonstrated its efficacy in capturing the relationship between the study variable and the auxiliary variable. By incorporating past sample means, our memory-type exponential ratio estimator enhances the estimation process, leading to the more accurate and precise population mean estimates. Secondly, inspired by the regression type estimator proposed by Kaur (1985), we introduce a memory-type regression estimator. This estimator combines the principles of regression estimation with the inclusion of past sample means to further improve population mean estimation. The formulation of our memory-type regression estimator is as follows:
These two novel estimators, the memory-type exponential ratio estimator and the memory-type regression estimator, offer promising advancements in population mean estimation. By integrating memory-type approaches with established estimation techniques, we aim to enhance the accuracy and precision of population mean estimation, providing researchers with more robust and reliable estimators for their analyses.
This section presents an illustrative example to demonstrate the calculation of estimators and provides a detailed explanation of the Hyt and Hxt formulas. The population used in this numerical example is sourced from Appendix 1, encompassing data from 81 cities in Turkey for the years 2018 and 2019, with 2018 serving as the past and 2019 being the current year. The study variable considered in this analysis is the number of fatalities resulting from traffic accidents in these cities, while the auxiliary variable corresponds to the number of individuals holding driver’s licenses in the same cities during the year 2019.There is a strong positive correlation between the variables (ρxy = 0.8981), and population means are = 2159.21 and = 367,493.6. For the year 2018, we have sample means = 536,646.4 and = 3506.06, obtained from the sample units in the 2018 column of Table 1. Table 1 also provides additional sample units and corresponding statistics from 2019.
The estimators , and rely solely on the sample data from the year 2019. However, the estimators , and incorporate both the sample means from 2019 and the past means and , using specified weights. In this case, we assign ω1 = 0.9 as the weight for EWMA and ω2 = 0.75 as the weight for HEWMA. The calculations for these estimators are as follows:
= = 2775.6, = / = 2991.823,
= exp(–/ + ) = 2881.633,
= + b (–) = 3035.912 where b = ρxysy/sx = 0.0098,
,.
,
= Hy2019/ Hx2019 = 2737.233, = Hy2019 ( + Cx /Hx2019 + Cx) = 2737.234 where Cx = Sx2019/ = 0.8145, = Hy2019 exp(Hx2019–/ Hx2019 + ) = 2871.998,
= Hy2019 + b(Hx2019 –) = 2650.068 where b is the same with in and it’s 0.0098.
To derive the bias and MSE equations of the proposed estimators, we express and as Noor-ul Amin (2020) in the Eqs. (3.5) and (3.6) such that,, , , and . By considering these assumptions, the proposed estimators can be expressed in linear form as:
By subtracting from both sides of Eqs. (3.7) and (3.8), and taking the expected value, we obtain:
Equation (3.10) shows that the proposed memory-type regression estimator is unbiased, similar to SRS regression type estimator. When squaring of Eqs. (3.9) and (3.10), we obtain MSE and variance of the proposed estimators, respectively, as,
To find the optimal value of slope coefficient b, we can derive Eq. (3.12) and set it to zero:
which is the same slope coefficient in regression estimator, and it can be estimated on sample as with sample standard deviations. When we substitute Eq. (3.13) into Eq. (3.12), we can obtain the minimum variance of the unbiased memory–type regression estimator as:
where and details are given in Appendix 2. If Eqs. (3.15) to (3.16) are met, the proposed memory type exponential ratio estimator is more efficient than other mean estimators of SRS and the proposed memory type regression estimator is always more efficient than the other memory-type ratio estimators in the literature. When comparing the proposed estimators with each other:
4 Simulation studies
4.1 Simulation with synthetic data
For the simulation study, correlations between the variables are derived as ρxy = 0.65, 0.75, and 0.85 from the bivariate N(5,1) to represent the symmetrical distribution, Exp(1) for the right-skewed, and Beta (4,1) for the left-skewed distribution. Logically, it is unlikely that a similar study could have been repeated many times in the past. However, in addition to the current study, obtaining the mean of 1 or 2 samples from the past is more feasible. Therefore, for both the simulation and real data studies, values of t = 2 and t = 3 are chosen to observe the impact of increasing the number of past sample means. These determined values are more plausible and sufficient to observe changes when the number of the past sample means increases. In the simulation study, we consider past sample size and current sample size to be equal, and simple random sampling without replacement (SRSWOR) samples with a size of ni = 10, 50, 100, and 500 are drawn from the artificial populations, which are N = 1000, with a number of simulations of 100,000, and estimators are calculated. Since for small values of ω1 that are 0.05 < ω1 < 0.25, the EWMA statistic works well in practice for Montgomery (2009), in Table 2, it is kept constant as ω1 = 0.1 and calculated as ω2 = 0.05, 0.1, 0.25, 0.5, 0.75. Then we change it to ω1 = 0.15 in Table 3 and ω1 = 0.9 in Table 4 to observe whether the claim, which works for control charts, also works for estimation. The MSE values of the estimators are calculated with Eq. (4.1), and the RE values obtained with Eq. (4.2). The reference variable for the RE comparison is taken as the SRS simple mean estimator , and the results of the normal distribution are given in Tables 2, 3, and 4. Beta and exponential distribution results are given in Appendix 3, and 4. The most efficient estimators are written in bold in the tables.
Here are the steps outlining our simulation methodology:
- 1.Generate synthetic data from the bivariate distribution using either the given population parameters or random parameters, with ρxy of size N.
- 2.Select a SRSWOR of size n from the population.
- 3.Calculate EWMA for Y variable with Eq. (3.1) using sample mean, the ω1 parameter, and sample of y.
- 4.Calculate HEWMA for Y with Eq. (3.2) with the ω2 parameter and the EWMA found in Step 3.
- 5.Repeat steps 3 and 4 on X variable with Eqs. (3.3) and Eq. (3.4).
- 6.Repeat Step 2 to 5 for t times.
- 7.Calculate the estimators and all estimates with Eq. (2.1) to (2.6), Eq. (3.5) and Eq. (3.6) by substituting the calculated HEMMA values obtained in Steps 4, and 5 into the estimator.
- 8.Calculate MSE using the estimate calculated in Step 6 and the population parameter derived in Step 1.
- 9.Repeat Steps 2–9 as many times as the number of simulations.
- 10.Take the average of the MSEs obtained as many times as the number of simulations with Eq. (4.1)
- 11.Calculate RE using the obtained MSE averages with Eq. (4.2).
R codes and generated synthetic datasets are available at: https://github.com/EdaGKocyigit/simulationcode.git
In the case of a small sample size, it is observed that the first proposed estimator yields the best results for low to moderate correlations. However, when the correlation is sufficiently high, the estimator proves to be more suitable for both t = 2 and t = 3. Additionally, under normal distribution, the estimator consistently outperforms other estimators for all values of ω1 and ω2. Furthermore, the impact of distribution changes is found to be insignificant, as demonstrated in Fig. 1. This indicates that the proposed estimators are robust across different distributions. Figure 2 illustrates the case where ω1 = 0.9, and it is observed that the proposed estimator achieves the best results when ρxy = 0.75. Thus, increasing the number of past sample means used and selecting ω2 = 0.5 enhance the efficiency of both proposed estimators.
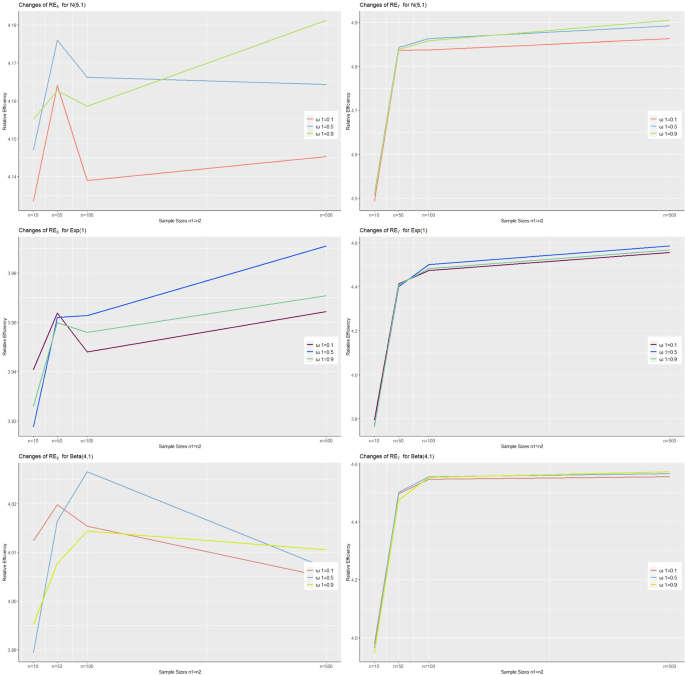
Variation of RE6t and RE7t for different distributions and sample sizes (n1 = n2) when ρxy = 0.75 and ω2 = 0.5
4.2 Simulation with real data
In this section, two distinct real datasets with different properties are utilized. The first dataset is derived from the population described in the previous numerical example, which is presented in detail in Appendix 1. Figure 3 illustrates the distributions of the Y variables within these populations. The key parameters associated with Population I are summarized as follows:
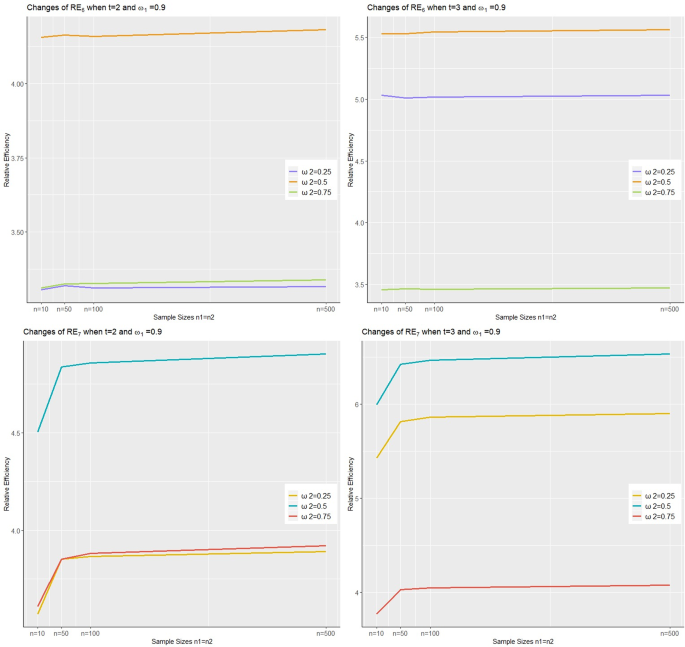
Variation of RE6t and RE7t according to ω2 for t = 2, and 3 when ρxy = 0.75 and and ω1 = 0.9
Population I-Y: The number of people who died in traffic accidents in cities of Turkey in 2019, X: The number of people who have driver’s licenses in the same cities and year. N = 81, ρxy = 0.8981, 2159.21, 367,493.6, = 2682.28, = 748,915.3. For theoretical comparisons given in Sect. 3, in Population I, κ = 0.5475 and α = 0.9999. Then we expect: RE6t < RE4t, because of κ < 0.75 from Eq. (3.15); RE6t < RE5t as a result of κ < 0.74995 from Eq. (3.16), and RE7t < RE6t because 0.7523 > 0 from Eq. (3.19).
For t = 2, sample sizes (n1 and n2) are chosen as all binary combinations of 10, 20, and 30. When t = 3, all combinations of sample sizes (n1, n2, and n3) 10, 20, and 30 are evaluated. The number of the simulation is 200,000 for all datasets. The MSE and RE values are computed using the same methodology as described in the previous section. The steps outlining the simulation methodology for real data remain the same as before, with the exception of the first two steps.
Step 1: Utilize either the provided data in Appendix 1 or 5 as the population.
Step 2: For t = 3, use 2017 data as the initial dataset; for t = 2, use 2018 data as the initial dataset; and for both current population is 2019, select a SRSWOR of size n from the populations.
The results for Population I with t = 2 are presented in Table 5, while the results for Population I with t = 3 are shown in Table 6.
Population II, as described in Appendix 5, is characterized by the following parameters. It should be noted that the calculations and methodology used for Population I are also applied to Population II, but in this case, only the scenario with t = 2 is considered.
Population II- Y: The number of people who died in traffic accidents in cities of Turkey in 2018, X: The number of motor vehicles registered to traffic in the same cities and year. N = 81, ρxy = 0.788, 2302.864, 11,151.53, = 2766.201, = 37,032.75. Theoretical comparisons for this population, κ = 0.28503 and α = 0,9997. Then we expect: RE6t < RE4t, because of κ < 0.75 from Eq. (3.15); RE6t < RE5t as a result of κ < 0,74,985 from Eq. (3.16), and RE7t < RE6t because 0.7962 > 0 from Eq. (3.19). RE results of the Population II and t = 2 is given in Table 7.
5 Discussion
This study introduces two innovative and more efficient memory-type estimators that integrate past and current sample means using HEWMA statistics. These estimators address limitations in existing methods by enhancing accuracy and applicability. Through comprehensive simulation studies and real data examples, the research evaluates the performance of these new estimators, highlighting significant improvements over previous memory-type approaches. Key findings underscore the importance of parameter selection in HEWMA, the significant impact of past sample sizes, the number of past samples, and the mathematical function of the estimator on its efficiency. Additionally, the fact that the initial value of the EWMA and HEWMA algorithms is based solely on sample statistics is the most useful aspect of this study. Notably, the study reveals that appropriately chosen weight parameters, high correlation between the study and auxiliary variables, a greater number of past means, and larger past sample sizes enhance the efficiency of the proposed estimators.
From Table 6, it’s evident that there are instances where the SRS exponential ratio type estimator () and simple regression type estimator () using only current sample mean outperform the memory-type ratio estimators ( and ) in the literature. This situation emphasizes the significance of the function (estimator) used and indicates the superiority of the exponential ratio type and regression type estimators over the ratio type estimator.
Interestingly, we discovered that sample sizes based on past means, from Tables 5, 6, 7, a point not previously emphasized in the literature, significantly impact RE. When the sample size of past means exceeds the current sample size, the efficiency of the proposed estimators improves, making the use of HEWMA statistics sensible. Even if past sample sizes are not large enough, increasing the weights (ω1 and ω2) assigned to the current sample can enhance the efficiency of the proposed estimators. Moreover, increasing the number of past sample means used correlates with increased efficiency of the proposed estimators.
Our analysis demonstrates that the proposed estimator outperforms all estimators in the literature, both in simulation and real data sets, when ω1 and ω2 are appropriately chosen based on sample sizes of means. Contrary to Montgomery (2009), selecting ω2 larger than 0.5 enhances the efficiency of the proposed estimators. In Table 5, if the sample size of the past mean is considerably smaller than the sample size of the current sample, it would be beneficial to choose larger both ω1 and ω2 values. Additionally, from Fig. 2, it is evident that the proposed estimators do not significantly affect the distribution shape. However, as Table 7 illustrates, the estimator may not yield good results with real data in all cases. Therefore, it can be concluded that , one of the proposed estimators, is more effective than . Overall, based on the entire study, emerges as the most effective estimator (Fig. 4).

Distributions of the Y in years
In real data applications, we observed that theoretical results do not always perfectly align with reality. Additionally, the sample sizes of past samples used influence the choice among the proposed estimators. In this regard, it’s imperative to revise the E(e02), E(e12), and E(e0e1) formulas of memory-type estimators in the literature to include information about past means. While the proposed method offers the most striking advantage of making the most efficient estimations by utilizing only past statistics alongside a current sample, its most significant disadvantage lies in the uncertainty surrounding the weight values employed in the method. A secondary disadvantage is the necessity for information regarding the number of sample sizes used to calculate past means.
For future studies, exploring the effectiveness of the proposed estimators in alternative sampling methods such as ranked set sampling, systematic sampling, cluster sampling, etc., holds promise. Additionally, developing the given estimators with statistics more effective than the HEWMA statistic, or employing different mathematical expressions as estimators, could open new avenues for investigation. Moreover, investigating optimal values for the weight parameters ω1 and ω2 in HEWMA using various techniques, or exploring the utilization of moving weight parameters, would be noteworthy areas for further research. Furthermore, integrating the proposed estimator into optimization algorithms instead of the simple mean may lead to more remarkable results. Lastly, rearranging, examining, and utilizing the proposed mean estimators as total estimates could offer valuable insights.